 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Density Inference for Efficient Language Model Reasoning
Dec 17, 2025
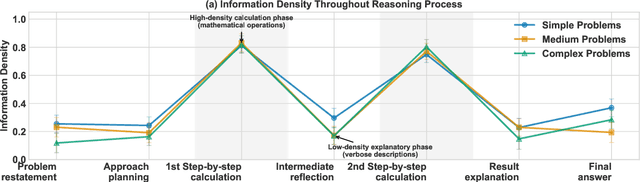
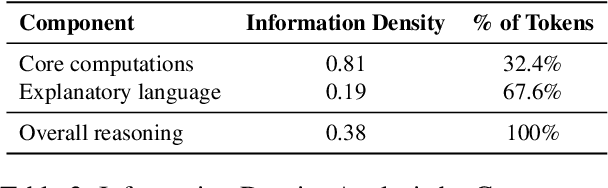
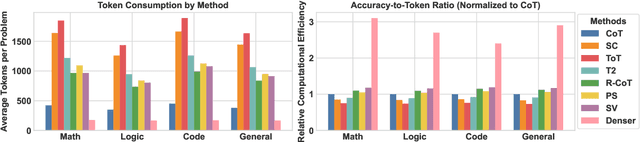
Large Language Models (LLMs) have shown impressive capabilities in complex reasoning tasks. However, current approaches employ uniform language density for both intermediate reasoning and final answers, leading to computational inefficiency. Our observation found that reasoning process serves a computational function for the model itself, while answering serves a communicative function for human understanding. This distinction enables the use of compressed, symbol-rich language for intermediate computations while maintaining human-readable final explanations. To address this inefficiency, we present Denser: \underline{D}ual-d\underline{ens}ity inf\underline{er}ence, a novel framework that optimizes information density separately for reasoning and answering phases. Our framework implements this through three components: a query processing module that analyzes input problems, a high-density compressed reasoning mechanism for efficient intermediate computations, and an answer generation component that translates compressed reasoning into human-readable solutions. Experimental evaluation across multiple reasoning question answering benchmarks demonstrates that Denser reduces token consumption by up to 62\% compared to standard Chain-of-Thought methods while preserving or improving accuracy. These efficiency gains are particularly significant for complex multi-step reasoning problems where traditional methods generate extensive explanations.
T$^2$: An Adaptive Test-Time Scaling Strategy for Contextual Question Answering
May 23, 2025Recent advances in Large Language Models (LLMs) have demonstrated remarkable performance in Contextual Question Answering (CQA). However, prior approaches typically employ elaborate reasoning strategies regardless of question complexity, leading to low adaptability. Recent efficient test-time scaling methods introduce budget constraints or early stop mechanisms to avoid overthinking for straightforward questions. But they add human bias to the reasoning process and fail to leverage models' inherent reasoning capabilities. To address these limitations, we present T$^2$: Think-to-Think, a novel framework that dynamically adapts reasoning depth based on question complexity. T$^2$ leverages the insight that if an LLM can effectively solve similar questions using specific reasoning strategies, it can apply the same strategy to the original question. This insight enables to adoption of concise reasoning for straightforward questions while maintaining detailed analysis for complex problems. T$^2$ works through four key steps: decomposing questions into structural elements, generating similar examples with candidate reasoning strategies, evaluating these strategies against multiple criteria, and applying the most appropriate strategy to the original question. Experimental evaluation across seven diverse CQA benchmarks demonstrates that T$^2$ not only achieves higher accuracy than baseline methods but also reduces computational overhead by up to 25.2\%.
MemeReaCon: Probing Contextual Meme Understanding in Large Vision-Language Models
May 23, 2025Memes have emerged as a popular form of multimodal online communication, where their interpretation heavily depends on the specific context in which they appear. Current approaches predominantly focus on isolated meme analysis, either for harmful content detection or standalone interpretation, overlooking a fundamental challenge: the same meme can express different intents depending on its conversational context. This oversight creates an evaluation gap: although humans intuitively recognize how context shapes meme interpretation, Large Vision Language Models (LVLMs) can hardly understand context-dependent meme intent. To address this critical limitation, we introduce MemeReaCon, a novel benchmark specifically designed to evaluate how LVLMs understand memes in their original context. We collected memes from five different Reddit communities, keeping each meme's image, the post text, and user comments together. We carefully labeled how the text and meme work together, what the poster intended, how the meme is structured, and how the community responded. Our tests with leading LVLMs show a clear weakness: models either fail to interpret critical information in the contexts, or overly focus on visual details while overlooking communicative purpose. MemeReaCon thus serves both as a diagnostic tool exposing current limitations and as a challenging benchmark to drive development toward more sophisticated LVLMs of the context-aware understanding.
MSCCL++: Rethinking GPU Communication Abstractions for Cutting-edge AI Applications
Apr 11, 2025

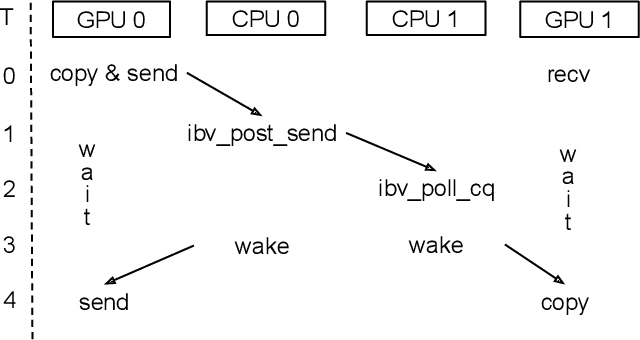
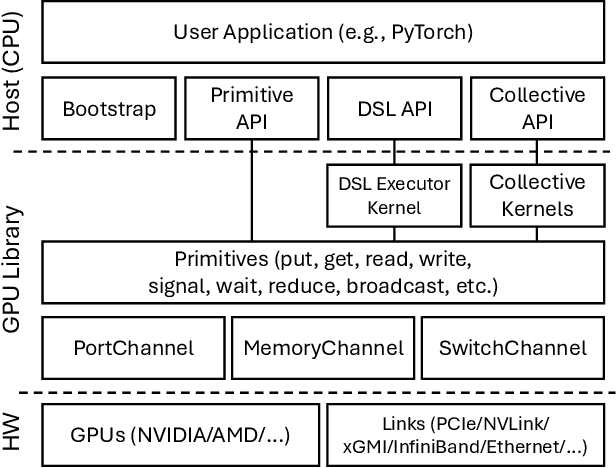
Modern cutting-edge AI applications are being developed over fast-evolving, heterogeneous, nascent hardware devices. This requires frequent reworking of the AI software stack to adopt bottom-up changes from new hardware, which takes time for general-purpose software libraries. Consequently, real applications often develop custom software stacks optimized for their specific workloads and hardware. Custom stacks help quick development and optimization, but incur a lot of redundant efforts across applications in writing non-portable code. This paper discusses an alternative communication library interface for AI applications that offers both portability and performance by reducing redundant efforts while maintaining flexibility for customization. We present MSCCL++, a novel abstraction of GPU communication based on separation of concerns: (1) a primitive interface provides a minimal hardware abstraction as a common ground for software and hardware developers to write custom communication, and (2) higher-level portable interfaces and specialized implementations enable optimization for different hardware environments. This approach makes the primitive interface reusable across applications while enabling highly flexible optimization. Compared to state-of-the-art baselines (NCCL, RCCL, and MSCCL), MSCCL++ achieves speedups of up to 3.8$\times$ for collective communication and up to 15\% for real-world AI inference workloads. MSCCL++ is in production of multiple AI services provided by Microsoft Azure, and is also adopted by RCCL, the GPU collective communication library maintained by AMD. MSCCL++ is open-source and available at https://github.com/microsoft/mscclpp.
WHERE and WHICH: Iterative Debate for Biomedical Synthetic Data Augmentation
Mar 31, 2025



In Biomedical Natural Language Processing (BioNLP) tasks, such as Relation Extraction, Named Entity Recognition, and Text Classification, the scarcity of high-quality data remains a significant challenge. This limitation poisons large language models to correctly understand relationships between biological entities, such as molecules and diseases, or drug interactions, and further results in potential misinterpretation of biomedical documents. To address this issue, current approaches generally adopt the Synthetic Data Augmentation method which involves similarity computation followed by word replacement, but counterfactual data are usually generated. As a result, these methods disrupt meaningful word sets or produce sentences with meanings that deviate substantially from the original context, rendering them ineffective in improving model performance. To this end, this paper proposes a biomedical-dedicated rationale-based synthetic data augmentation method. Beyond the naive lexicon similarity, specific bio-relation similarity is measured to hold the augmented instance having a strong correlation with bio-relation instead of simply increasing the diversity of augmented data. Moreover, a multi-agents-involved reflection mechanism helps the model iteratively distinguish different usage of similar entities to escape falling into the mis-replace trap. We evaluate our method on the BLURB and BigBIO benchmark, which includes 9 common datasets spanning four major BioNLP tasks. Our experimental results demonstrate consistent performance improvements across all tasks, highlighting the effectiveness of our approach in addressing the challenges associated with data scarcity and enhancing the overall performance of biomedical NLP models.
FReM: A Flexible Reasoning Mechanism for Balancing Quick and Slow Thinking in Long-Context Question Answering
Mar 29, 2025Long-context question-answering (LCQA) systems have greatly benefited from the powerful reasoning capabilities of large language models (LLMs), which can be categorized into slow and quick reasoning modes. However, both modes have their limitations. Slow thinking generally leans to explore every possible reasoning path, which leads to heavy overthinking and wastes time. Quick thinking usually relies on pattern matching rather than truly understanding the query logic, which misses proper understanding. To address these issues, we propose FReM: Flexible Reasoning Mechanism, a method that adjusts reasoning depth according to the complexity of each question. Specifically, FReM leverages synthetic reference QA examples to provide an explicit chain of thought, enabling efficient handling of simple queries while allowing deeper reasoning for more complex ones. By doing so, FReM helps quick-thinking models move beyond superficial pattern matching and narrows the reasoning space for slow-thinking models to avoid unnecessary exploration. Experiments on seven QA datasets show that FReM improves reasoning accuracy and scalability, particularly for complex multihop questions, indicating its potential to advance LCQA methodologies.
EventWeave: A Dynamic Framework for Capturing Core and Supporting Events in Dialogue Systems
Mar 29, 2025Existing large language models (LLMs) have shown remarkable progress in dialogue systems. However, many approaches still overlook the fundamental role of events throughout multi-turn interactions, leading to \textbf{incomplete context tracking}. Without tracking these events, dialogue systems often lose coherence and miss subtle shifts in user intent, causing disjointed responses. To bridge this gap, we present \textbf{EventWeave}, an event-centric framework that identifies and updates both core and supporting events as the conversation unfolds. Specifically, we organize these events into a dynamic event graph, which represents the interplay between \textbf{core events} that shape the primary idea and \textbf{supporting events} that provide critical context during the whole dialogue. By leveraging this dynamic graph, EventWeave helps models focus on the most relevant events when generating responses, thus avoiding repeated visits of the entire dialogue history. Experimental results on two benchmark datasets show that EventWeave improves response quality and event relevance without fine-tuning.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions
Apr 30, 2021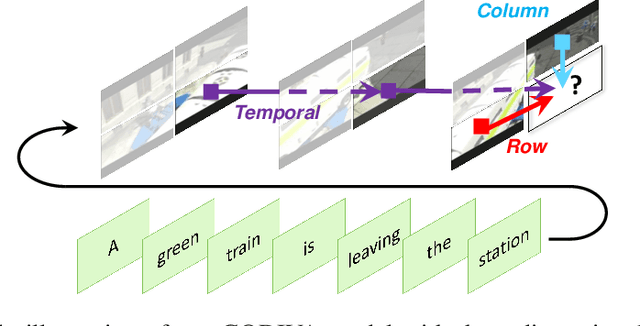
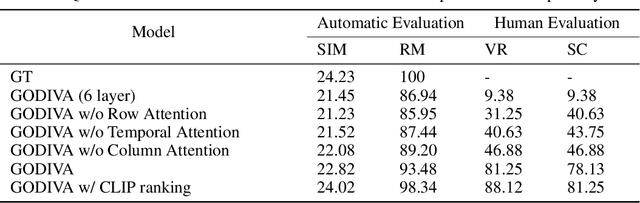
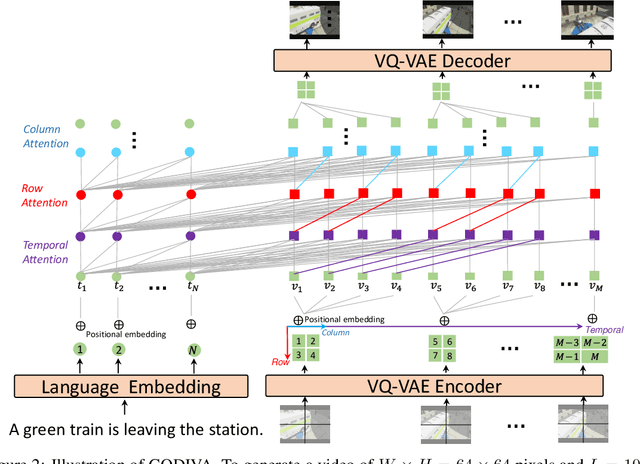

Generating videos from text is a challenging task due to its high computational requirements for training and infinite possible answers for evaluation. Existing works typically experiment on simple or small datasets, where the generalization ability is quite limited. In this work, we propose GODIVA, an open-domain text-to-video pretrained model that can generate videos from text in an auto-regressive manner using a three-dimensional sparse attention mechanism. We pretrain our model on Howto100M, a large-scale text-video dataset that contains more than 136 million text-video pairs. Experiments show that GODIVA not only can be fine-tuned on downstream video generation tasks, but also has a good zero-shot capability on unseen texts. We also propose a new metric called Relative Matching (RM) to automatically evaluate the video generation quality. Several challenges are listed and discussed as future work.
CHIME: Cross-passage Hierarchical Memory Network for Generative Review Question Answering
Nov 01, 2020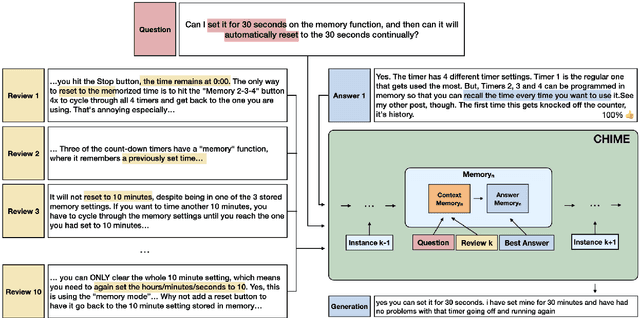
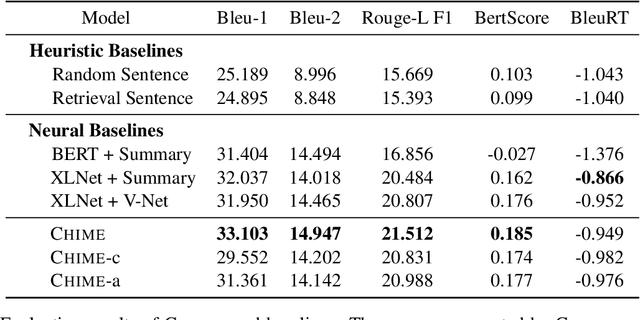
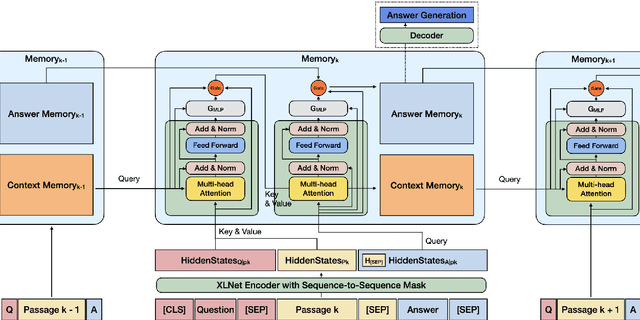
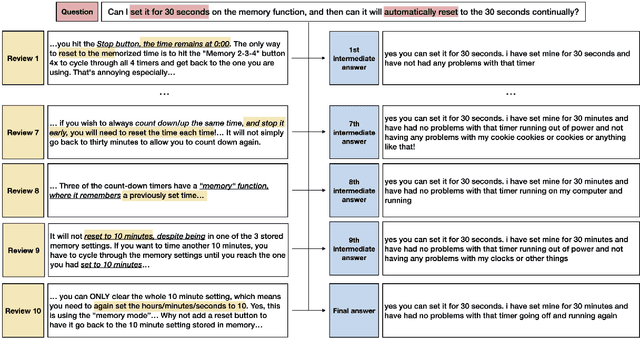
We introduce CHIME, a cross-passage hierarchical memory network for question answering (QA) via text generation. It extends XLNet introducing an auxiliary memory module consisting of two components: the context memory collecting cross-passage evidences, and the answer memory working as a buffer continually refining the generated answers. Empirically, we show the efficacy of the proposed architecture in the multi-passage generative QA, outperforming the state-of-the-art baselines with better syntactically well-formed answers and increased precision in addressing the questions of the AmazonQA review dataset. An additional qualitative analysis revealed the interpretability introduced by the memory module.