 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolFlow: Boosting LLM Tool-Calling Through Natural and Coherent Dialogue Synthesis
Paper and Code
Oct 24, 2024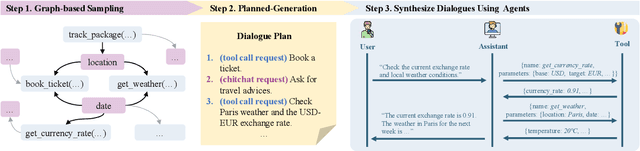
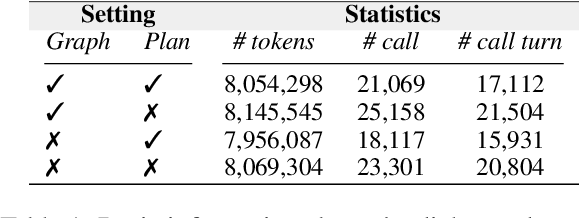


Supervised fine-tuning (SFT) is a common method to enhance the tool calling capabilities of Large Language Models (LLMs), with the training data often being synthesized. The current data synthesis process generally involves sampling a set of tools, formulating a requirement based on these tools, and generating the call statements. However, tools sampled randomly lack relevance, making them difficult to combine and thus reducing the diversity of the data. Additionally, current work overlooks the coherence between turns of dialogues, leading to a gap between the synthesized data and real-world scenarios. To address these issues, we propose a Graph-based Sampling strategy to sample more relevant tool combinations, and a Planned-generation strategy to create plans that guide the synthesis of coherent dialogues. We integrate these two strategies and enable multiple agents to synthesize the dialogue data interactively, resulting in our tool-calling data synthesis pipeline ToolFlow. Data quality assessments demonstrate improvements in the naturalness and coherence of our synthesized dialogues. Finally, we apply SFT on LLaMA-3.1-8B using 8,000 synthetic dialogues generated with ToolFlow. Results show that the model achieves tool-calling performance comparable to or even surpassing GPT-4, while maintaining strong general capabilities.