 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenClaw-Skill: Collective Skill Tree Search for Agentic Large Language Models
Jun 15, 2026Equipping Large Language Model (LLM) agents with effective skills is crucial for solving complex tasks in real-world systems like OpenClaw. In this work, we aim to develop a framework that automatically constructs such reusable skills to enhance LLMs in tool use, multi-step reasoning, and dynamic environment interaction. To this end, we propose Collective Skill Tree Search (CSTS), a novel tree-search-based skill construction framework that constructs structured, diverse and generalizable tree of skills. The core idea of CSTS is to leverage collective intelligence to jointly search, identify and compose effective skills via two iterative phases: Collective Skill Node Generation (CSN-Gen) and Collective Skill Node Assessment (CSN-Assess). CSN-Gen exploits collective knowledge from multiple models to explore diverse candidate skills for each subtask, enabling comprehensive skill exploration. CSN-Assess employs multiple models as judges to evaluate and select skill nodes with two scoring mechanisms: (1) collective quality scoring that aggregates independent evaluations to produce a robust estimate of skill effectiveness, and (2) collective transferability scoring that explicitly verifies whether a skill generalizes well across different models. With CSTS, we construct a set of comprehensive tree of skills along with skill-augmented training data, enabling models to effectively learn and utilize skills. Besides, we introduce Collective Skill Reinforcement Learning, which actively selects multiple relevant skills from the tree to broaden solution-space exploration, avoid being trapped by a single skill and its resulting homogeneous or suboptimal solutions. As a result, our trained model, OpenClaw-Skill, exhibits outstanding agentic capabilities in long-horizon planning, tool use and generalization over challenging benchmarks.
Efficient Exploration for Iterative Nash Preference Optimization
May 31, 2026Preference alignment is central to improving large language models, but standard reward-based formulations can be restrictive when human preferences are cyclic, non-transitive, or otherwise not representable by a scalar reward. Nash Learning from Human Feedback (NLHF) addresses this limitation by modeling alignment as a preference game and targeting a Nash equilibrium rather than a reward maximizer. However, the learning-theoretic foundations of scalable NLHF remain limited. Existing regret guarantees rely on oracle-based methods that estimate a general preference model and solve KL-regularized minimax problems, while iterative NLHF methods directly optimize policy-level preference losses and are easier to implement but lack regret guarantees. We study online iterative NLHF under general preference models and identify exploration as the key obstacle. First, we show that standard iterative NLHF can suffer an exponential dependence on the KL-regularization parameter, revealing that implicit exploration through policy updates is insufficient for controlling regret. Second, we propose an explicitly exploratory iterative NLHF algorithm that combines SFT-based regularization with adversarial policy exploration. The resulting method retains the direct policy optimization structure of iterative NLHF, avoids explicit preference model estimation, and achieves an $O(\sqrt{T})$ regret bound without an exponential dependence on the KL-regularization parameter. We show that the regret can be improved to $O(\log(T))$ with access to a minimax oracle, clarifying the computational-statistical tradeoff in learning general preference games. Finally, we instantiate our method for LLM fine-tuning and evaluate it on \texttt{Llama-3-8B-Instruct} across multiple benchmarks, where explicit exploration yields consistent improvements over existing NLHF baselines.
DRIFT: Decoupled Rollouts and Importance-Weighted Fine-Tuning for Efficient Multi-Turn Optimization
May 29, 2026Large language models are increasingly deployed in multi-turn interactive settings where users or environments can iteratively provide lightweight feedback. Unfortunately, optimizing such behavior presents a sharp dilemma in practice: online reinforcement learning is able to effectively address multi-turn dynamics but is prohibitively expensive due to the cost of generating full correction trajectories at every update, whereas offline supervised fine-tuning (SFT) is efficient but suffers from distribution shift and behavioral collapse. To this end, we novelly propose DRIFT (Decoupled Rollouts and Importance-Weighted Fine-Tuning), a framework that operationalizes the theoretical insight that the KL-regularized RL objective is equivalent to importance-weighted supervised learning. DRIFT decouples rollout from optimization by sampling offline interaction trajectories from a fixed reference policy, deriving return-based importance weights, and optimizing the policy via weighted SFT on the resulting dataset. Empirically, we demonstrate that DRIFT matches or exceeds the performance of multi-turn reinforcement learning baselines while maintaining the training efficiency and simplicity of standard supervised fine-tuning. Code is available at https://github.com/2020-qqtcg/DRIFT.
Scale-Invariant Neural Network Optimization: Norm Geometry and Heavy-Tailed Noise
May 18, 2026A growing lesson from neural network optimization is that optimizer design should respect how the model is parametrized. Scale-invariant methods become important because their normalized layerwise updates can not only support hyperparameter transfer across model sizes but exploit input-output matrix norm geometry. At the same time, stochastic gradient noises in deep learning are often far from sub-Gaussian and may exhibit heavy tails. These crucial observations have shaped recent algorithmic principles for training neural networks, yet their joint theoretical consequences remain underexplored. In particular, it is unclear what dimension dependence is unavoidable for scale-invariant methods with general input-output matrix norm, and whether higher-order smoothness can accelerate training under heavy-tailed noise. We study these questions through nonconvex smooth stochastic optimization over $\mathbb{R}^{m\times n}$ with general norms, where the goal is to achieve an $ε$-stationary point under $p^{\mathrm{th}}$-moment heavy-tailed noise. Our first contribution is a dimension-dependent lower bound: when $\frac{\max\{m,n\}}{(\min\{m,n\})^2}$ is large enough, any scale-invariant first-order method with spectral norm requires $Ω(\min\{m, n\}ε^{-\frac{3p-2}{p-1}})$ oracle calls. We prove that a batched Scion method with spectral norm achieves the matching upper bound of $O(\min\{m, n\}ε^{-\frac{3p-2}{p-1}})$. To exploit higher-order smoothness, we propose a transported Scion method and improve the bound to $O(\min\{m, n\}ε^{-\frac{5p-3}{2p-2}})$ when the norm is spectral and the Hessian is Lipschitz. Finally, we incorporate practical heuristics into our transported method and evaluate it across multiple architectures and model sizes, demonstrating its flexibility and compatibility in training neural networks.
How AI Aggregation Affects Knowledge
Apr 06, 2026Artificial intelligence (AI) changes social learning when aggregated outputs become training data for future predictions. To study this, we extend the DeGroot model by introducing an AI aggregator that trains on population beliefs and feeds synthesized signals back to agents. We define the learning gap as the deviation of long-run beliefs from the efficient benchmark, allowing us to capture how AI aggregation affects learning. Our main result identifies a threshold in the speed of updating: when the aggregator updates too quickly, there is no positive-measure set of training weights that robustly improves learning across a broad class of environments, whereas such weights exist when updating is sufficiently slow. We then compare global and local architectures. Local aggregators trained on proximate or topic-specific data robustly improve learning in all environments. Consequently, replacing specialized local aggregators with a single global aggregator worsens learning in at least one dimension of the state.
R1-SyntheticVL: Is Synthetic Data from Generative Models Ready for Multimodal Large Language Model?
Feb 03, 2026In this work, we aim to develop effective data synthesis techniques that autonomously synthesize multimodal training data for enhancing MLLMs in solving complex real-world tasks. To this end, we propose Collective Adversarial Data Synthesis (CADS), a novel and general approach to synthesize high-quality, diverse and challenging multimodal data for MLLMs. The core idea of CADS is to leverage collective intelligence to ensure high-quality and diverse generation, while exploring adversarial learning to synthesize challenging samples for effectively driving model improvement. Specifically, CADS operates with two cyclic phases, i.e., Collective Adversarial Data Generation (CAD-Generate) and Collective Adversarial Data Judgment (CAD-Judge). CAD-Generate leverages collective knowledge to jointly generate new and diverse multimodal data, while CAD-Judge collaboratively assesses the quality of synthesized data. In addition, CADS introduces an Adversarial Context Optimization mechanism to optimize the generation context to encourage challenging and high-value data generation. With CADS, we construct MMSynthetic-20K and train our model R1-SyntheticVL, which demonstrates superior performance on various benchmarks.
Reward-free Alignment for Conflicting Objectives
Feb 02, 2026Direct alignment methods are increasingly used to align large language models (LLMs) with human preferences. However, many real-world alignment problems involve multiple conflicting objectives, where naive aggregation of preferences can lead to unstable training and poor trade-offs. In particular, weighted loss methods may fail to identify update directions that simultaneously improve all objectives, and existing multi-objective approaches often rely on explicit reward models, introducing additional complexity and distorting user-specified preferences. The contributions of this paper are two-fold. First, we propose a Reward-free Alignment framework for Conflicted Objectives (RACO) that directly leverages pairwise preference data and resolves gradient conflicts via a novel clipped variant of conflict-averse gradient descent. We provide convergence guarantees to Pareto-critical points that respect user-specified objective weights, and further show that clipping can strictly improve convergence rate in the two-objective setting. Second, we improve our method using some heuristics and conduct experiments to demonstrate the compatibility of the proposed framework for LLM alignment. Both qualitative and quantitative evaluations on multi-objective summarization and safety alignment tasks across multiple LLM families (Qwen 3, Llama 3, Gemma 3) show that our method consistently achieves better Pareto trade-offs compared to existing multi-objective alignment baselines.
Exploration vs Exploitation: Rethinking RLVR through Clipping, Entropy, and Spurious Reward
Dec 21, 2025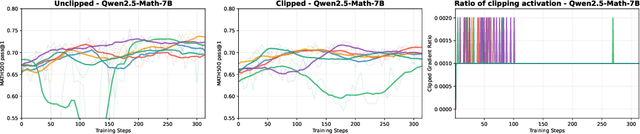
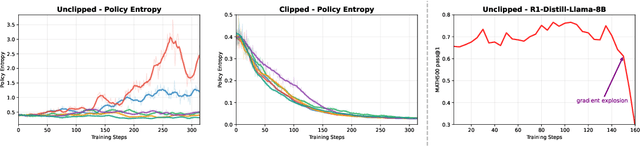

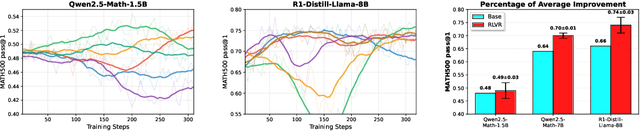
This paper examines the exploration-exploitation trade-off in reinforcement learning with verifiable rewards (RLVR), a framework for improving the reasoning of Large Language Models (LLMs). Recent studies suggest that RLVR can elicit strong mathematical reasoning in LLMs through two seemingly paradoxical mechanisms: spurious rewards, which suppress exploitation by rewarding outcomes unrelated to the ground truth, and entropy minimization, which suppresses exploration by pushing the model toward more confident and deterministic outputs, highlighting a puzzling dynamic: both discouraging exploitation and discouraging exploration improve reasoning performance, yet the underlying principles that reconcile these effects remain poorly understood. We focus on two fundamental questions: (i) how policy entropy relates to performance, and (ii) whether spurious rewards yield gains, potentially through the interplay of clipping bias and model contamination. Our results show that clipping bias under spurious rewards reduces policy entropy, leading to more confident and deterministic outputs, while entropy minimization alone is insufficient for improvement. We further propose a reward-misalignment model explaining why spurious rewards can enhance performance beyond contaminated settings. Our findings clarify the mechanisms behind spurious-reward benefits and provide principles for more effective RLVR training.
Spectral Policy Optimization: Coloring your Incorrect Reasoning in GRPO
May 16, 2025Reinforcement learning (RL) has demonstrated significant success in enhancing reasoning capabilities in large language models (LLMs). One of the most widely used RL methods is Group Relative Policy Optimization (GRPO)~\cite{Shao-2024-Deepseekmath}, known for its memory efficiency and success in training DeepSeek-R1~\cite{Guo-2025-Deepseek}. However, GRPO stalls when all sampled responses in a group are incorrect -- referred to as an \emph{all-negative-sample} group -- as it fails to update the policy, hindering learning progress. The contributions of this paper are two-fold. First, we propose a simple yet effective framework that introduces response diversity within all-negative-sample groups in GRPO using AI feedback. We also provide a theoretical analysis, via a stylized model, showing how this diversification improves learning dynamics. Second, we empirically validate our approach, showing the improved performance across various model sizes (7B, 14B, 32B) in both offline and online learning settings with 10 benchmarks, including base and distilled variants. Our findings highlight that learning from all-negative-sample groups is not only feasible but beneficial, advancing recent insights from \citet{Xiong-2025-Minimalist}.
ComPO: Preference Alignment via Comparison Oracles
May 08, 2025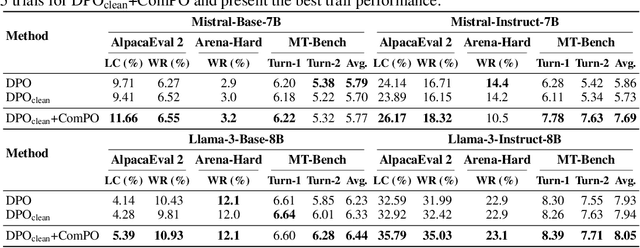



Direct alignment methods are increasingly used for aligning large language models (LLMs) with human preferences. However, these methods suffer from the issues of verbosity and likelihood displacement, which can be driven by the noisy preference pairs that induce similar likelihood for preferred and dispreferred responses. The contributions of this paper are two-fold. First, we propose a new preference alignment method based on comparison oracles and provide the convergence guarantee for its basic scheme. Second, we improve our method using some heuristics and conduct the experiments to demonstrate the flexibility and compatibility of practical scheme in improving the performance of LLMs using noisy preference pairs. Evaluations are conducted across multiple base and instruction-tuned models (Mistral-7B, Llama-3-8B and Gemma-2-9B) with benchmarks (AlpacaEval 2, MT-Bench and Arena-Hard). Experimental results show the effectiveness of our method as an alternative to addressing the limitations of existing direct alignment methods. A highlight of our work is that we evidence the importance of designing specialized methods for preference pairs with distinct likelihood margin, which complements the recent findings in \citet{Razin-2025-Unintentional}.