 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-T1: Reinforcement Learning for Temporal Reasoning in Multi-session Agents
Dec 23, 2025Temporal reasoning over long, multi-session dialogues is a critical capability for conversational agents. However, existing works and our pilot study have shown that as dialogue histories grow in length and accumulate noise, current long-context models struggle to accurately identify temporally pertinent information, significantly impairing reasoning performance. To address this, we introduce Memory-T1, a framework that learns a time-aware memory selection policy using reinforcement learning (RL). It employs a coarse-to-fine strategy, first pruning the dialogue history into a candidate set using temporal and relevance filters, followed by an RL agent that selects the precise evidence sessions. The RL training is guided by a multi-level reward function optimizing (i) answer accuracy, (ii) evidence grounding, and (iii) temporal consistency. In particular, the temporal consistency reward provides a dense signal by evaluating alignment with the query time scope at both the session-level (chronological proximity) and the utterance-level (chronological fidelity), enabling the agent to resolve subtle chronological ambiguities. On the Time-Dialog benchmark, Memory-T1 boosts a 7B model to an overall score of 67.0\%, establishing a new state-of-the-art performance for open-source models and outperforming a 14B baseline by 10.2\%. Ablation studies show temporal consistency and evidence grounding rewards jointly contribute to a 15.0\% performance gain. Moreover, Memory-T1 maintains robustness up to 128k tokens, where baseline models collapse, proving effectiveness against noise in extensive dialogue histories. The code and datasets are publicly available at https://github.com/Elvin-Yiming-Du/Memory-T1/
Self-Error-Instruct: Generalizing from Errors for LLMs Mathematical Reasoning
May 28, 2025
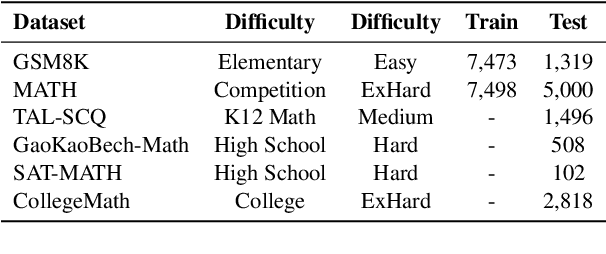

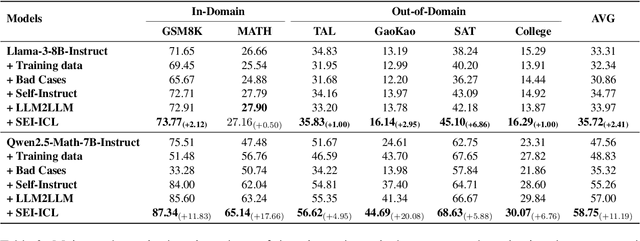
Although large language models demonstrate strong performance across various domains, they still struggle with numerous bad cases in mathematical reasoning. Previous approaches to learning from errors synthesize training data by solely extrapolating from isolated bad cases, thereby failing to generalize the extensive patterns inherent within these cases. This paper presents Self-Error-Instruct (SEI), a framework that addresses these model weaknesses and synthesizes more generalized targeted training data. Specifically, we explore a target model on two mathematical datasets, GSM8K and MATH, to pinpoint bad cases. Then, we generate error keyphrases for these cases based on the instructor model's (GPT-4o) analysis and identify error types by clustering these keyphrases. Next, we sample a few bad cases during each generation for each identified error type and input them into the instructor model, which synthesizes additional training data using a self-instruct approach. This new data is refined through a one-shot learning process to ensure that only the most effective examples are kept. Finally, we use these curated data to fine-tune the target model, iteratively repeating the process to enhance performance. We apply our framework to various models and observe improvements in their reasoning abilities across both in-domain and out-of-domain mathematics datasets. These results demonstrate the effectiveness of self-error instruction in improving LLMs' mathematical reasoning through error generalization.
Bridging the Long-Term Gap: A Memory-Active Policy for Multi-Session Task-Oriented Dialogue
May 26, 2025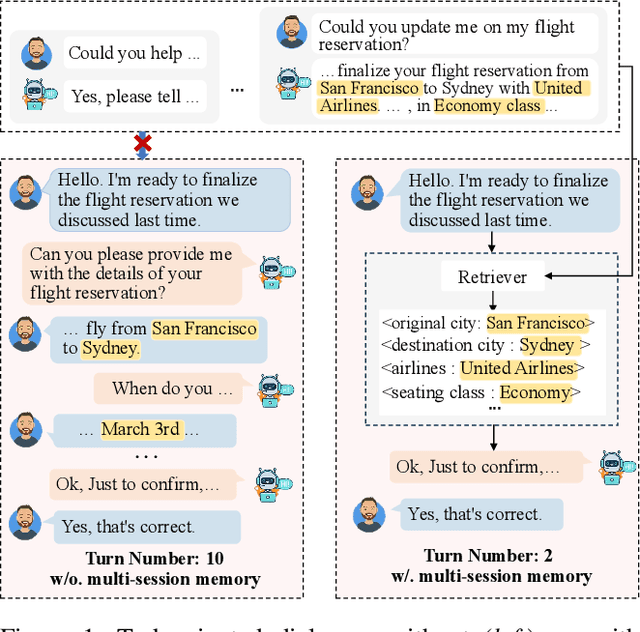
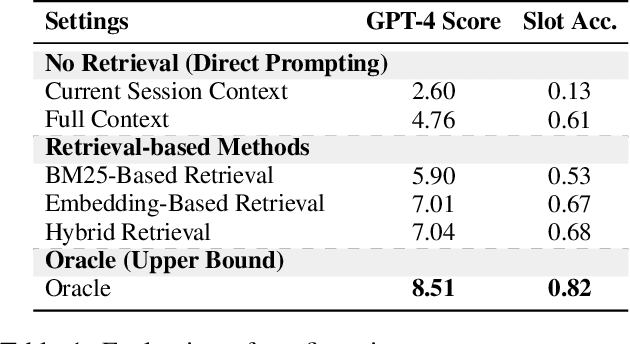
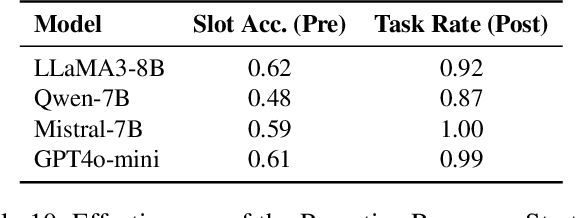
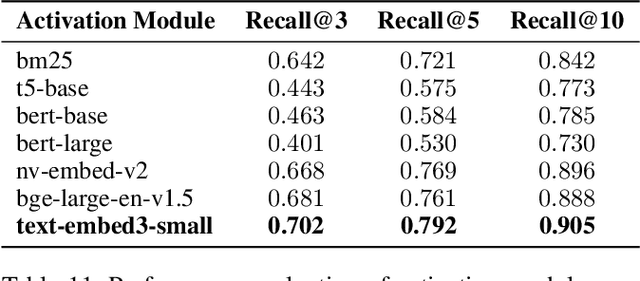
Existing Task-Oriented Dialogue (TOD) systems primarily focus on single-session dialogues, limiting their effectiveness in long-term memory augmentation. To address this challenge, we introduce a MS-TOD dataset, the first multi-session TOD dataset designed to retain long-term memory across sessions, enabling fewer turns and more efficient task completion. This defines a new benchmark task for evaluating long-term memory in multi-session TOD. Based on this new dataset, we propose a Memory-Active Policy (MAP) that improves multi-session dialogue efficiency through a two-stage approach. 1) Memory-Guided Dialogue Planning retrieves intent-aligned history, identifies key QA units via a memory judger, refines them by removing redundant questions, and generates responses based on the reconstructed memory. 2) Proactive Response Strategy detects and correct errors or omissions, ensuring efficient and accurate task completion. We evaluate MAP on MS-TOD dataset, focusing on response quality and effectiveness of the proactive strategy. Experiments on MS-TOD demonstrate that MAP significantly improves task success and turn efficiency in multi-session scenarios, while maintaining competitive performance on conventional single-session tasks.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
EventWeave: A Dynamic Framework for Capturing Core and Supporting Events in Dialogue Systems
Mar 29, 2025Existing large language models (LLMs) have shown remarkable progress in dialogue systems. However, many approaches still overlook the fundamental role of events throughout multi-turn interactions, leading to \textbf{incomplete context tracking}. Without tracking these events, dialogue systems often lose coherence and miss subtle shifts in user intent, causing disjointed responses. To bridge this gap, we present \textbf{EventWeave}, an event-centric framework that identifies and updates both core and supporting events as the conversation unfolds. Specifically, we organize these events into a dynamic event graph, which represents the interplay between \textbf{core events} that shape the primary idea and \textbf{supporting events} that provide critical context during the whole dialogue. By leveraging this dynamic graph, EventWeave helps models focus on the most relevant events when generating responses, thus avoiding repeated visits of the entire dialogue history. Experimental results on two benchmark datasets show that EventWeave improves response quality and event relevance without fine-tuning.
PerLTQA: A Personal Long-Term Memory Dataset for Memory Classification, Retrieval, and Synthesis in Question Answering
Feb 26, 2024Long-term memory plays a critical role in personal interaction, considering long-term memory can better leverage world knowledge, historical information, and preferences in dialogues. Our research introduces PerLTQA, an innovative QA dataset that combines semantic and episodic memories, including world knowledge, profiles, social relationships, events, and dialogues. This dataset is collected to investigate the use of personalized memories, focusing on social interactions and events in the QA task. PerLTQA features two types of memory and a comprehensive benchmark of 8,593 questions for 30 characters, facilitating the exploration and application of personalized memories in Large Language Models (LLMs). Based on PerLTQA, we propose a novel framework for memory integration and generation, consisting of three main components: Memory Classification, Memory Retrieval, and Memory Synthesis. We evaluate this framework using five LLMs and three retrievers. Experimental results demonstrate that BERT-based classification models significantly outperform LLMs such as ChatGLM3 and ChatGPT in the memory classification task. Furthermore, our study highlights the importance of effective memory integration in the QA task.
YODA: Teacher-Student Progressive Learning for Language Models
Jan 28, 2024



Although large language models (LLMs) have demonstrated adeptness in a range of tasks, they still lag behind human learning efficiency. This disparity is often linked to the inherent human capacity to learn from basic examples, gradually generalize and handle more complex problems, and refine their skills with continuous feedback. Inspired by this, this paper introduces YODA, a novel teacher-student progressive learning framework that emulates the teacher-student education process to improve the efficacy of model fine-tuning. The framework operates on an interactive \textit{basic-generalized-harder} loop. The teacher agent provides tailored feedback on the student's answers, and systematically organizes the education process. This process unfolds by teaching the student basic examples, reinforcing understanding through generalized questions, and then enhancing learning by posing questions with progressively enhanced complexity. With the teacher's guidance, the student learns to iteratively refine its answer with feedback, and forms a robust and comprehensive understanding of the posed questions. The systematic procedural data, which reflects the progressive learning process of humans, is then utilized for model training. Taking math reasoning as a testbed, experiments show that training LLaMA2 with data from YODA improves SFT with significant performance gain (+17.01\% on GSM8K and +9.98\% on MATH). In addition, we find that training with curriculum learning further improves learning robustness.
Data Management For Large Language Models: A Survey
Dec 04, 2023



Data plays a fundamental role in the training of Large Language Models (LLMs). Effective data management, particularly in the formulation of a well-suited training dataset, holds significance for enhancing model performance and improving training efficiency during pretraining and supervised fine-tuning phases. Despite the considerable importance of data management, the current research community still falls short in providing a systematic analysis of the rationale behind management strategy selection, its consequential effects, methodologies for evaluating curated datasets, and the ongoing pursuit of improved strategies. Consequently, the exploration of data management has attracted more and more attention among the research community. This survey provides a comprehensive overview of current research in data management within both the pretraining and supervised fine-tuning stages of LLMs, covering various noteworthy aspects of data management strategy design: data quantity, data quality, domain/task composition, etc. Looking toward the future, we extrapolate existing challenges and outline promising directions for development in this field. Therefore, this survey serves as a guiding resource for practitioners aspiring to construct powerful LLMs through effective data management practices. The collection of the latest papers is available at https://github.com/ZigeW/data_management_LLM.
Exploring the Usage of Chinese Pinyin in Pretraining
Oct 08, 2023Unlike alphabetic languages, Chinese spelling and pronunciation are different. Both characters and pinyin take an important role in Chinese language understanding. In Chinese NLP tasks, we almost adopt characters or words as model input, and few works study how to use pinyin. However, pinyin is essential in many scenarios, such as error correction and fault tolerance for ASR-introduced errors. Most of these errors are caused by the same or similar pronunciation words, and we refer to this type of error as SSP(the same or similar pronunciation) errors for short. In this work, we explore various ways of using pinyin in pretraining models and propose a new pretraining method called PmBERT. Our method uses characters and pinyin in parallel for pretraining. Through delicate pretraining tasks, the characters and pinyin representation are fused, which can enhance the error tolerance for SSP errors. We do comprehensive experiments and ablation tests to explore what makes a robust phonetic enhanced Chinese language model. The experimental results on both the constructed noise-added dataset and the public error-correction dataset demonstrate that our model is more robust compared to SOTA models.
Zero-shot Cross-lingual Transfer without Parallel Corpus
Oct 07, 2023



Recently, although pre-trained language models have achieved great success on multilingual NLP (Natural Language Processing) tasks, the lack of training data on many tasks in low-resource languages still limits their performance. One effective way of solving that problem is to transfer knowledge from rich-resource languages to low-resource languages. However, many previous works on cross-lingual transfer rely heavily on the parallel corpus or translation models, which are often difficult to obtain. We propose a novel approach to conduct zero-shot cross-lingual transfer with a pre-trained model. It consists of a Bilingual Task Fitting module that applies task-related bilingual information alignment; a self-training module generates pseudo soft and hard labels for unlabeled data and utilizes them to conduct self-training. We got the new SOTA on different tasks without any dependencies on the parallel corpus or translation models.