 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHI-TransPA: Hearing Impairments Translation Personal Assistant
Nov 14, 2025Hearing-impaired individuals often face significant barriers in daily communication due to the inherent challenges of producing clear speech. To address this, we introduce the Omni-Model paradigm into assistive technology and present HI-TransPA, an instruction-driven audio-visual personal assistant. The model fuses indistinct speech with lip dynamics, enabling both translation and dialogue within a single multimodal framework. To address the distinctive pronunciation patterns of hearing-impaired speech and the limited adaptability of existing models, we develop a multimodal preprocessing and curation pipeline that detects facial landmarks, stabilizes the lip region, and quantitatively evaluates sample quality. These quality scores guide a curriculum learning strategy that first trains on clean, high-confidence samples and progressively incorporates harder cases to strengthen model robustness. Architecturally, we employs a novel unified 3D-Resampler to efficiently encode the lip dynamics, which is critical for accurate interpretation. Experiments on purpose-built HI-Dialogue dataset show that HI-TransPA achieves state-of-the-art performance in both literal accuracy and semantic fidelity. Our work establishes a foundation for applying Omni-Models to assistive communication technology, providing an end-to-end modeling framework and essential processing tools for future research.
OASIS: Order-Augmented Strategy for Improved Code Search
Mar 11, 2025



Code embeddings capture the semantic representations of code and are crucial for various code-related large language model (LLM) applications, such as code search. Previous training primarily relies on optimizing the InfoNCE loss by comparing positive natural language (NL)-code pairs with in-batch negatives. However, due to the sparse nature of code contexts, training solely by comparing the major differences between positive and negative pairs may fail to capture deeper semantic nuances. To address this issue, we propose a novel order-augmented strategy for improved code search (OASIS). It leverages order-based similarity labels to train models to capture subtle differences in similarity among negative pairs. Extensive benchmark evaluations demonstrate that our OASIS model significantly outperforms previous state-of-the-art models focusing solely on major positive-negative differences. It underscores the value of exploiting subtle differences among negative pairs with order labels for effective code embedding training.
BMX: Entropy-weighted Similarity and Semantic-enhanced Lexical Search
Aug 14, 2024BM25, a widely-used lexical search algorithm, remains crucial in information retrieval despite the rise of pre-trained and large language models (PLMs/LLMs). However, it neglects query-document similarity and lacks semantic understanding, limiting its performance. We revisit BM25 and introduce BMX, a novel extension of BM25 incorporating entropy-weighted similarity and semantic enhancement techniques. Extensive experiments demonstrate that BMX consistently outperforms traditional BM25 and surpasses PLM/LLM-based dense retrieval in long-context and real-world retrieval benchmarks. This study bridges the gap between classical lexical search and modern semantic approaches, offering a promising direction for future information retrieval research. The reference implementation of BMX can be found in Baguetter, which was created in the context of this work. The code can be found here: https://github.com/mixedbread-ai/baguetter.
2D Matryoshka Sentence Embeddings
Feb 22, 2024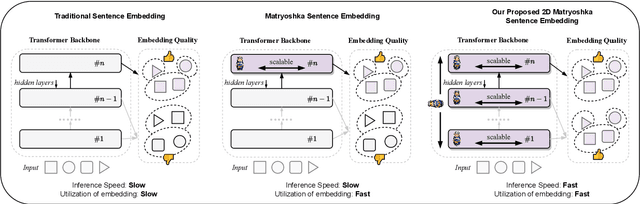
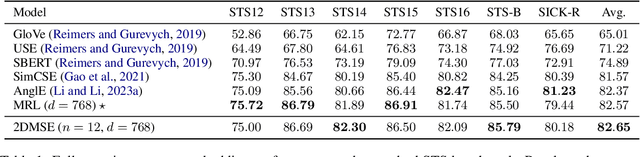
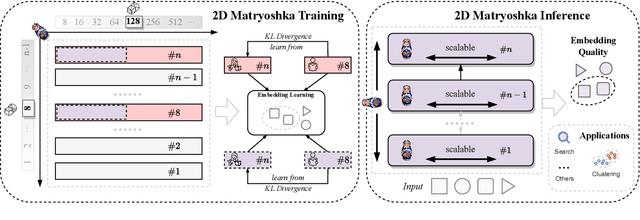
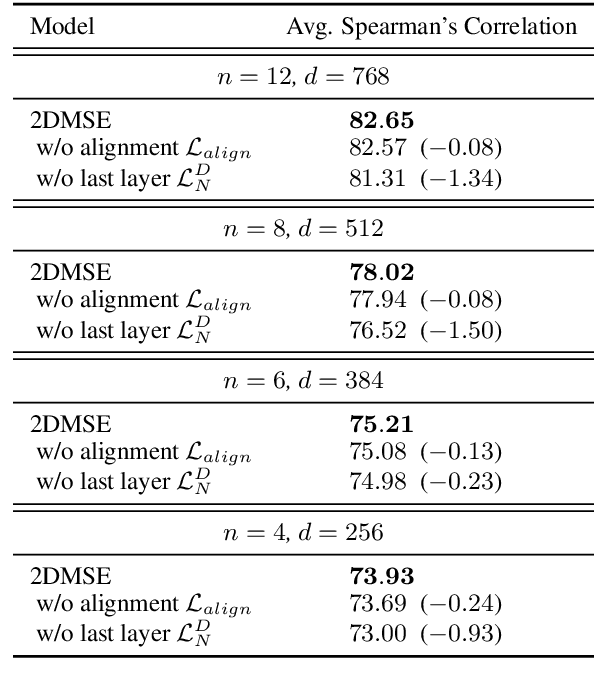
Common approaches rely on fixed-length embedding vectors from language models as sentence embeddings for downstream tasks such as semantic textual similarity (STS). Such methods are limited in their flexibility due to unknown computational constraints and budgets across various applications. Matryoshka Representation Learning (MRL) (Kusupati et al., 2022) encodes information at finer granularities, i.e., with lower embedding dimensions, to adaptively accommodate ad hoc tasks. Similar accuracy can be achieved with a smaller embedding size, leading to speedups in downstream tasks. Despite its improved efficiency, MRL still requires traversing all Transformer layers before obtaining the embedding, which remains the dominant factor in time and memory consumption. This prompts consideration of whether the fixed number of Transformer layers affects representation quality and whether using intermediate layers for sentence representation is feasible. In this paper, we introduce a novel sentence embedding model called Two-dimensional Matryoshka Sentence Embedding (2DMSE). It supports elastic settings for both embedding sizes and Transformer layers, offering greater flexibility and efficiency than MRL. We conduct extensive experiments on STS tasks and downstream applications. The experimental results demonstrate the effectiveness of our proposed model in dynamically supporting different embedding sizes and Transformer layers, allowing it to be highly adaptable to various scenarios.
Generative Deduplication For Socia Media Data Selection
Jan 12, 2024Social media data is plagued by the redundancy problem caused by its noisy nature, leading to increased training time and model bias. To address this issue, we propose a novel approach called generative deduplication. It aims to remove duplicate text from noisy social media data and mitigate model bias. By doing so, it can improve social media language understanding performance and save training time. Extensive experiments demonstrate that the proposed generative deduplication can effectively reduce training samples while improving performance. This evidence suggests the effectiveness of generative deduplication and its importance in social media language understanding.
DeeLM: Dependency-enhanced Large Language Model for Sentence Embeddings
Nov 09, 2023



Recent studies have proposed using large language models (LLMs) for sentence embeddings. However, most existing LLMs are built with an autoregressive architecture that primarily captures forward dependencies while neglecting backward dependencies. Previous work has highlighted the importance of backward dependencies in improving sentence embeddings. To address this issue, in this paper, we first present quantitative evidence demonstrating the limited learning of backward dependencies in LLMs. Then, we propose a novel approach called Dependency-Enhanced Large Language Model (DeeLM) to improve sentence embeddings. Specifically, we found a turning point in LLMs, where surpassing specific LLM layers leads to a significant performance drop in the semantic textual similarity (STS) task. STS is a crucial task for evaluating sentence embeddings. We then extract the layers after the turning point to make them bidirectional, allowing for the learning of backward dependencies. Extensive experiments demonstrate that DeeLM outperforms baselines and achieves state-of-the-art performance across various STS tasks.
Label Supervised LLaMA Finetuning
Oct 02, 2023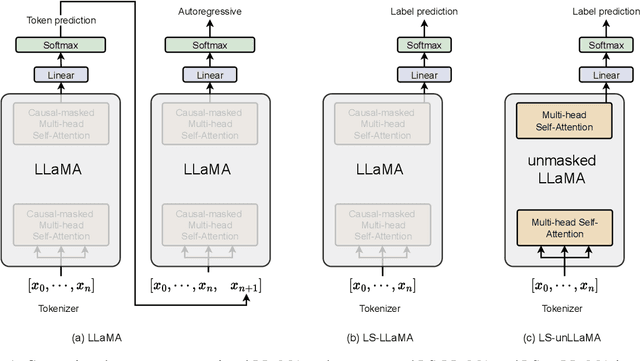

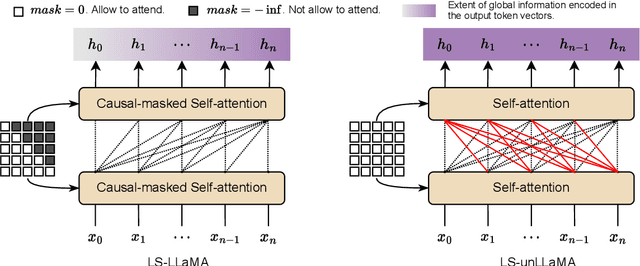
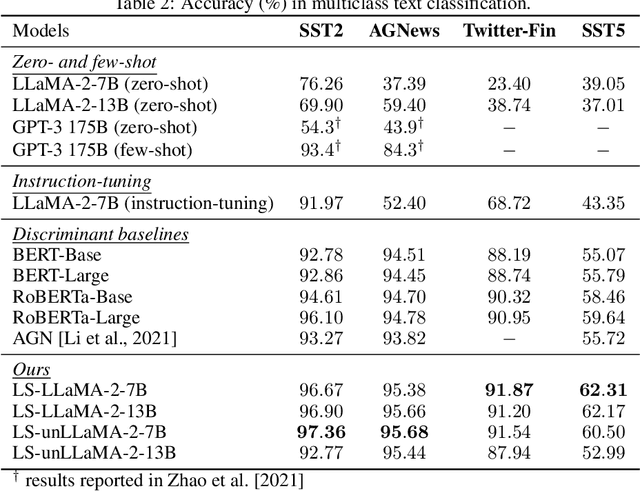
The recent success of Large Language Models (LLMs) has gained significant attention in both academia and industry. Substantial efforts have been made to enhance the zero- and few-shot generalization capabilities of open-source LLMs through finetuning. Currently, the prevailing approach is instruction-tuning, which trains LLMs to complete real-world tasks by generating responses guided by natural language instructions. It is worth noticing that such an approach may underperform in sequence and token classification tasks. Unlike text generation tasks, classification tasks have a limited label space, where precise label prediction is more appreciated than generating diverse and human-like responses. Prior research has unveiled that instruction-tuned LLMs cannot outperform BERT, prompting us to explore the potential of leveraging latent representations from LLMs for supervised label prediction. In this paper, we introduce a label-supervised adaptation for LLMs, which aims to finetuning the model with discriminant labels. We evaluate this approach with Label Supervised LLaMA (LS-LLaMA), based on LLaMA-2-7B, a relatively small-scale LLM, and can be finetuned on a single GeForce RTX4090 GPU. We extract latent representations from the final LLaMA layer and project them into the label space to compute the cross-entropy loss. The model is finetuned by Low-Rank Adaptation (LoRA) to minimize this loss. Remarkably, without intricate prompt engineering or external knowledge, LS-LLaMA substantially outperforms LLMs ten times its size in scale and demonstrates consistent improvements compared to robust baselines like BERT-Large and RoBERTa-Large in text classification. Moreover, by removing the causal mask from decoders, LS-unLLaMA achieves the state-of-the-art performance in named entity recognition (NER). Our work will shed light on a novel approach to adapting LLMs for various downstream tasks.
AnglE-Optimized Text Embeddings
Sep 22, 2023



High-quality text embedding is pivotal in improving semantic textual similarity (STS) tasks, which are crucial components in Large Language Model (LLM) applications. However, a common challenge existing text embedding models face is the problem of vanishing gradients, primarily due to their reliance on the cosine function in the optimization objective, which has saturation zones. To address this issue, this paper proposes a novel angle-optimized text embedding model called AnglE. The core idea of AnglE is to introduce angle optimization in a complex space. This novel approach effectively mitigates the adverse effects of the saturation zone in the cosine function, which can impede gradient and hinder optimization processes. To set up a comprehensive STS evaluation, we experimented on existing short-text STS datasets and a newly collected long-text STS dataset from GitHub Issues. Furthermore, we examine domain-specific STS scenarios with limited labeled data and explore how AnglE works with LLM-annotated data. Extensive experiments were conducted on various tasks including short-text STS, long-text STS, and domain-specific STS tasks. The results show that AnglE outperforms the state-of-the-art (SOTA) STS models that ignore the cosine saturation zone. These findings demonstrate the ability of AnglE to generate high-quality text embeddings and the usefulness of angle optimization in STS.
Recurrent Attention Networks for Long-text Modeling
Jun 12, 2023Self-attention-based models have achieved remarkable progress in short-text mining. However, the quadratic computational complexities restrict their application in long text processing. Prior works have adopted the chunking strategy to divide long documents into chunks and stack a self-attention backbone with the recurrent structure to extract semantic representation. Such an approach disables parallelization of the attention mechanism, significantly increasing the training cost and raising hardware requirements. Revisiting the self-attention mechanism and the recurrent structure, this paper proposes a novel long-document encoding model, Recurrent Attention Network (RAN), to enable the recurrent operation of self-attention. Combining the advantages from both sides, the well-designed RAN is capable of extracting global semantics in both token-level and document-level representations, making it inherently compatible with both sequential and classification tasks, respectively. Furthermore, RAN is computationally scalable as it supports parallelization on long document processing. Extensive experiments demonstrate the long-text encoding ability of the proposed RAN model on both classification and sequential tasks, showing its potential for a wide range of applications.
Incorporating Effective Global Information via Adaptive Gate Attention for Text Classification
Feb 22, 2020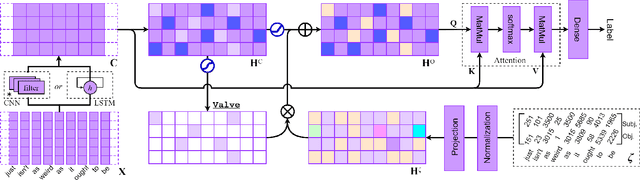
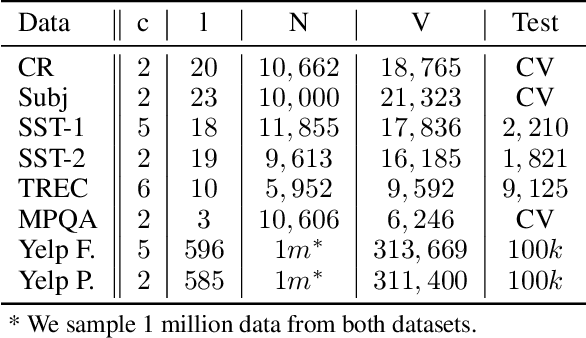
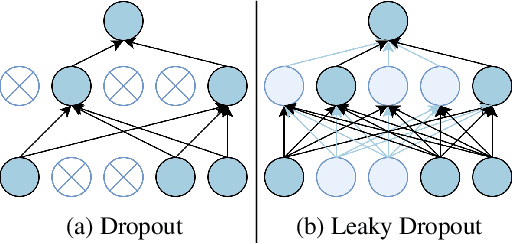
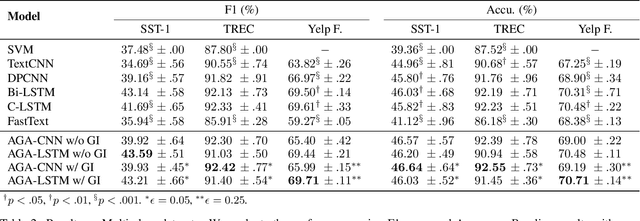
The dominant text classification studies focus on training classifiers using textual instances only or introducing external knowledge (e.g., hand-craft features and domain expert knowledge). In contrast, some corpus-level statistical features, like word frequency and distribution, are not well exploited. Our work shows that such simple statistical information can enhance classification performance both efficiently and significantly compared with several baseline models. In this paper, we propose a classifier with gate mechanism named Adaptive Gate Attention model with Global Information (AGA+GI), in which the adaptive gate mechanism incorporates global statistical features into latent semantic features and the attention layer captures dependency relationship within the sentence. To alleviate the overfitting issue, we propose a novel Leaky Dropout mechanism to improve generalization ability and performance stability. Our experiments show that the proposed method can achieve better accuracy than CNN-based and RNN-based approaches without global information on several benchmarks.