 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAST: Compositional Analysis via Spectral Tracking for Understanding Transformer Layer Functions
Oct 16, 2025Large language models have achieved remarkable success but remain largely black boxes with poorly understood internal mechanisms. To address this limitation, many researchers have proposed various interpretability methods including mechanistic analysis, probing classifiers, and activation visualization, each providing valuable insights from different perspectives. Building upon this rich landscape of complementary approaches, we introduce CAST (Compositional Analysis via Spectral Tracking), a probe-free framework that contributes a novel perspective by analyzing transformer layer functions through direct transformation matrix estimation and comprehensive spectral analysis. CAST offers complementary insights to existing methods by estimating the realized transformation matrices for each layer using Moore-Penrose pseudoinverse and applying spectral analysis with six interpretable metrics characterizing layer behavior. Our analysis reveals distinct behaviors between encoder-only and decoder-only models, with decoder models exhibiting compression-expansion cycles while encoder models maintain consistent high-rank processing. Kernel analysis further demonstrates functional relationship patterns between layers, with CKA similarity matrices clearly partitioning layers into three phases: feature extraction, compression, and specialization.
Self-Error-Instruct: Generalizing from Errors for LLMs Mathematical Reasoning
May 28, 2025
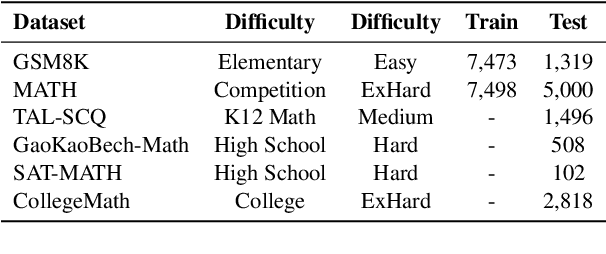

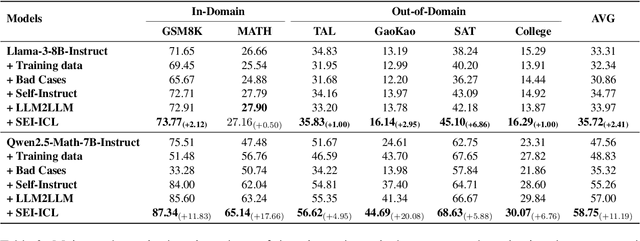
Although large language models demonstrate strong performance across various domains, they still struggle with numerous bad cases in mathematical reasoning. Previous approaches to learning from errors synthesize training data by solely extrapolating from isolated bad cases, thereby failing to generalize the extensive patterns inherent within these cases. This paper presents Self-Error-Instruct (SEI), a framework that addresses these model weaknesses and synthesizes more generalized targeted training data. Specifically, we explore a target model on two mathematical datasets, GSM8K and MATH, to pinpoint bad cases. Then, we generate error keyphrases for these cases based on the instructor model's (GPT-4o) analysis and identify error types by clustering these keyphrases. Next, we sample a few bad cases during each generation for each identified error type and input them into the instructor model, which synthesizes additional training data using a self-instruct approach. This new data is refined through a one-shot learning process to ensure that only the most effective examples are kept. Finally, we use these curated data to fine-tune the target model, iteratively repeating the process to enhance performance. We apply our framework to various models and observe improvements in their reasoning abilities across both in-domain and out-of-domain mathematics datasets. These results demonstrate the effectiveness of self-error instruction in improving LLMs' mathematical reasoning through error generalization.
CoSafe: Evaluating Large Language Model Safety in Multi-Turn Dialogue Coreference
Jun 25, 2024As large language models (LLMs) constantly evolve, ensuring their safety remains a critical research problem. Previous red-teaming approaches for LLM safety have primarily focused on single prompt attacks or goal hijacking. To the best of our knowledge, we are the first to study LLM safety in multi-turn dialogue coreference. We created a dataset of 1,400 questions across 14 categories, each featuring multi-turn coreference safety attacks. We then conducted detailed evaluations on five widely used open-source LLMs. The results indicated that under multi-turn coreference safety attacks, the highest attack success rate was 56% with the LLaMA2-Chat-7b model, while the lowest was 13.9% with the Mistral-7B-Instruct model. These findings highlight the safety vulnerabilities in LLMs during dialogue coreference interactions.
BirdNeRF: Fast Neural Reconstruction of Large-Scale Scenes From Aerial Imagery
Feb 11, 2024In this study, we introduce BirdNeRF, an adaptation of Neural Radiance Fields (NeRF) designed specifically for reconstructing large-scale scenes using aerial imagery. Unlike previous research focused on small-scale and object-centric NeRF reconstruction, our approach addresses multiple challenges, including (1) Addressing the issue of slow training and rendering associated with large models. (2) Meeting the computational demands necessitated by modeling a substantial number of images, requiring extensive resources such as high-performance GPUs. (3) Overcoming significant artifacts and low visual fidelity commonly observed in large-scale reconstruction tasks due to limited model capacity. Specifically, we present a novel bird-view pose-based spatial decomposition algorithm that decomposes a large aerial image set into multiple small sets with appropriately sized overlaps, allowing us to train individual NeRFs of sub-scene. This decomposition approach not only decouples rendering time from the scene size but also enables rendering to scale seamlessly to arbitrarily large environments. Moreover, it allows for per-block updates of the environment, enhancing the flexibility and adaptability of the reconstruction process. Additionally, we propose a projection-guided novel view re-rendering strategy, which aids in effectively utilizing the independently trained sub-scenes to generate superior rendering results. We evaluate our approach on existing datasets as well as against our own drone footage, improving reconstruction speed by 10x over classical photogrammetry software and 50x over state-of-the-art large-scale NeRF solution, on a single GPU with similar rendering quality.
DFR: Depth from Rotation by Uncalibrated Image Rectification with Latitudinal Motion Assumption
Jul 11, 2023Despite the increasing prevalence of rotating-style capture (e.g., surveillance cameras), conventional stereo rectification techniques frequently fail due to the rotation-dominant motion and small baseline between views. In this paper, we tackle the challenge of performing stereo rectification for uncalibrated rotating cameras. To that end, we propose Depth-from-Rotation (DfR), a novel image rectification solution that analytically rectifies two images with two-point correspondences and serves for further depth estimation. Specifically, we model the motion of a rotating camera as the camera rotates on a sphere with fixed latitude. The camera's optical axis lies perpendicular to the sphere's surface. We call this latitudinal motion assumption. Then we derive a 2-point analytical solver from directly computing the rectified transformations on the two images. We also present a self-adaptive strategy to reduce the geometric distortion after rectification. Extensive synthetic and real data experiments demonstrate that the proposed method outperforms existing works in effectiveness and efficiency by a significant margin.