 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Auxiliary Constraints to Resolve Instruction Following in Large Reasoning Models
Jun 02, 2026Large Reasoning Models (LRMs) have demonstrated impressive capabilities in many tasks, yet they struggle with reliably following multiple instructions, either by failing to satisfy individual constraints or by struggling to balance competing constraints simultaneously. We formalize this challenge as the Constraint Adherence Problem (CAP). This paper introduces a novel framework that addresses CAP by representing instructions as a structured knowledge graph of constraints. Our approach, Constraint Relationship Graph Completion (CRGC), explicitly models relationships between constraints, identifies adherence challenges, and discovers ``bridge constraints'' that help the model better focus on and reconcile requirements. Bridge constraints act as auxiliary instructions that make primary constraints more salient and compatible. Unlike existing approaches that enhance instruction following through general training methods, CRGC specifically improves constraint satisfaction by leveraging the model's own knowledge to create better pathways for generation. Experiments across three popular instruction following datasets demonstrate that our approach reduces constraint violations by 39% compared to standard prompting while maintaining reasoning abilities of large reasoning models.
Beyond the Literal: Decomposing Pragmatic Intent in Multimodal Meme Understanding
Jun 02, 2026When asked what a meme or sarcastic post means, Large Vision Language Models (LVLMs) tend to describe what the image shows rather than what the author is trying to communicate. Standard instruction tuning entangles a post's literal content with its pragmatic meaning, letting surface-level details contaminate the final response. We reframe meme understanding as a problem of literal-pragmatic decomposition and propose \textbf{Intent Projection}, a framework that separates the two signals at the representation, output, and objective levels within a single LVLM backbone. At the representation level, an orthogonal projection module removes dominant unimodal directions from the fused image-text representation, retaining only the pragmatic residual, while a surface-real affect classifier anchors the decoder with a discrete tag that names the polarity gap. At the output level, the model externalizes a structured reasoning chain, and at the objective level a contrastive reward explicitly penalizes answers that restate the literal description. Across six multimodal benchmarks, Intent Projection consistently outperforms open-source baselines and narrows the gap to proprietary models, with the largest gains on high-divergence posts where literal collapse is most damaging.
AllocMV: Optimal Resource Allocation for Music Video Generation via Structured Persistent State
May 11, 2026Generating long-horizon music videos (MVs) is frequently constrained by prohibitive computational costs and difficulty maintaining cross-shot consistency. We propose AllocMV, a hierarchical framework formulating music video synthesis as a Multiple-Choice Knapsack Problem (MCKP). AllocMV represents the video's persistent state as a compact, structured object comprising character entities, scene priors, and sharing graphs, produced by a global planner prior to realization. By estimating segment saliency from multimodal cues, a group-level MCKP solver based on dynamic programming optimally allocates resources across High-Gen, Mid-Gen, and Reuse branches. For repetitive musical motifs, we implement a divergence-based forking strategy that reuses visual prefixes to reduce costs while ensuring motif-level continuity. Evaluated via the Cost-Quality Ratio (CQR), AllocMV achieves an optimal trade-off between perceived quality and resource expenditure under strict budgetary and rhythmic constraints.
ReflectDrive-2: Reinforcement-Learning-Aligned Self-Editing for Discrete Diffusion Driving
May 06, 2026We introduce ReflectDrive-2, a masked discrete diffusion planner with separate action expert for autonomous driving that represents plans as discrete trajectory tokens and generates them through parallel masked decoding. This discrete token space enables in-place trajectory revision: AutoEdit rewrites selected tokens using the same model, without requiring an auxiliary refinement network. To train this capability, we use a two-stage procedure. First, we construct structure-aware perturbations of expert trajectories along longitudinal progress and lateral heading directions and supervise the model to recover the original expert trajectory. We then fine-tune the full decision--draft--reflect rollout with reinforcement learning (RL), assigning terminal driving reward to the final post-edit trajectory and propagating policy-gradient credit through full-rollout transitions. Full-rollout RL proves crucial for coupling drafting and editing: under supervised training alone, inference-time AutoEdit improves PDMS by at most $0.3$, whereas RL increases its gain to $1.9$. We also co-design an efficient reflective decoding stack for the decision--draft--reflect pipeline, combining shared-prefix KV reuse, Alternating Step Decode, and fused on-device unmasking. On NAVSIM, ReflectDrive-2 achieves $91.0$ PDMS with camera-only input and $94.8$ PDMS in a best-of-6 oracle setting, while running at $31.8$ ms average latency on NVIDIA Thor.
Guaranteeing Knowledge Integration with Joint Decoding for Retrieval-Augmented Generation
Apr 09, 2026Retrieval-Augmented Generation (RAG) significantly enhances Large Language Models (LLMs) by providing access to external knowledge. However, current research primarily focuses on retrieval quality, often overlooking the critical ''integration bottleneck'': even when relevant documents are retrieved, LLMs frequently fail to utilize them effectively due to conflicts with their internal parametric knowledge. In this paper, we argue that implicitly resolving this conflict in a single generation pass is suboptimal. We introduce GuarantRAG, a framework that explicitly decouples reasoning from evidence integration. First, we generate an ''Inner-Answer'' based solely on parametric knowledge to capture the model's reasoning flow. Second, to guarantee faithful evidence extraction, we generate a ''Refer-Answer'' using a novel Contrastive DPO objective. This objective treats the parametric Inner-Answer as a negative constraint and the retrieved documents as positive ground truth, forcing the model to suppress internal hallucinations in favor of external evidence during this phase. Finally, rather than naive concatenation or using the DPO trained model directly, we propose a joint decoding mechanism that dynamically fuses the logical coherence of the Inner-Answer with the factual precision of the Refer-Answer at the token level. Experiments on five QA benchmarks demonstrate that GuarantRAG improves accuracy by up to 12.1% and reduces hallucinations by 16.3% compared to standard and dynamic RAG baselines.
Dual-Density Inference for Efficient Language Model Reasoning
Dec 17, 2025
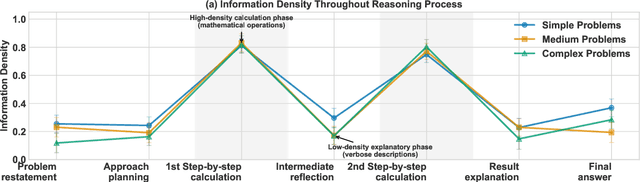
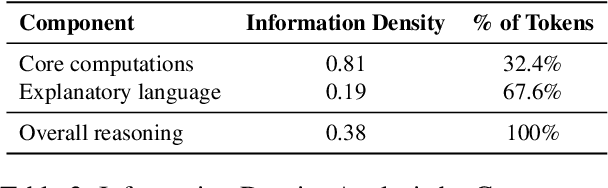
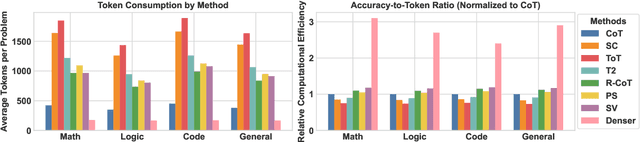
Large Language Models (LLMs) have shown impressive capabilities in complex reasoning tasks. However, current approaches employ uniform language density for both intermediate reasoning and final answers, leading to computational inefficiency. Our observation found that reasoning process serves a computational function for the model itself, while answering serves a communicative function for human understanding. This distinction enables the use of compressed, symbol-rich language for intermediate computations while maintaining human-readable final explanations. To address this inefficiency, we present Denser: \underline{D}ual-d\underline{ens}ity inf\underline{er}ence, a novel framework that optimizes information density separately for reasoning and answering phases. Our framework implements this through three components: a query processing module that analyzes input problems, a high-density compressed reasoning mechanism for efficient intermediate computations, and an answer generation component that translates compressed reasoning into human-readable solutions. Experimental evaluation across multiple reasoning question answering benchmarks demonstrates that Denser reduces token consumption by up to 62\% compared to standard Chain-of-Thought methods while preserving or improving accuracy. These efficiency gains are particularly significant for complex multi-step reasoning problems where traditional methods generate extensive explanations.
MemeReaCon: Probing Contextual Meme Understanding in Large Vision-Language Models
May 23, 2025Memes have emerged as a popular form of multimodal online communication, where their interpretation heavily depends on the specific context in which they appear. Current approaches predominantly focus on isolated meme analysis, either for harmful content detection or standalone interpretation, overlooking a fundamental challenge: the same meme can express different intents depending on its conversational context. This oversight creates an evaluation gap: although humans intuitively recognize how context shapes meme interpretation, Large Vision Language Models (LVLMs) can hardly understand context-dependent meme intent. To address this critical limitation, we introduce MemeReaCon, a novel benchmark specifically designed to evaluate how LVLMs understand memes in their original context. We collected memes from five different Reddit communities, keeping each meme's image, the post text, and user comments together. We carefully labeled how the text and meme work together, what the poster intended, how the meme is structured, and how the community responded. Our tests with leading LVLMs show a clear weakness: models either fail to interpret critical information in the contexts, or overly focus on visual details while overlooking communicative purpose. MemeReaCon thus serves both as a diagnostic tool exposing current limitations and as a challenging benchmark to drive development toward more sophisticated LVLMs of the context-aware understanding.
T$^2$: An Adaptive Test-Time Scaling Strategy for Contextual Question Answering
May 23, 2025Recent advances in Large Language Models (LLMs) have demonstrated remarkable performance in Contextual Question Answering (CQA). However, prior approaches typically employ elaborate reasoning strategies regardless of question complexity, leading to low adaptability. Recent efficient test-time scaling methods introduce budget constraints or early stop mechanisms to avoid overthinking for straightforward questions. But they add human bias to the reasoning process and fail to leverage models' inherent reasoning capabilities. To address these limitations, we present T$^2$: Think-to-Think, a novel framework that dynamically adapts reasoning depth based on question complexity. T$^2$ leverages the insight that if an LLM can effectively solve similar questions using specific reasoning strategies, it can apply the same strategy to the original question. This insight enables to adoption of concise reasoning for straightforward questions while maintaining detailed analysis for complex problems. T$^2$ works through four key steps: decomposing questions into structural elements, generating similar examples with candidate reasoning strategies, evaluating these strategies against multiple criteria, and applying the most appropriate strategy to the original question. Experimental evaluation across seven diverse CQA benchmarks demonstrates that T$^2$ not only achieves higher accuracy than baseline methods but also reduces computational overhead by up to 25.2\%.
Generalizing Motion Planners with Mixture of Experts for Autonomous Driving
Oct 21, 2024



Large real-world driving datasets have sparked significant research into various aspects of data-driven motion planners for autonomous driving. These include data augmentation, model architecture, reward design, training strategies, and planner pipelines. These planners promise better generalizations on complicated and few-shot cases than previous methods. However, experiment results show that many of these approaches produce limited generalization abilities in planning performance due to overly complex designs or training paradigms. In this paper, we review and benchmark previous methods focusing on generalizations. The experimental results indicate that as models are appropriately scaled, many design elements become redundant. We introduce StateTransformer-2 (STR2), a scalable, decoder-only motion planner that uses a Vision Transformer (ViT) encoder and a mixture-of-experts (MoE) causal Transformer architecture. The MoE backbone addresses modality collapse and reward balancing by expert routing during training. Extensive experiments on the NuPlan dataset show that our method generalizes better than previous approaches across different test sets and closed-loop simulations. Furthermore, we assess its scalability on billions of real-world urban driving scenarios, demonstrating consistent accuracy improvements as both data and model size grow.
Self-DC: When to retrieve and When to generate? Self Divide-and-Conquer for Compositional Unknown Questions
Feb 21, 2024



Retrieve-then-read and generate-then-read are two typical solutions to handle unknown and known questions in open-domain question-answering, while the former retrieves necessary external knowledge and the later prompt the large language models to generate internal known knowledge encoded in the parameters. However, few of previous works consider the compositional unknown questions, which consist of several known or unknown sub-questions. Thus, simple binary classification (known or unknown) becomes sub-optimal and inefficient since it will call external retrieval excessively for each compositional unknown question. To this end, we propose the first Compositional unknown Question-Answering dataset (CuQA), and introduce a Self Divide-and-Conquer (Self-DC) framework to empower LLMs to adaptively call different methods on-demand, resulting in better performance and efficiency. Experimental results on two datasets (CuQA and FreshQA) demonstrate that Self-DC can achieve comparable or even better performance with much more less retrieval times compared with several strong baselines.