 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes Interaction Trajectories Effective for Training Terminal Agents?
Jun 02, 2026Stronger code agents are commonly assumed to be superior teachers for post-training, yet this assumption remains poorly disentangled from task difficulty, harness design, and student capacity. We investigate this pedagogical link using Terminal-Lego, a scalable pipeline that transforms multi-domain real-world issues into environment-verified agentic tasks. Surprisingly, standalone performance does not dictate teaching efficacy: while Claude Opus 4.6 achieves higher scores on Terminal-Bench 2.0, students fine-tuned on trajectories from DeepSeek-V3.2, a lower-scoring agent, exhibit significantly stronger generalization. We attribute this "pedagogical paradox" to Environment-Grounded Supervision (EGS): trajectories that explicitly expose inspect-act-verify behaviors through harness-visible interactions allow students to internalize robust problem-solving routines rather than fragile action sequences. Scaling analysis reveals exceptional data efficiency: with only 15.3k Terminal-Lego trajectories, for example, Qwen3-32B achieves a 24.3% score on Terminal-Bench 2.0, rivaling previous SOTA performance established with over 30x the data volume. Our results suggest that the frontier of agent post-training lies beyond mere outcome-matching, shifting the focus toward "Harness Engineering", where the systematic design of environment-grounded interaction structures serves as the primary catalyst for reproducible and generalizable agentic intelligence.
Can Retrieval Heads See Images? Multimodal Retrieval Heads in Long-Context Vision-Language Models
May 26, 2026Large vision-language models increasingly rely on long-context modeling to reason over documents, hour-level videos, and long-horizon agent trajectories, requiring them to locate relevant evidence across interleaved text and images. Prior work has studied this behavior using retrieval heads in large language models, but its copy-based criterion does not directly apply when evidence appears in images. We introduce a multimodal retrieval head detection method that scores attention from question tokens to textual or visual evidence. With this method, we show that multimodal retrieval heads are sparse, intrinsic, and causally important: only 4.4-10.2% of attention heads account for 50% of the positive retrieval-score mass, and masking the top-5% selected heads drops MMLongBench-Doc from 48.2% to 5.7% and SlideVQA from 71.2% to 8.9%, while random-head masking is far less damaging. Further analysis shows that these heads are partly shared across modalities yet remain dynamic within each modality, with image retrieval heads changing more than text retrieval heads as context length and haystack modality change. Without further training, we find that these heads can also be used directly to rank visually rich documents: on MMDocIR, Qwen3-VL-8B selected-head scoring improves Recall@1 by 7.7/7.4 macro/micro points for page retrieval and 6.3/6.8 points for layout retrieval over the strongest reported baseline.
MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
May 14, 2026Memory is essential for large vision-language models (LVLMs) to handle long, multimodal interactions, with two method directions providing this capability: long-context LVLMs and memory-augmented agents. However, no existing benchmark conducts a systematic comparison of the two on questions that genuinely require multimodal evidence. To close this gap, we introduce MEMLENS, a comprehensive benchmark for memory in multimodal multi-session conversations, comprising 789 questions across five memory abilities (information extraction, multi-session reasoning, temporal reasoning, knowledge update, and answer refusal) at four standard context lengths (32K-256K tokens) under a cross-modal token-counting scheme. An image-ablation study confirms that solving MEMLENS requires visual evidence: removing evidence images drops two frontier LVLMs below 2% accuracy on the 80.4% of questions whose evidence includes images. Evaluating 27 LVLMs and 7 memory-augmented agents, we find that long-context LVLMs achieve high short-context accuracy through direct visual grounding but degrade as conversations grow, whereas memory agents are length-stable but lose visual fidelity under storage-time compression. Multi-session reasoning caps most systems below 30%, and neither approach alone solves the task. These results motivate hybrid architectures that combine long-context attention with structured multimodal retrieval. Our code is available at https://github.com/xrenaf/MEMLENS.
Deep Incomplete Multi-View Clustering via Hierarchical Imputation and Alignment
Jan 14, 2026Incomplete multi-view clustering (IMVC) aims to discover shared cluster structures from multi-view data with partial observations. The core challenges lie in accurately imputing missing views without introducing bias, while maintaining semantic consistency across views and compactness within clusters. To address these challenges, we propose DIMVC-HIA, a novel deep IMVC framework that integrates hierarchical imputation and alignment with four key components: (1) view-specific autoencoders for latent feature extraction, coupled with a view-shared clustering predictor to produce soft cluster assignments; (2) a hierarchical imputation module that first estimates missing cluster assignments based on cross-view contrastive similarity, and then reconstructs missing features using intra-view, intra-cluster statistics; (3) an energy-based semantic alignment module, which promotes intra-cluster compactness by minimizing energy variance around low-energy cluster anchors; and (4) a contrastive assignment alignment module, which enhances cross-view consistency and encourages confident, well-separated cluster predictions. Experiments on benchmarks demonstrate that our framework achieves superior performance under varying levels of missingness.
SWE-Lego: Pushing the Limits of Supervised Fine-tuning for Software Issue Resolving
Jan 07, 2026We present SWE-Lego, a supervised fine-tuning (SFT) recipe designed to achieve state-ofthe-art performance in software engineering (SWE) issue resolving. In contrast to prevalent methods that rely on complex training paradigms (e.g., mid-training, SFT, reinforcement learning, and their combinations), we explore how to push the limits of a lightweight SFT-only approach for SWE tasks. SWE-Lego comprises three core building blocks, with key findings summarized as follows: 1) the SWE-Lego dataset, a collection of 32k highquality task instances and 18k validated trajectories, combining real and synthetic data to complement each other in both quality and quantity; 2) a refined SFT procedure with error masking and a difficulty-based curriculum, which demonstrably improves action quality and overall performance. Empirical results show that with these two building bricks alone,the SFT can push SWE-Lego models to state-of-the-art performance among open-source models of comparable size on SWE-bench Verified: SWE-Lego-Qwen3-8B reaches 42.2%, and SWE-Lego-Qwen3-32B attains 52.6%. 3) We further evaluate and improve test-time scaling (TTS) built upon the SFT foundation. Based on a well-trained verifier, SWE-Lego models can be significantly boosted--for example, 42.2% to 49.6% and 52.6% to 58.8% under TTS@16 for the 8B and 32B models, respectively.
Memory-T1: Reinforcement Learning for Temporal Reasoning in Multi-session Agents
Dec 23, 2025Temporal reasoning over long, multi-session dialogues is a critical capability for conversational agents. However, existing works and our pilot study have shown that as dialogue histories grow in length and accumulate noise, current long-context models struggle to accurately identify temporally pertinent information, significantly impairing reasoning performance. To address this, we introduce Memory-T1, a framework that learns a time-aware memory selection policy using reinforcement learning (RL). It employs a coarse-to-fine strategy, first pruning the dialogue history into a candidate set using temporal and relevance filters, followed by an RL agent that selects the precise evidence sessions. The RL training is guided by a multi-level reward function optimizing (i) answer accuracy, (ii) evidence grounding, and (iii) temporal consistency. In particular, the temporal consistency reward provides a dense signal by evaluating alignment with the query time scope at both the session-level (chronological proximity) and the utterance-level (chronological fidelity), enabling the agent to resolve subtle chronological ambiguities. On the Time-Dialog benchmark, Memory-T1 boosts a 7B model to an overall score of 67.0\%, establishing a new state-of-the-art performance for open-source models and outperforming a 14B baseline by 10.2\%. Ablation studies show temporal consistency and evidence grounding rewards jointly contribute to a 15.0\% performance gain. Moreover, Memory-T1 maintains robustness up to 128k tokens, where baseline models collapse, proving effectiveness against noise in extensive dialogue histories. The code and datasets are publicly available at https://github.com/Elvin-Yiming-Du/Memory-T1/
ReSURE: Regularizing Supervision Unreliability for Multi-turn Dialogue Fine-tuning
Aug 27, 2025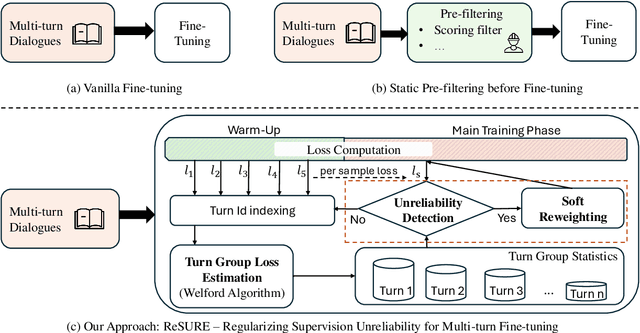
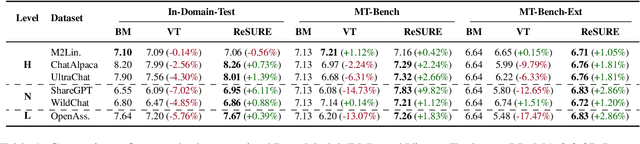
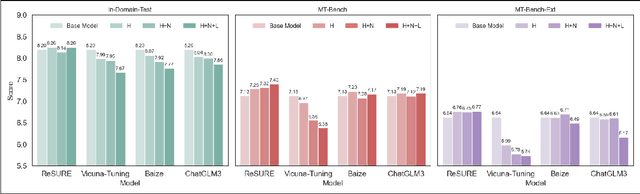
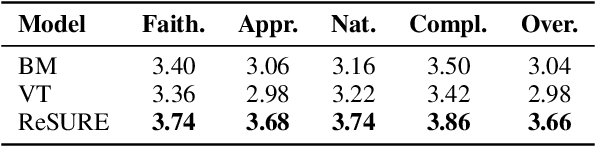
Fine-tuning multi-turn dialogue systems requires high-quality supervision but often suffers from degraded performance when exposed to low-quality data. Supervision errors in early turns can propagate across subsequent turns, undermining coherence and response quality. Existing methods typically address data quality via static prefiltering, which decouples quality control from training and fails to mitigate turn-level error propagation. In this context, we propose ReSURE (Regularizing Supervision UnREliability), an adaptive learning method that dynamically down-weights unreliable supervision without explicit filtering. ReSURE estimates per-turn loss distributions using Welford's online statistics and reweights sample losses on the fly accordingly. Experiments on both single-source and mixed-quality datasets show improved stability and response quality. Notably, ReSURE enjoys positive Spearman correlations (0.21 ~ 1.0 across multiple benchmarks) between response scores and number of samples regardless of data quality, which potentially paves the way for utilizing large-scale data effectively. Code is publicly available at https://github.com/Elvin-Yiming-Du/ReSURE_Multi_Turn_Training.
Bridging the Long-Term Gap: A Memory-Active Policy for Multi-Session Task-Oriented Dialogue
May 26, 2025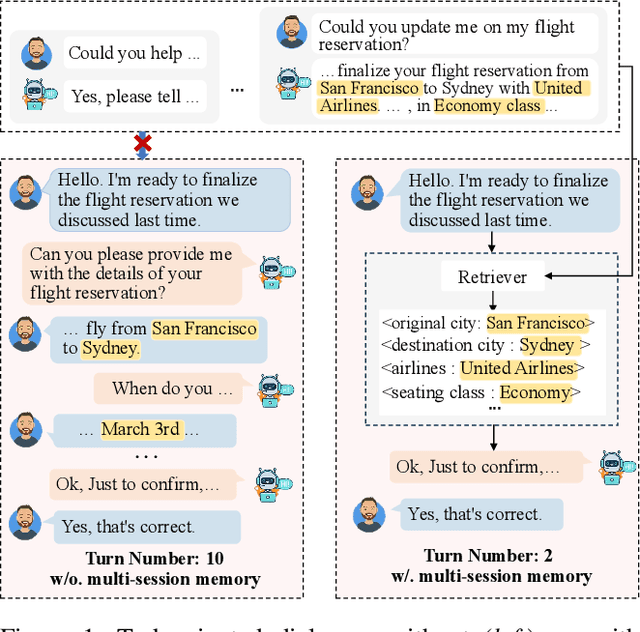
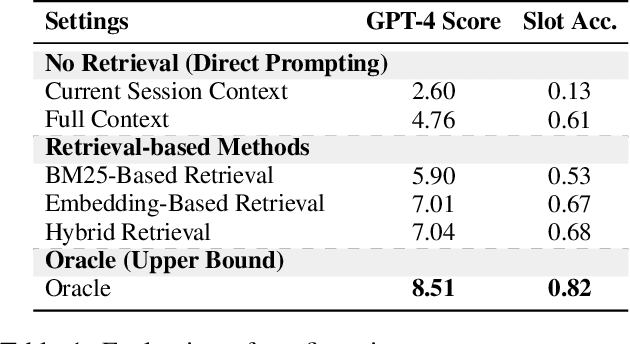
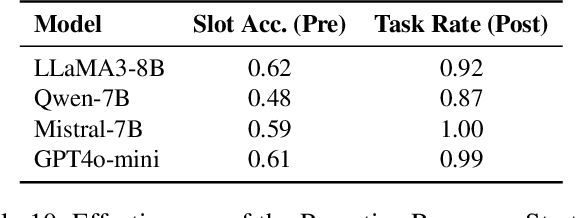
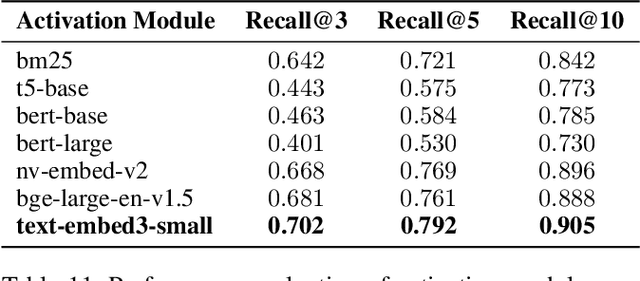
Existing Task-Oriented Dialogue (TOD) systems primarily focus on single-session dialogues, limiting their effectiveness in long-term memory augmentation. To address this challenge, we introduce a MS-TOD dataset, the first multi-session TOD dataset designed to retain long-term memory across sessions, enabling fewer turns and more efficient task completion. This defines a new benchmark task for evaluating long-term memory in multi-session TOD. Based on this new dataset, we propose a Memory-Active Policy (MAP) that improves multi-session dialogue efficiency through a two-stage approach. 1) Memory-Guided Dialogue Planning retrieves intent-aligned history, identifies key QA units via a memory judger, refines them by removing redundant questions, and generates responses based on the reconstructed memory. 2) Proactive Response Strategy detects and correct errors or omissions, ensuring efficient and accurate task completion. We evaluate MAP on MS-TOD dataset, focusing on response quality and effectiveness of the proactive strategy. Experiments on MS-TOD demonstrate that MAP significantly improves task success and turn efficiency in multi-session scenarios, while maintaining competitive performance on conventional single-session tasks.
Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions
May 01, 2025Memory is a fundamental component of AI systems, underpinning large language models (LLMs) based agents. While prior surveys have focused on memory applications with LLMs, they often overlook the atomic operations that underlie memory dynamics. In this survey, we first categorize memory representations into parametric, contextual structured, and contextual unstructured and then introduce six fundamental memory operations: Consolidation, Updating, Indexing, Forgetting, Retrieval, and Compression. We systematically map these operations to the most relevant research topics across long-term, long-context, parametric modification, and multi-source memory. By reframing memory systems through the lens of atomic operations and representation types, this survey provides a structured and dynamic perspective on research, benchmark datasets, and tools related to memory in AI, clarifying the functional interplay in LLMs based agents while outlining promising directions for future research\footnote{The paper list, datasets, methods and tools are available at \href{https://github.com/Elvin-Yiming-Du/Survey_Memory_in_AI}{https://github.com/Elvin-Yiming-Du/Survey\_Memory\_in\_AI}.}.
EventWeave: A Dynamic Framework for Capturing Core and Supporting Events in Dialogue Systems
Mar 29, 2025Existing large language models (LLMs) have shown remarkable progress in dialogue systems. However, many approaches still overlook the fundamental role of events throughout multi-turn interactions, leading to \textbf{incomplete context tracking}. Without tracking these events, dialogue systems often lose coherence and miss subtle shifts in user intent, causing disjointed responses. To bridge this gap, we present \textbf{EventWeave}, an event-centric framework that identifies and updates both core and supporting events as the conversation unfolds. Specifically, we organize these events into a dynamic event graph, which represents the interplay between \textbf{core events} that shape the primary idea and \textbf{supporting events} that provide critical context during the whole dialogue. By leveraging this dynamic graph, EventWeave helps models focus on the most relevant events when generating responses, thus avoiding repeated visits of the entire dialogue history. Experimental results on two benchmark datasets show that EventWeave improves response quality and event relevance without fine-tuning.