 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors
Jan 22, 2026Large language models (LLMs) can call tools effectively, yet they remain brittle in multi-turn execution: following a tool call error, smaller models often degenerate into repetitive invalid re-invocations, failing to interpret error feedback and self-correct. This brittleness hinders reliable real-world deployment, where the execution errors are inherently inevitable during tool interaction procedures. We identify a key limitation of current approaches: standard reinforcement learning (RL) treats errors as sparse negative rewards, providing no guidance on how to recover, while pre-collected synthetic error-correction datasets suffer from distribution mismatch with the model's on-policy error modes. To bridge this gap, we propose Fission-GRPO, a framework that converts execution errors into corrective supervision within the RL training loop. Our core mechanism fissions each failed trajectory into a new training instance by augmenting it with diagnostic feedback from a finetuned Error Simulator, then resampling recovery rollouts on-policy. This enables the model to learn from the precise errors it makes during exploration, rather than from static, pre-collected error cases. On the BFCL v4 Multi-Turn, Fission-GRPO improves the error recovery rate of Qwen3-8B by 5.7% absolute, crucially, yielding a 4% overall accuracy gain (42.75% to 46.75%) over GRPO and outperforming specialized tool-use agents.
Fast, Slow, and Tool-augmented Thinking for LLMs: A Review
Aug 17, 2025Large Language Models (LLMs) have demonstrated remarkable progress in reasoning across diverse domains. However, effective reasoning in real-world tasks requires adapting the reasoning strategy to the demands of the problem, ranging from fast, intuitive responses to deliberate, step-by-step reasoning and tool-augmented thinking. Drawing inspiration from cognitive psychology, we propose a novel taxonomy of LLM reasoning strategies along two knowledge boundaries: a fast/slow boundary separating intuitive from deliberative processes, and an internal/external boundary distinguishing reasoning grounded in the model's parameters from reasoning augmented by external tools. We systematically survey recent work on adaptive reasoning in LLMs and categorize methods based on key decision factors. We conclude by highlighting open challenges and future directions toward more adaptive, efficient, and reliable LLMs.
Stepwise Reasoning Checkpoint Analysis: A Test Time Scaling Method to Enhance LLMs' Reasoning
May 23, 2025Mathematical reasoning through Chain-of-Thought (CoT) has emerged as a powerful capability of Large Language Models (LLMs), which can be further enhanced through Test-Time Scaling (TTS) methods like Beam Search and DVTS. However, these methods, despite improving accuracy by allocating more computational resources during inference, often suffer from path homogenization and inefficient use of intermediate results. To address these limitations, we propose Stepwise Reasoning Checkpoint Analysis (SRCA), a framework that introduces checkpoints between reasoning steps. It incorporates two key strategies: (1) Answer-Clustered Search, which groups reasoning paths by their intermediate checkpoint answers to maintain diversity while ensuring quality, and (2) Checkpoint Candidate Augmentation, which leverages all intermediate answers for final decision-making. Our approach effectively reduces path homogenization and creates a fault-tolerant mechanism by utilizing high-quality intermediate results. Experimental results show that SRCA improves reasoning accuracy compared to existing TTS methods across various mathematical datasets.
MemeReaCon: Probing Contextual Meme Understanding in Large Vision-Language Models
May 23, 2025Memes have emerged as a popular form of multimodal online communication, where their interpretation heavily depends on the specific context in which they appear. Current approaches predominantly focus on isolated meme analysis, either for harmful content detection or standalone interpretation, overlooking a fundamental challenge: the same meme can express different intents depending on its conversational context. This oversight creates an evaluation gap: although humans intuitively recognize how context shapes meme interpretation, Large Vision Language Models (LVLMs) can hardly understand context-dependent meme intent. To address this critical limitation, we introduce MemeReaCon, a novel benchmark specifically designed to evaluate how LVLMs understand memes in their original context. We collected memes from five different Reddit communities, keeping each meme's image, the post text, and user comments together. We carefully labeled how the text and meme work together, what the poster intended, how the meme is structured, and how the community responded. Our tests with leading LVLMs show a clear weakness: models either fail to interpret critical information in the contexts, or overly focus on visual details while overlooking communicative purpose. MemeReaCon thus serves both as a diagnostic tool exposing current limitations and as a challenging benchmark to drive development toward more sophisticated LVLMs of the context-aware understanding.
T$^2$: An Adaptive Test-Time Scaling Strategy for Contextual Question Answering
May 23, 2025Recent advances in Large Language Models (LLMs) have demonstrated remarkable performance in Contextual Question Answering (CQA). However, prior approaches typically employ elaborate reasoning strategies regardless of question complexity, leading to low adaptability. Recent efficient test-time scaling methods introduce budget constraints or early stop mechanisms to avoid overthinking for straightforward questions. But they add human bias to the reasoning process and fail to leverage models' inherent reasoning capabilities. To address these limitations, we present T$^2$: Think-to-Think, a novel framework that dynamically adapts reasoning depth based on question complexity. T$^2$ leverages the insight that if an LLM can effectively solve similar questions using specific reasoning strategies, it can apply the same strategy to the original question. This insight enables to adoption of concise reasoning for straightforward questions while maintaining detailed analysis for complex problems. T$^2$ works through four key steps: decomposing questions into structural elements, generating similar examples with candidate reasoning strategies, evaluating these strategies against multiple criteria, and applying the most appropriate strategy to the original question. Experimental evaluation across seven diverse CQA benchmarks demonstrates that T$^2$ not only achieves higher accuracy than baseline methods but also reduces computational overhead by up to 25.2\%.
ToolACE-R: Tool Learning with Adaptive Self-Refinement
Apr 02, 2025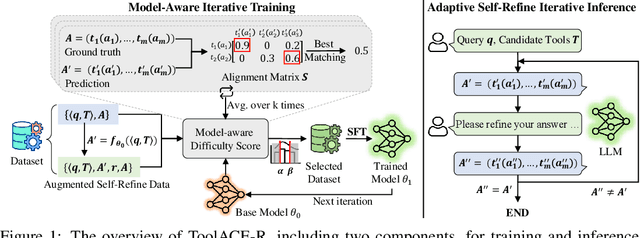
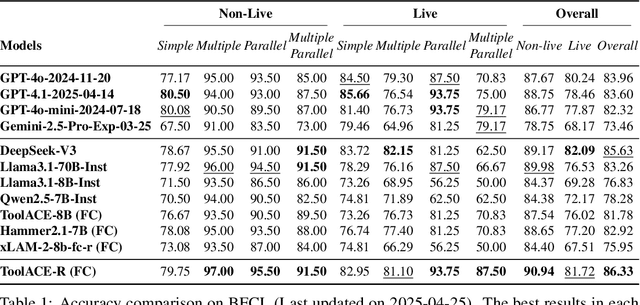
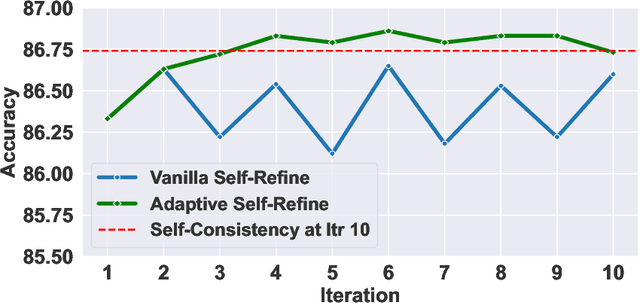

Tool learning, which allows Large Language Models (LLMs) to leverage external tools for solving complex user tasks, has emerged as a promising avenue for extending model capabilities. However, current approaches primarily focus on data synthesis for fine-tuning LLMs to invoke tools effectively, largely ignoring how to fully stimulate the potential of the model. In this paper, we propose ToolACE-R, a novel method that introduces adaptive self-refinement for tool invocations. Our approach features a model-aware iterative training procedure that progressively incorporates more training samples based on the model's evolving capabilities. Additionally, it allows LLMs to iteratively refine their tool calls, optimizing performance without requiring external feedback. To further enhance computational efficiency, we integrate an adaptive mechanism when scaling the inference time, enabling the model to autonomously determine when to stop the refinement process. We conduct extensive experiments across several benchmark datasets, showing that ToolACE-R achieves competitive performance compared to advanced API-based models, even without any refinement. Furthermore, its performance can be further improved efficiently through adaptive self-refinement. Our results demonstrate the effectiveness of the proposed method, which is compatible with base models of various sizes, offering a promising direction for more efficient tool learning.
FReM: A Flexible Reasoning Mechanism for Balancing Quick and Slow Thinking in Long-Context Question Answering
Mar 29, 2025Long-context question-answering (LCQA) systems have greatly benefited from the powerful reasoning capabilities of large language models (LLMs), which can be categorized into slow and quick reasoning modes. However, both modes have their limitations. Slow thinking generally leans to explore every possible reasoning path, which leads to heavy overthinking and wastes time. Quick thinking usually relies on pattern matching rather than truly understanding the query logic, which misses proper understanding. To address these issues, we propose FReM: Flexible Reasoning Mechanism, a method that adjusts reasoning depth according to the complexity of each question. Specifically, FReM leverages synthetic reference QA examples to provide an explicit chain of thought, enabling efficient handling of simple queries while allowing deeper reasoning for more complex ones. By doing so, FReM helps quick-thinking models move beyond superficial pattern matching and narrows the reasoning space for slow-thinking models to avoid unnecessary exploration. Experiments on seven QA datasets show that FReM improves reasoning accuracy and scalability, particularly for complex multihop questions, indicating its potential to advance LCQA methodologies.
ToolFlow: Boosting LLM Tool-Calling Through Natural and Coherent Dialogue Synthesis
Oct 24, 2024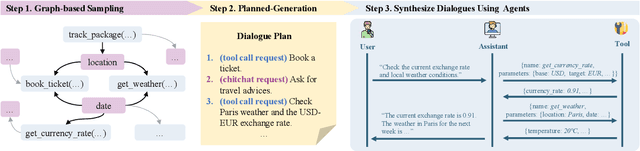
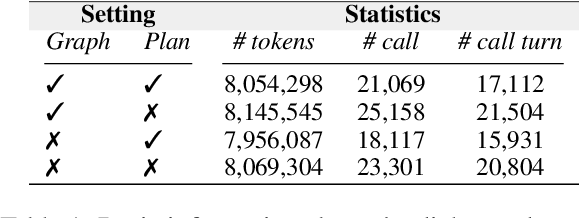


Supervised fine-tuning (SFT) is a common method to enhance the tool calling capabilities of Large Language Models (LLMs), with the training data often being synthesized. The current data synthesis process generally involves sampling a set of tools, formulating a requirement based on these tools, and generating the call statements. However, tools sampled randomly lack relevance, making them difficult to combine and thus reducing the diversity of the data. Additionally, current work overlooks the coherence between turns of dialogues, leading to a gap between the synthesized data and real-world scenarios. To address these issues, we propose a Graph-based Sampling strategy to sample more relevant tool combinations, and a Planned-generation strategy to create plans that guide the synthesis of coherent dialogues. We integrate these two strategies and enable multiple agents to synthesize the dialogue data interactively, resulting in our tool-calling data synthesis pipeline ToolFlow. Data quality assessments demonstrate improvements in the naturalness and coherence of our synthesized dialogues. Finally, we apply SFT on LLaMA-3.1-8B using 8,000 synthetic dialogues generated with ToolFlow. Results show that the model achieves tool-calling performance comparable to or even surpassing GPT-4, while maintaining strong general capabilities.
MlingConf: A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
Oct 16, 2024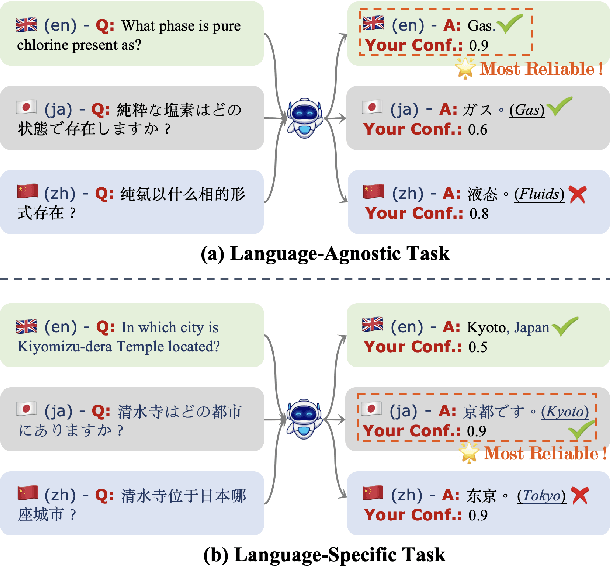

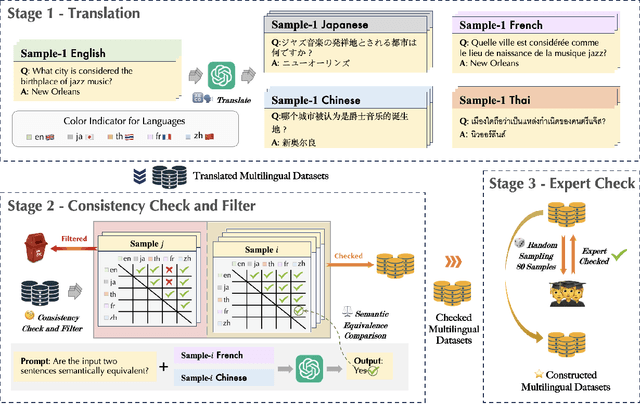
The tendency of Large Language Models (LLMs) to generate hallucinations raises concerns regarding their reliability. Therefore, confidence estimations indicating the extent of trustworthiness of the generations become essential. However, current LLM confidence estimations in languages other than English remain underexplored. This paper addresses this gap by introducing a comprehensive investigation of Multilingual Confidence estimation (MlingConf) on LLMs, focusing on both language-agnostic (LA) and language-specific (LS) tasks to explore the performance and language dominance effects of multilingual confidence estimations on different tasks. The benchmark comprises four meticulously checked and human-evaluate high-quality multilingual datasets for LA tasks and one for the LS task tailored to specific social, cultural, and geographical contexts of a language. Our experiments reveal that on LA tasks English exhibits notable linguistic dominance in confidence estimations than other languages, while on LS tasks, using question-related language to prompt LLMs demonstrates better linguistic dominance in multilingual confidence estimations. The phenomena inspire a simple yet effective native-tone prompting strategy by employing language-specific prompts for LS tasks, effectively improving LLMs' reliability and accuracy on LS tasks.
ToolACE: Winning the Points of LLM Function Calling
Sep 02, 2024



Function calling significantly extends the application boundary of large language models, where high-quality and diverse training data is critical for unlocking this capability. However, real function-calling data is quite challenging to collect and annotate, while synthetic data generated by existing pipelines tends to lack coverage and accuracy. In this paper, we present ToolACE, an automatic agentic pipeline designed to generate accurate, complex, and diverse tool-learning data. ToolACE leverages a novel self-evolution synthesis process to curate a comprehensive API pool of 26,507 diverse APIs. Dialogs are further generated through the interplay among multiple agents, guided by a formalized thinking process. To ensure data accuracy, we implement a dual-layer verification system combining rule-based and model-based checks. We demonstrate that models trained on our synthesized data, even with only 8B parameters, achieve state-of-the-art performance on the Berkeley Function-Calling Leaderboard, rivaling the latest GPT-4 models. Our model and a subset of the data are publicly available at https://huggingface.co/Team-ACE.