 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Performance of Long-Document Ranking Models through Comprehensive Evaluation and Leaderboarding
Paper and Code

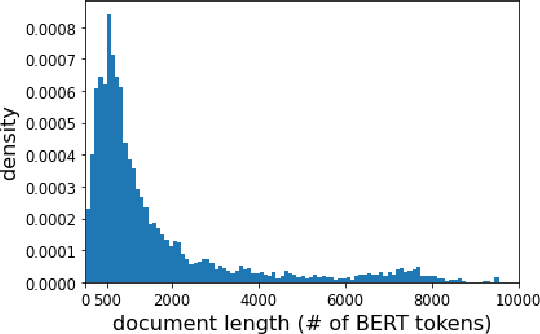
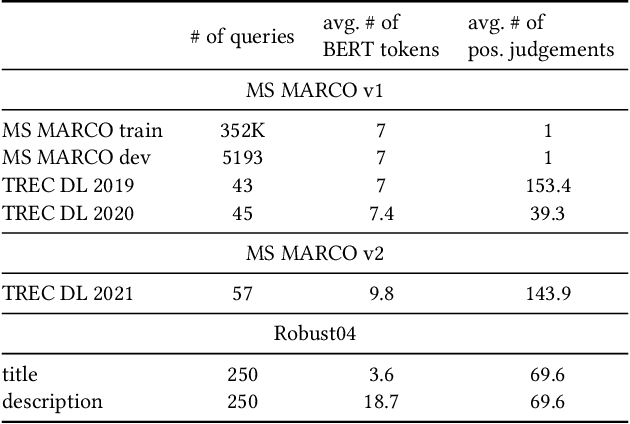
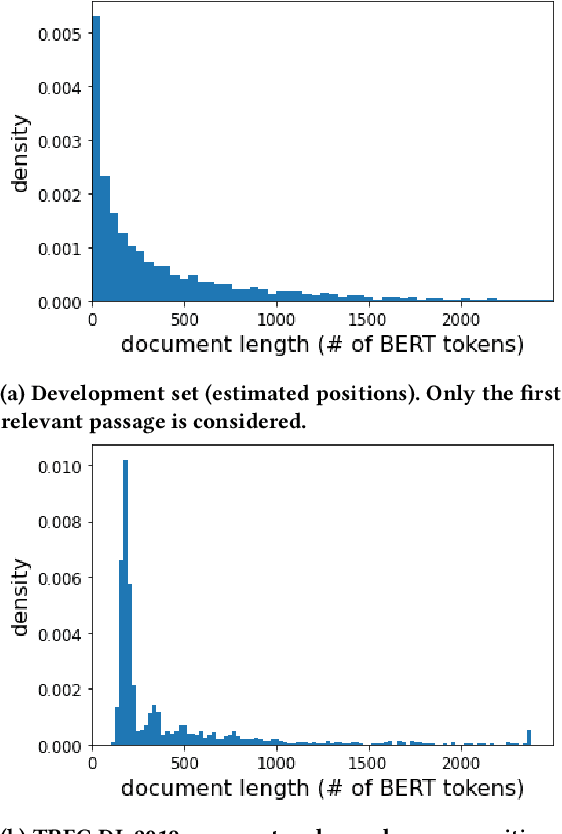
We carry out a comprehensive evaluation of 13 recent models for ranking of long documents using two popular collections (MS MARCO documents and Robust04). Our model zoo includes two specialized Transformer models (such as Longformer) that can process long documents without the need to split them. Along the way, we document several difficulties regarding training and comparing such models. Somewhat surprisingly, we find the simple FirstP baseline (truncating documents to satisfy the input-sequence constraint of a typical Transformer model) to be quite effective. We analyze the distribution of relevant passages (inside documents) to explain this phenomenon. We further argue that, despite their widespread use, Robust04 and MS MARCO documents are not particularly useful for benchmarking of long-document models.