 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Data Attribution for Diffusion Models
Oct 16, 2025Data attribution for generative models seeks to quantify the influence of individual training examples on model outputs. Existing methods for diffusion models typically require access to model gradients or retraining, limiting their applicability in proprietary or large-scale settings. We propose a nonparametric attribution method that operates entirely on data, measuring influence via patch-level similarity between generated and training images. Our approach is grounded in the analytical form of the optimal score function and naturally extends to multiscale representations, while remaining computationally efficient through convolution-based acceleration. In addition to producing spatially interpretable attributions, our framework uncovers patterns that reflect intrinsic relationships between training data and outputs, independent of any specific model. Experiments demonstrate that our method achieves strong attribution performance, closely matching gradient-based approaches and substantially outperforming existing nonparametric baselines. Code is available at https://github.com/sail-sg/NDA.
MemeReaCon: Probing Contextual Meme Understanding in Large Vision-Language Models
May 23, 2025Memes have emerged as a popular form of multimodal online communication, where their interpretation heavily depends on the specific context in which they appear. Current approaches predominantly focus on isolated meme analysis, either for harmful content detection or standalone interpretation, overlooking a fundamental challenge: the same meme can express different intents depending on its conversational context. This oversight creates an evaluation gap: although humans intuitively recognize how context shapes meme interpretation, Large Vision Language Models (LVLMs) can hardly understand context-dependent meme intent. To address this critical limitation, we introduce MemeReaCon, a novel benchmark specifically designed to evaluate how LVLMs understand memes in their original context. We collected memes from five different Reddit communities, keeping each meme's image, the post text, and user comments together. We carefully labeled how the text and meme work together, what the poster intended, how the meme is structured, and how the community responded. Our tests with leading LVLMs show a clear weakness: models either fail to interpret critical information in the contexts, or overly focus on visual details while overlooking communicative purpose. MemeReaCon thus serves both as a diagnostic tool exposing current limitations and as a challenging benchmark to drive development toward more sophisticated LVLMs of the context-aware understanding.
T$^2$: An Adaptive Test-Time Scaling Strategy for Contextual Question Answering
May 23, 2025Recent advances in Large Language Models (LLMs) have demonstrated remarkable performance in Contextual Question Answering (CQA). However, prior approaches typically employ elaborate reasoning strategies regardless of question complexity, leading to low adaptability. Recent efficient test-time scaling methods introduce budget constraints or early stop mechanisms to avoid overthinking for straightforward questions. But they add human bias to the reasoning process and fail to leverage models' inherent reasoning capabilities. To address these limitations, we present T$^2$: Think-to-Think, a novel framework that dynamically adapts reasoning depth based on question complexity. T$^2$ leverages the insight that if an LLM can effectively solve similar questions using specific reasoning strategies, it can apply the same strategy to the original question. This insight enables to adoption of concise reasoning for straightforward questions while maintaining detailed analysis for complex problems. T$^2$ works through four key steps: decomposing questions into structural elements, generating similar examples with candidate reasoning strategies, evaluating these strategies against multiple criteria, and applying the most appropriate strategy to the original question. Experimental evaluation across seven diverse CQA benchmarks demonstrates that T$^2$ not only achieves higher accuracy than baseline methods but also reduces computational overhead by up to 25.2\%.
Understanding Performance of Long-Document Ranking Models through Comprehensive Evaluation and Leaderboarding
Jul 04, 2022
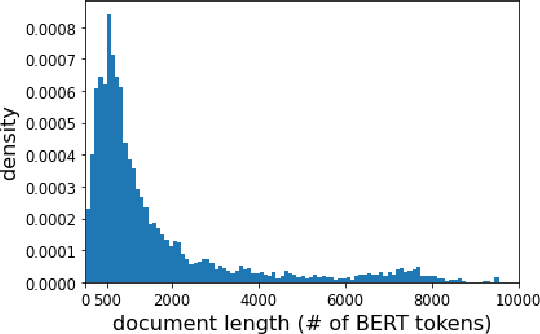
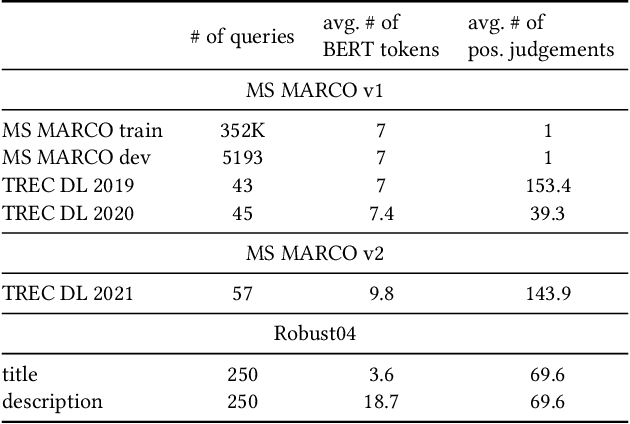
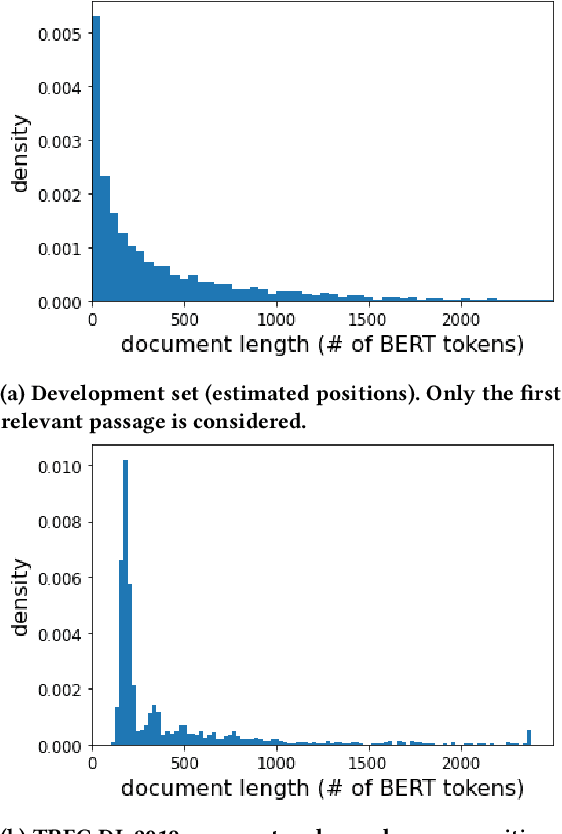
We carry out a comprehensive evaluation of 13 recent models for ranking of long documents using two popular collections (MS MARCO documents and Robust04). Our model zoo includes two specialized Transformer models (such as Longformer) that can process long documents without the need to split them. Along the way, we document several difficulties regarding training and comparing such models. Somewhat surprisingly, we find the simple FirstP baseline (truncating documents to satisfy the input-sequence constraint of a typical Transformer model) to be quite effective. We analyze the distribution of relevant passages (inside documents) to explain this phenomenon. We further argue that, despite their widespread use, Robust04 and MS MARCO documents are not particularly useful for benchmarking of long-document models.