 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCitySeeker: How Do VLMS Explore Embodied Urban Navigation With Implicit Human Needs?
Dec 18, 2025Vision-Language Models (VLMs) have made significant progress in explicit instruction-based navigation; however, their ability to interpret implicit human needs (e.g., "I am thirsty") in dynamic urban environments remains underexplored. This paper introduces CitySeeker, a novel benchmark designed to assess VLMs' spatial reasoning and decision-making capabilities for exploring embodied urban navigation to address implicit needs. CitySeeker includes 6,440 trajectories across 8 cities, capturing diverse visual characteristics and implicit needs in 7 goal-driven scenarios. Extensive experiments reveal that even top-performing models (e.g., Qwen2.5-VL-32B-Instruct) achieve only 21.1% task completion. We find key bottlenecks in error accumulation in long-horizon reasoning, inadequate spatial cognition, and deficient experiential recall. To further analyze them, we investigate a series of exploratory strategies-Backtracking Mechanisms, Enriching Spatial Cognition, and Memory-Based Retrieval (BCR), inspired by human cognitive mapping's emphasis on iterative observation-reasoning cycles and adaptive path optimization. Our analysis provides actionable insights for developing VLMs with robust spatial intelligence required for tackling "last-mile" navigation challenges.
Self-Error-Instruct: Generalizing from Errors for LLMs Mathematical Reasoning
May 28, 2025
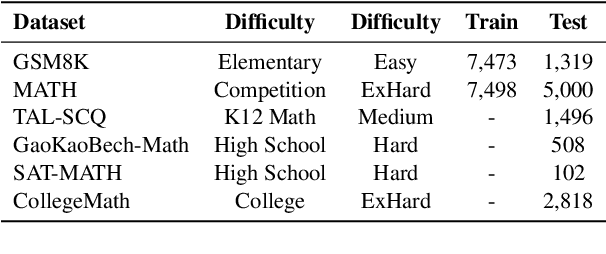

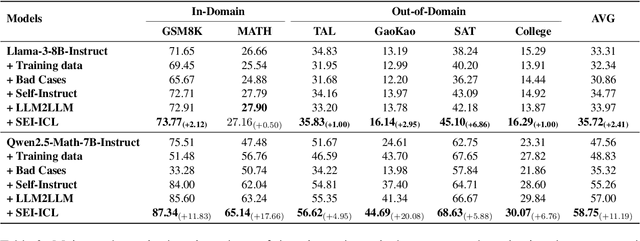
Although large language models demonstrate strong performance across various domains, they still struggle with numerous bad cases in mathematical reasoning. Previous approaches to learning from errors synthesize training data by solely extrapolating from isolated bad cases, thereby failing to generalize the extensive patterns inherent within these cases. This paper presents Self-Error-Instruct (SEI), a framework that addresses these model weaknesses and synthesizes more generalized targeted training data. Specifically, we explore a target model on two mathematical datasets, GSM8K and MATH, to pinpoint bad cases. Then, we generate error keyphrases for these cases based on the instructor model's (GPT-4o) analysis and identify error types by clustering these keyphrases. Next, we sample a few bad cases during each generation for each identified error type and input them into the instructor model, which synthesizes additional training data using a self-instruct approach. This new data is refined through a one-shot learning process to ensure that only the most effective examples are kept. Finally, we use these curated data to fine-tune the target model, iteratively repeating the process to enhance performance. We apply our framework to various models and observe improvements in their reasoning abilities across both in-domain and out-of-domain mathematics datasets. These results demonstrate the effectiveness of self-error instruction in improving LLMs' mathematical reasoning through error generalization.
OASIS: Order-Augmented Strategy for Improved Code Search
Mar 11, 2025



Code embeddings capture the semantic representations of code and are crucial for various code-related large language model (LLM) applications, such as code search. Previous training primarily relies on optimizing the InfoNCE loss by comparing positive natural language (NL)-code pairs with in-batch negatives. However, due to the sparse nature of code contexts, training solely by comparing the major differences between positive and negative pairs may fail to capture deeper semantic nuances. To address this issue, we propose a novel order-augmented strategy for improved code search (OASIS). It leverages order-based similarity labels to train models to capture subtle differences in similarity among negative pairs. Extensive benchmark evaluations demonstrate that our OASIS model significantly outperforms previous state-of-the-art models focusing solely on major positive-negative differences. It underscores the value of exploiting subtle differences among negative pairs with order labels for effective code embedding training.
UAlign: Leveraging Uncertainty Estimations for Factuality Alignment on Large Language Models
Dec 16, 2024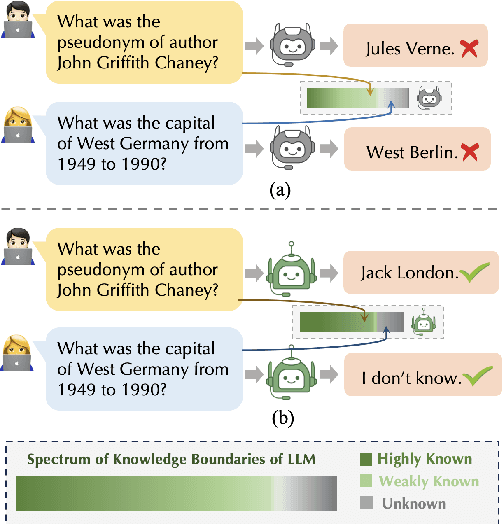
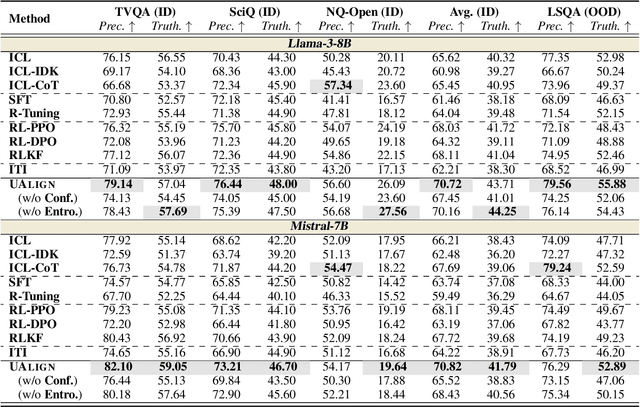

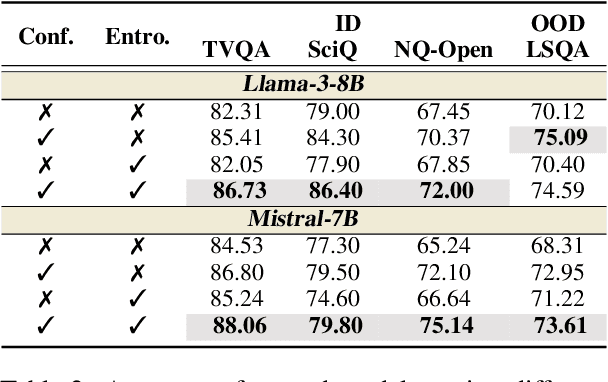
Despite demonstrating impressive capabilities, Large Language Models (LLMs) still often struggle to accurately express the factual knowledge they possess, especially in cases where the LLMs' knowledge boundaries are ambiguous. To improve LLMs' factual expressions, we propose the UAlign framework, which leverages Uncertainty estimations to represent knowledge boundaries, and then explicitly incorporates these representations as input features into prompts for LLMs to Align with factual knowledge. First, we prepare the dataset on knowledge question-answering (QA) samples by calculating two uncertainty estimations, including confidence score and semantic entropy, to represent the knowledge boundaries for LLMs. Subsequently, using the prepared dataset, we train a reward model that incorporates uncertainty estimations and then employ the Proximal Policy Optimization (PPO) algorithm for factuality alignment on LLMs. Experimental results indicate that, by integrating uncertainty representations in LLM alignment, the proposed UAlign can significantly enhance the LLMs' capacities to confidently answer known questions and refuse unknown questions on both in-domain and out-of-domain tasks, showing reliability improvements and good generalizability over various prompt- and training-based baselines.
CoSafe: Evaluating Large Language Model Safety in Multi-Turn Dialogue Coreference
Jun 25, 2024As large language models (LLMs) constantly evolve, ensuring their safety remains a critical research problem. Previous red-teaming approaches for LLM safety have primarily focused on single prompt attacks or goal hijacking. To the best of our knowledge, we are the first to study LLM safety in multi-turn dialogue coreference. We created a dataset of 1,400 questions across 14 categories, each featuring multi-turn coreference safety attacks. We then conducted detailed evaluations on five widely used open-source LLMs. The results indicated that under multi-turn coreference safety attacks, the highest attack success rate was 56% with the LLaMA2-Chat-7b model, while the lowest was 13.9% with the Mistral-7B-Instruct model. These findings highlight the safety vulnerabilities in LLMs during dialogue coreference interactions.
PopALM: Popularity-Aligned Language Models for Social Media Trendy Response Prediction
Feb 29, 2024



Social media platforms are daily exhibiting millions of events. To preliminarily predict the mainstream public reaction to these events, we study trendy response prediction to automatically generate top-liked user replies to social media events. While previous works focus on generating responses without factoring in popularity, we propose Popularity-Aligned Language Models (PopALM) to distinguish responses liked by a larger audience through reinforcement learning. Recognizing the noisy labels from user "likes", we tailor-make curriculum learning in proximal policy optimization (PPO) to help models capture the essential samples for easy-to-hard training. In experiments, we build a large-scale Weibo dataset for trendy response prediction, and its results show that PopALM can help boost the performance of advanced language models.
Learning Semantic Textual Similarity via Topic-informed Discrete Latent Variables
Nov 07, 2022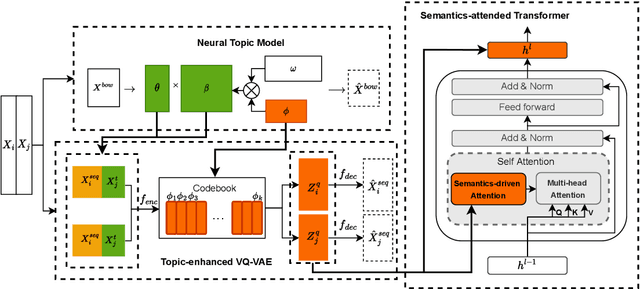
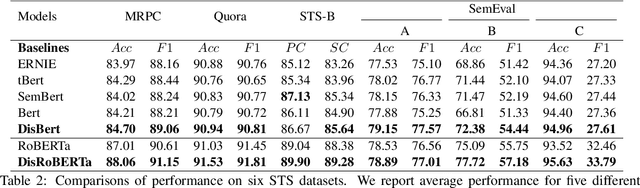
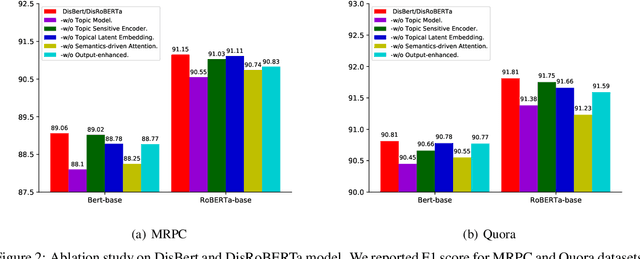
Recently, discrete latent variable models have received a surge of interest in both Natural Language Processing (NLP) and Computer Vision (CV), attributed to their comparable performance to the continuous counterparts in representation learning, while being more interpretable in their predictions. In this paper, we develop a topic-informed discrete latent variable model for semantic textual similarity, which learns a shared latent space for sentence-pair representation via vector quantization. Compared with previous models limited to local semantic contexts, our model can explore richer semantic information via topic modeling. We further boost the performance of semantic similarity by injecting the quantized representation into a transformer-based language model with a well-designed semantic-driven attention mechanism. We demonstrate, through extensive experiments across various English language datasets, that our model is able to surpass several strong neural baselines in semantic textual similarity tasks.
IMBENS: Ensemble Class-imbalanced Learning in Python
Nov 24, 2021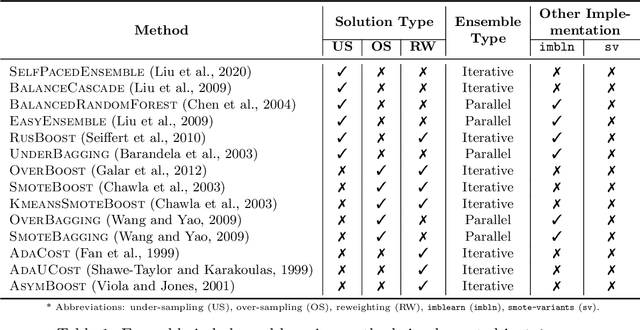
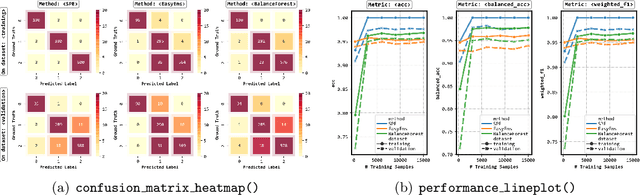
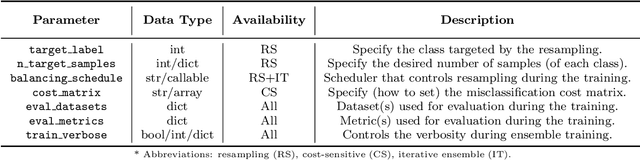
imbalanced-ensemble, abbreviated as imbens, is an open-source Python toolbox for quick implementing and deploying ensemble learning algorithms on class-imbalanced data. It provides access to multiple state-of-art ensemble imbalanced learning (EIL) methods, visualizer, and utility functions for dealing with the class imbalance problem. These ensemble methods include resampling-based, e.g., under/over-sampling, and reweighting-based ones, e.g., cost-sensitive learning. Beyond the implementation, we also extend conventional binary EIL algorithms with new functionalities like multi-class support and resampling scheduler, thereby enabling them to handle more complex tasks. The package was developed under a simple, well-documented API design follows that of scikit-learn for increased ease of use. imbens is released under the MIT open-source license and can be installed from Python Package Index (PyPI). Source code, binaries, detailed documentation, and usage examples are available at https://github.com/ZhiningLiu1998/imbalanced-ensemble.