 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D Matryoshka Sentence Embeddings
Paper and Code
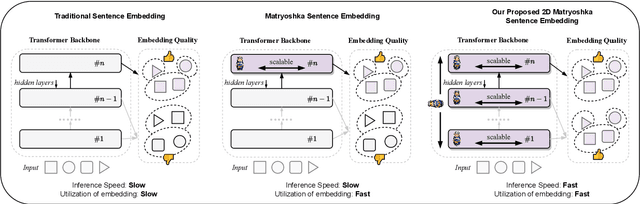
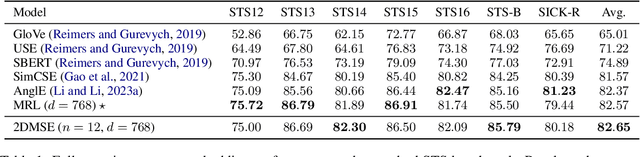
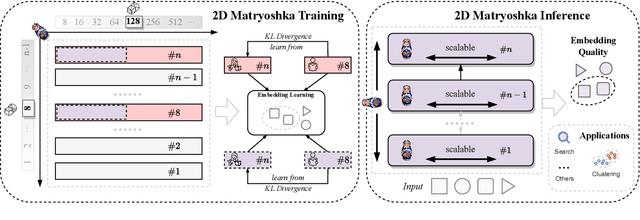
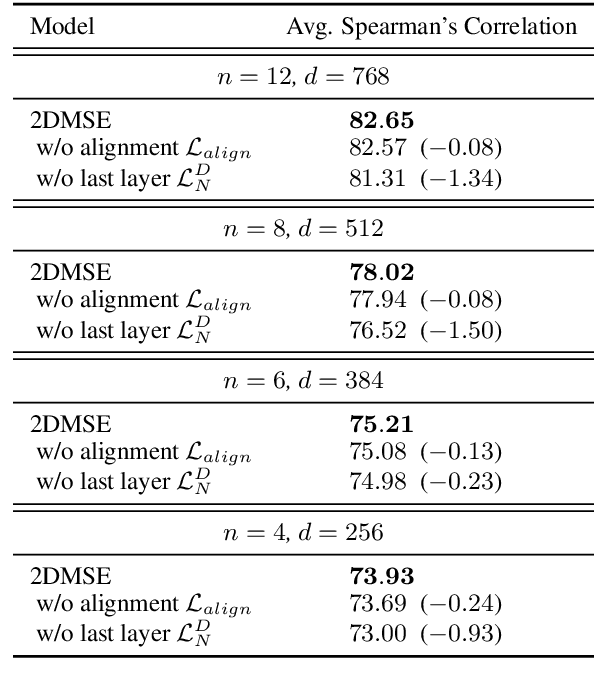
Common approaches rely on fixed-length embedding vectors from language models as sentence embeddings for downstream tasks such as semantic textual similarity (STS). Such methods are limited in their flexibility due to unknown computational constraints and budgets across various applications. Matryoshka Representation Learning (MRL) (Kusupati et al., 2022) encodes information at finer granularities, i.e., with lower embedding dimensions, to adaptively accommodate ad hoc tasks. Similar accuracy can be achieved with a smaller embedding size, leading to speedups in downstream tasks. Despite its improved efficiency, MRL still requires traversing all Transformer layers before obtaining the embedding, which remains the dominant factor in time and memory consumption. This prompts consideration of whether the fixed number of Transformer layers affects representation quality and whether using intermediate layers for sentence representation is feasible. In this paper, we introduce a novel sentence embedding model called Two-dimensional Matryoshka Sentence Embedding (2DMSE). It supports elastic settings for both embedding sizes and Transformer layers, offering greater flexibility and efficiency than MRL. We conduct extensive experiments on STS tasks and downstream applications. The experimental results demonstrate the effectiveness of our proposed model in dynamically supporting different embedding sizes and Transformer layers, allowing it to be highly adaptable to various scenarios.