 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Unit Test via Adversarial Reinforcement Learning
Aug 28, 2025



Unit testing is a core practice in programming, enabling systematic evaluation of programs produced by human developers or large language models (LLMs). Given the challenges in writing comprehensive unit tests, LLMs have been employed to automate test generation, yet methods for training LLMs to produce high-quality tests remain underexplored. In this work, we propose UTRL, a novel reinforcement learning framework that trains an LLM to generate high-quality unit tests given a programming instruction. Our key idea is to iteratively train two LLMs, the unit test generator and the code generator, in an adversarial manner via reinforcement learning. The unit test generator is trained to maximize a discrimination reward, which reflects its ability to produce tests that expose faults in the code generator's solutions, and the code generator is trained to maximize a code reward, which reflects its ability to produce solutions that pass the unit tests generated by the test generator. In our experiments, we demonstrate that unit tests generated by Qwen3-4B trained via UTRL show higher quality compared to unit tests generated by the same model trained via supervised fine-tuning on human-written ground-truth unit tests, yielding code evaluations that more closely align with those induced by the ground-truth tests. Moreover, Qwen3-4B trained with UTRL outperforms frontier models such as GPT-4.1 in generating high-quality unit tests, highlighting the effectiveness of UTRL in training LLMs for this task.
MSCCL++: Rethinking GPU Communication Abstractions for Cutting-edge AI Applications
Apr 11, 2025

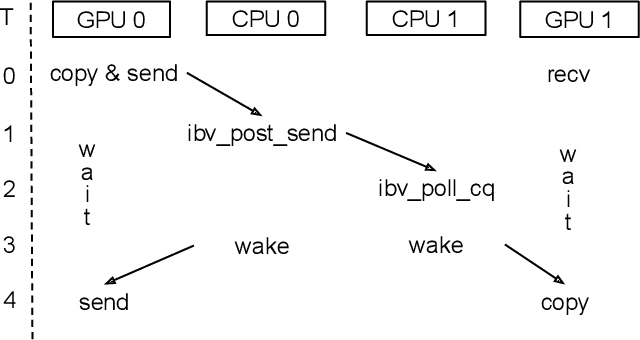
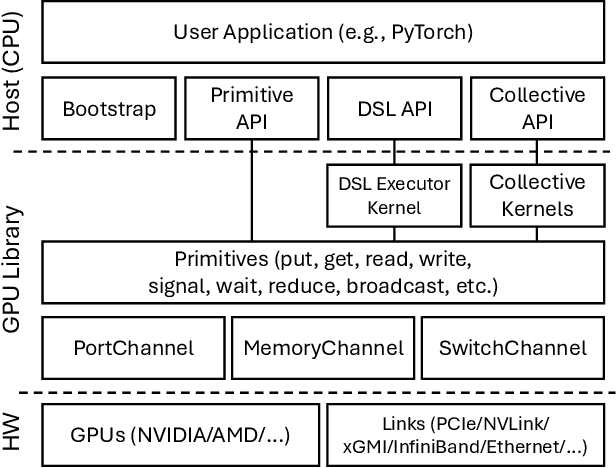
Modern cutting-edge AI applications are being developed over fast-evolving, heterogeneous, nascent hardware devices. This requires frequent reworking of the AI software stack to adopt bottom-up changes from new hardware, which takes time for general-purpose software libraries. Consequently, real applications often develop custom software stacks optimized for their specific workloads and hardware. Custom stacks help quick development and optimization, but incur a lot of redundant efforts across applications in writing non-portable code. This paper discusses an alternative communication library interface for AI applications that offers both portability and performance by reducing redundant efforts while maintaining flexibility for customization. We present MSCCL++, a novel abstraction of GPU communication based on separation of concerns: (1) a primitive interface provides a minimal hardware abstraction as a common ground for software and hardware developers to write custom communication, and (2) higher-level portable interfaces and specialized implementations enable optimization for different hardware environments. This approach makes the primitive interface reusable across applications while enabling highly flexible optimization. Compared to state-of-the-art baselines (NCCL, RCCL, and MSCCL), MSCCL++ achieves speedups of up to 3.8$\times$ for collective communication and up to 15\% for real-world AI inference workloads. MSCCL++ is in production of multiple AI services provided by Microsoft Azure, and is also adopted by RCCL, the GPU collective communication library maintained by AMD. MSCCL++ is open-source and available at https://github.com/microsoft/mscclpp.
Alchemist: Towards the Design of Efficient Online Continual Learning System
Mar 03, 2025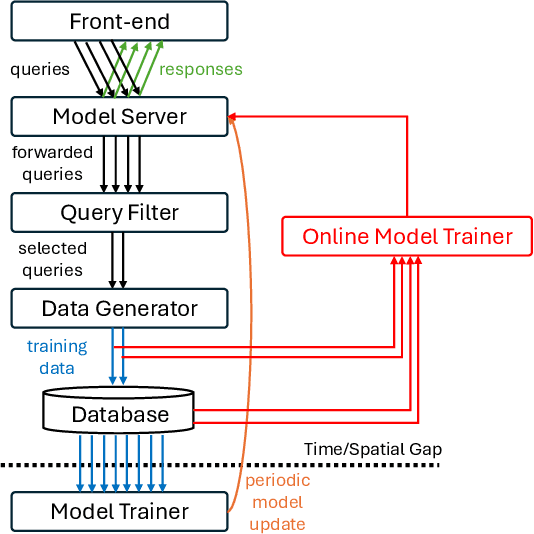
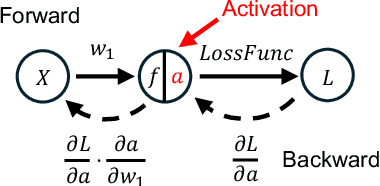
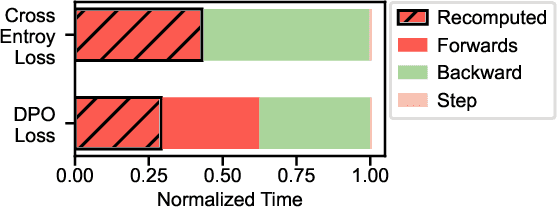
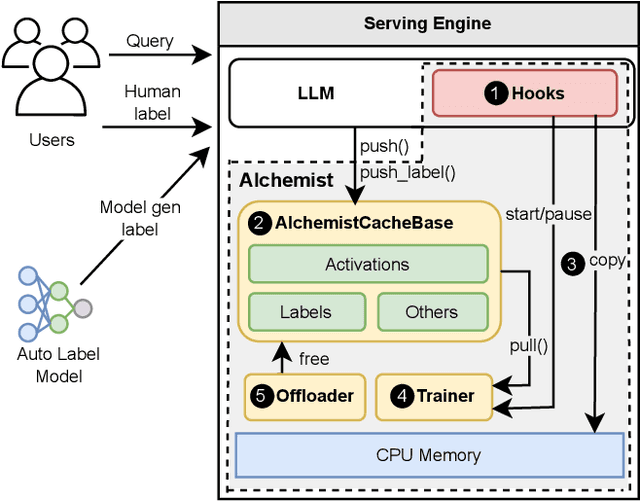
Continual learning has emerged as a promising solution to refine models incrementally by leveraging user feedback, thereby enhancing model performance in applications like code completion, personal assistants, and chat interfaces. In particular, online continual learning - iteratively training the model with small batches of user feedback - has demonstrated notable performance improvements. However, the existing practice of segregating training and serving processes forces the online trainer to recompute the intermediate results already done during serving. Such redundant computations can account for 30%-42% of total training time. In this paper, we propose Alchemist, to the best of our knowledge, the first online continual learning system that efficiently reuses intermediate results computed during serving to reduce redundant computation with minimal impact on the serving latency or capacity. Alchemist introduces two key techniques: (1) minimal activations recording and saving during serving, where activations are recorded and saved only during the prefill phase to minimize overhead; and (2) offloading of serving activations, which dynamically manages GPU memory by freeing activations in the forward order, while reloading them in the backward order during the backward pass. Evaluations with the ShareGPT dataset show that compared with a separate training cluster, Alchemist significantly increases training throughput by up to 1.72x, reduces up to 47% memory usage during training, and supports up to 2x more training tokens - all while maintaining negligible impact on serving latency.
ForestColl: Efficient Collective Communications on Heterogeneous Network Fabrics
Feb 09, 2024



As modern DNN models grow ever larger, collective communications between the accelerators (allreduce, etc.) emerge as a significant performance bottleneck. Designing efficient communication schedules is challenging given today's highly diverse and heterogeneous network fabrics. In this paper, we present ForestColl, a tool that generates efficient schedules for any network topology. ForestColl constructs broadcast/aggregation spanning trees as the communication schedule, achieving theoretically minimum network congestion. Its schedule generation runs in strongly polynomial time and is highly scalable. ForestColl supports any network fabrics, including both switching fabrics and direct connections, as well as any network graph structure. We evaluated ForestColl on multi-cluster AMD MI250 and NVIDIA A100 platforms. ForestColl's schedules achieved up to 52\% higher performance compared to the vendors' own optimized communication libraries, RCCL and NCCL. ForestColl also outperforms other state-of-the-art schedule generation techniques with both up to 61\% more efficient generated schedules and orders of magnitude faster schedule generation speed.
Pre-gated MoE: An Algorithm-System Co-Design for Fast and Scalable Mixture-of-Expert Inference
Aug 23, 2023Large language models (LLMs) based on transformers have made significant strides in recent years, the success of which is driven by scaling up their model size. Despite their high algorithmic performance, the computational and memory requirements of LLMs present unprecedented challenges. To tackle the high compute requirements of LLMs, the Mixture-of-Experts (MoE) architecture was introduced which is able to scale its model size without proportionally scaling up its computational requirements. Unfortunately, MoE's high memory demands and dynamic activation of sparse experts restrict its applicability to real-world problems. Previous solutions that offload MoE's memory-hungry expert parameters to CPU memory fall short because the latency to migrate activated experts from CPU to GPU incurs high performance overhead. Our proposed Pre-gated MoE system effectively tackles the compute and memory challenges of conventional MoE architectures using our algorithm-system co-design. Pre-gated MoE employs our novel pre-gating function which alleviates the dynamic nature of sparse expert activation, allowing our proposed system to address the large memory footprint of MoEs while also achieving high performance. We demonstrate that Pre-gated MoE is able to improve performance, reduce GPU memory consumption, while also maintaining the same level of model quality. These features allow our Pre-gated MoE system to cost-effectively deploy large-scale LLMs using just a single GPU with high performance.
Tutel: Adaptive Mixture-of-Experts at Scale
Jun 07, 2022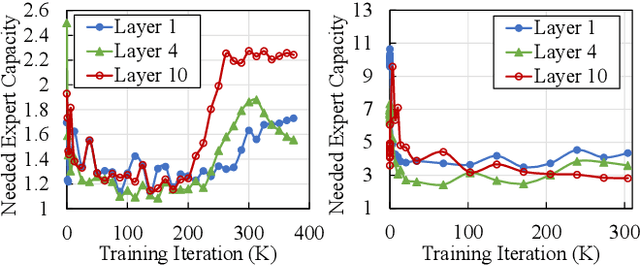
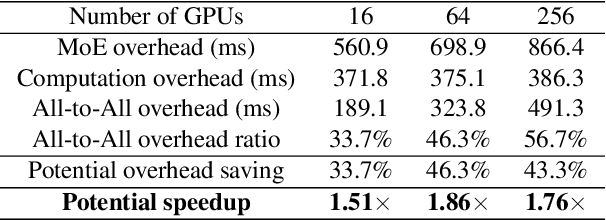
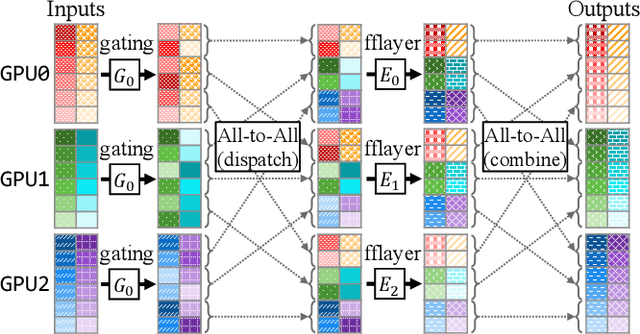

In recent years, Mixture-of-Experts (MoE) has emerged as a promising technique for deep learning that can scale the model capacity to trillion-plus parameters while reducing the computing cost via sparse computation. While MoE opens a new frontier of exceedingly large models, its implementation over thousands of GPUs has been limited due to mismatch between the dynamic nature of MoE and static parallelism/pipelining of the system. We present Tutel, a highly scalable stack design and implementation for MoE with dynamically adaptive parallelism and pipelining. Tutel delivers adaptive parallelism switching and adaptive pipelining at runtime, which achieves up to 1.74x and 2.00x single MoE layer speedup, respectively. We also propose a novel two-dimensional hierarchical algorithm for MoE communication speedup that outperforms the previous state-of-the-art up to 20.7x over 2,048 GPUs. Aggregating all techniques, Tutel finally delivers 4.96x and 5.75x speedup of a single MoE layer on 16 GPUs and 2,048 GPUs, respectively, over Fairseq: Meta's Facebook AI Research Sequence-to-Sequence Toolkit (Tutel is now partially adopted by Fairseq). Tutel source code is available in public: https://github.com/microsoft/tutel . Our evaluation shows that Tutel efficiently and effectively runs a real-world MoE-based model named SwinV2-MoE, built upon Swin Transformer V2, a state-of-the-art computer vision architecture. On efficiency, Tutel accelerates SwinV2-MoE, achieving up to 1.55x and 2.11x speedup in training and inference over Fairseq, respectively. On effectiveness, the SwinV2-MoE model achieves superior accuracy in both pre-training and down-stream computer vision tasks such as COCO object detection than the counterpart dense model, indicating the readiness of Tutel for end-to-end real-world model training and inference. SwinV2-MoE is open sourced in https://github.com/microsoft/Swin-Transformer .
Confident Multiple Choice Learning
Sep 22, 2017
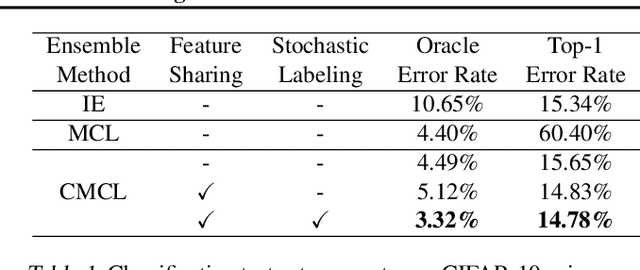


Ensemble methods are arguably the most trustworthy techniques for boosting the performance of machine learning models. Popular independent ensembles (IE) relying on naive averaging/voting scheme have been of typical choice for most applications involving deep neural networks, but they do not consider advanced collaboration among ensemble models. In this paper, we propose new ensemble methods specialized for deep neural networks, called confident multiple choice learning (CMCL): it is a variant of multiple choice learning (MCL) via addressing its overconfidence issue.In particular, the proposed major components of CMCL beyond the original MCL scheme are (i) new loss, i.e., confident oracle loss, (ii) new architecture, i.e., feature sharing and (iii) new training method, i.e., stochastic labeling. We demonstrate the effect of CMCL via experiments on the image classification on CIFAR and SVHN, and the foreground-background segmentation on the iCoseg. In particular, CMCL using 5 residual networks provides 14.05% and 6.60% relative reductions in the top-1 error rates from the corresponding IE scheme for the classification task on CIFAR and SVHN, respectively.