 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShadowPEFT: Shadow Network for Parameter-Efficient Fine-Tuning
Apr 21, 2026Parameter-efficient fine-tuning (PEFT) reduces the training cost of full-parameter fine-tuning for large language models (LLMs) by training only a small set of task-specific parameters while freezing the pretrained backbone. However, existing approaches, such as Low-Rank Adaptation (LoRA), achieve adaptation by inserting independent low-rank perturbations directly to individual weights, resulting in a local parameterization of adaptation. We propose ShadowPEFT, a centralized PEFT framework that instead performs layer-level refinement through a depth-shared shadow module. At each transformer layer, ShadowPEFT maintains a parallel shadow state and evolves it repeatedly for progressively richer hidden states. This design shifts adaptation from distributed weight-space perturbations to a shared layer-space refinement process. Since the shadow module is decoupled from the backbone, it can be reused across depth, independently pretrained, and optionally deployed in a detached mode, benefiting edge computing scenarios. Experiments on generation and understanding benchmarks show that ShadowPEFT matches or outperforms LoRA and DoRA under comparable trainable-parameter budgets. Additional analyses on shadow pretraining, cross-dataset transfer, parameter scaling, inference latency, and system-level evaluation suggest that centralized layer-space adaptation is a competitive and flexible alternative to conventional low-rank PEFT.
CondAmbigQA: A Benchmark and Dataset for Conditional Ambiguous Question Answering
Feb 03, 2025



Large language models (LLMs) are prone to hallucinations in question-answering (QA) tasks when faced with ambiguous questions. Users often assume that LLMs share their cognitive alignment, a mutual understanding of context, intent, and implicit details, leading them to omit critical information in the queries. However, LLMs generate responses based on assumptions that can misalign with user intent, which may be perceived as hallucinations if they misalign with the user's intent. Therefore, identifying those implicit assumptions is crucial to resolve ambiguities in QA. Prior work, such as AmbigQA, reduces ambiguity in queries via human-annotated clarifications, which is not feasible in real application. Meanwhile, ASQA compiles AmbigQA's short answers into long-form responses but inherits human biases and fails capture explicit logical distinctions that differentiates the answers. We introduce Conditional Ambiguous Question-Answering (CondAmbigQA), a benchmark with 200 ambiguous queries and condition-aware evaluation metrics. Our study pioneers the concept of ``conditions'' in ambiguous QA tasks, where conditions stand for contextual constraints or assumptions that resolve ambiguities. The retrieval-based annotation strategy uses retrieved Wikipedia fragments to identify possible interpretations for a given query as its conditions and annotate the answers through those conditions. Such a strategy minimizes human bias introduced by different knowledge levels among annotators. By fixing retrieval results, CondAmbigQA evaluates how RAG systems leverage conditions to resolve ambiguities. Experiments show that models considering conditions before answering improve performance by $20\%$, with an additional $5\%$ gain when conditions are explicitly provided. These results underscore the value of conditional reasoning in QA, offering researchers tools to rigorously evaluate ambiguity resolution.
MLLA-UNet: Mamba-like Linear Attention in an Efficient U-Shape Model for Medical Image Segmentation
Oct 31, 2024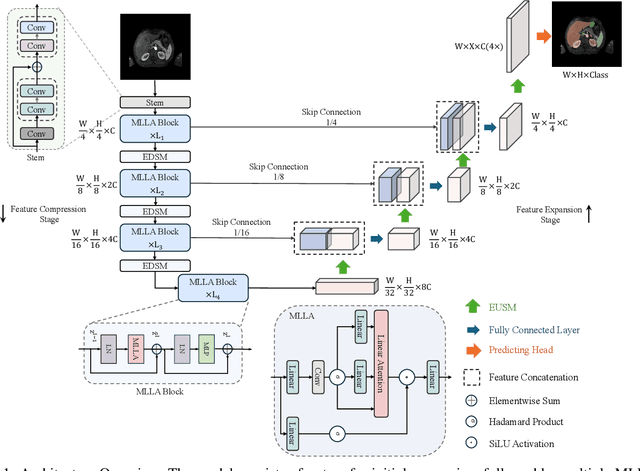
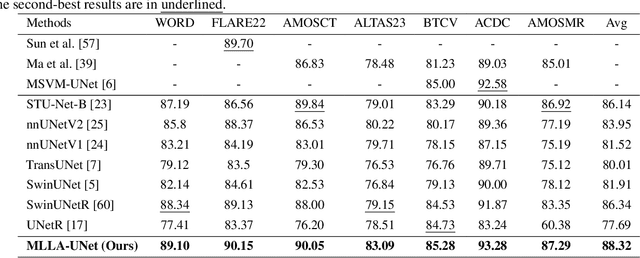
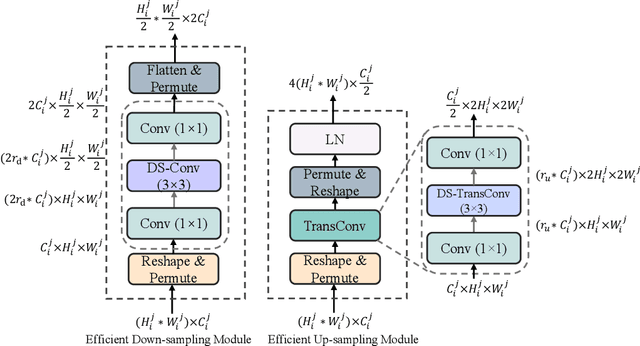
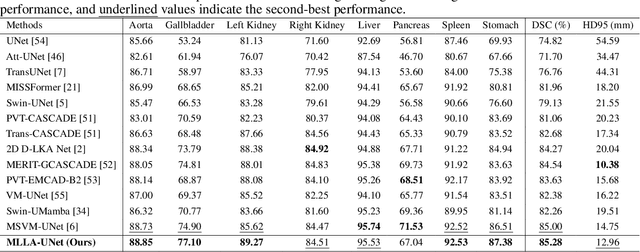
Recent advancements in medical imaging have resulted in more complex and diverse images, with challenges such as high anatomical variability, blurred tissue boundaries, low organ contrast, and noise. Traditional segmentation methods struggle to address these challenges, making deep learning approaches, particularly U-shaped architectures, increasingly prominent. However, the quadratic complexity of standard self-attention makes Transformers computationally prohibitive for high-resolution images. To address these challenges, we propose MLLA-UNet (Mamba-Like Linear Attention UNet), a novel architecture that achieves linear computational complexity while maintaining high segmentation accuracy through its innovative combination of linear attention and Mamba-inspired adaptive mechanisms, complemented by an efficient symmetric sampling structure for enhanced feature processing. Our architecture effectively preserves essential spatial features while capturing long-range dependencies at reduced computational complexity. Additionally, we introduce a novel sampling strategy for multi-scale feature fusion. Experiments demonstrate that MLLA-UNet achieves state-of-the-art performance on six challenging datasets with 24 different segmentation tasks, including but not limited to FLARE22, AMOS CT, and ACDC, with an average DSC of 88.32%. These results underscore the superiority of MLLA-UNet over existing methods. Our contributions include the novel 2D segmentation architecture and its empirical validation. The code is available via https://github.com/csyfjiang/MLLA-UNet.
2D Matryoshka Sentence Embeddings
Feb 22, 2024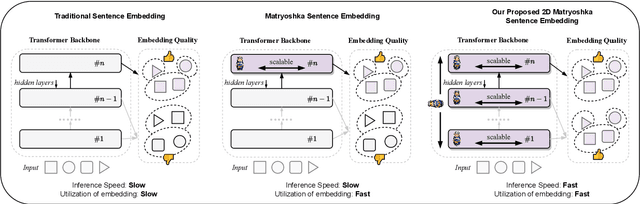
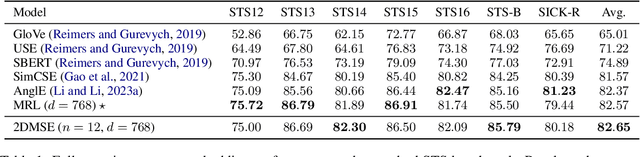
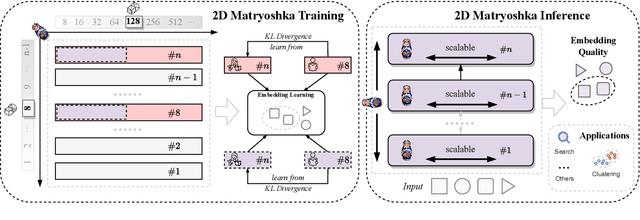
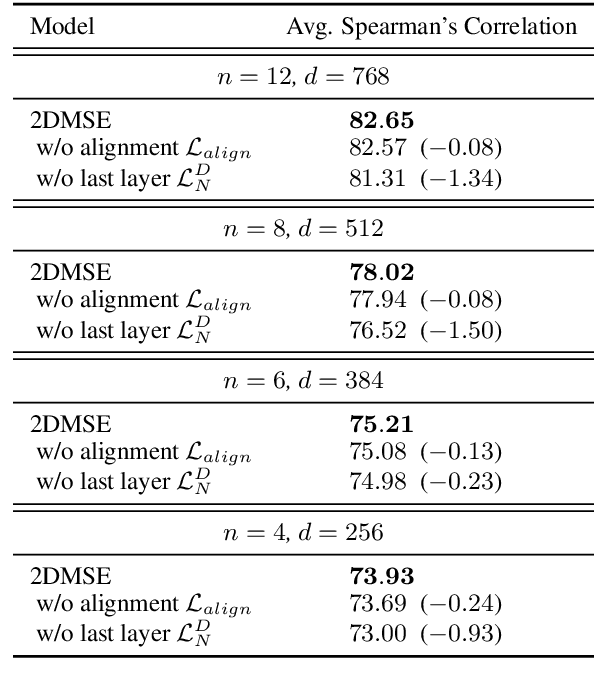
Common approaches rely on fixed-length embedding vectors from language models as sentence embeddings for downstream tasks such as semantic textual similarity (STS). Such methods are limited in their flexibility due to unknown computational constraints and budgets across various applications. Matryoshka Representation Learning (MRL) (Kusupati et al., 2022) encodes information at finer granularities, i.e., with lower embedding dimensions, to adaptively accommodate ad hoc tasks. Similar accuracy can be achieved with a smaller embedding size, leading to speedups in downstream tasks. Despite its improved efficiency, MRL still requires traversing all Transformer layers before obtaining the embedding, which remains the dominant factor in time and memory consumption. This prompts consideration of whether the fixed number of Transformer layers affects representation quality and whether using intermediate layers for sentence representation is feasible. In this paper, we introduce a novel sentence embedding model called Two-dimensional Matryoshka Sentence Embedding (2DMSE). It supports elastic settings for both embedding sizes and Transformer layers, offering greater flexibility and efficiency than MRL. We conduct extensive experiments on STS tasks and downstream applications. The experimental results demonstrate the effectiveness of our proposed model in dynamically supporting different embedding sizes and Transformer layers, allowing it to be highly adaptable to various scenarios.
Recognizing Conditional Causal Relationships about Emotions and Their Corresponding Conditions
Nov 28, 2023The study of causal relationships between emotions and causes in texts has recently received much attention. Most works focus on extracting causally related clauses from documents. However, none of these works has considered that the causal relationships among the extracted emotion and cause clauses can only be valid under some specific context clauses. To highlight the context in such special causal relationships, we propose a new task to determine whether or not an input pair of emotion and cause has a valid causal relationship under different contexts and extract the specific context clauses that participate in the causal relationship. Since the task is new for which no existing dataset is available, we conduct manual annotation on a benchmark dataset to obtain the labels for our tasks and the annotations of each context clause's type that can also be used in some other applications. We adopt negative sampling to construct the final dataset to balance the number of documents with and without causal relationships. Based on the constructed dataset, we propose an end-to-end multi-task framework, where we design two novel and general modules to handle the two goals of our task. Specifically, we propose a context masking module to extract the context clauses participating in the causal relationships. We propose a prediction aggregation module to fine-tune the prediction results according to whether the input emotion and causes depend on specific context clauses. Results of extensive comparative experiments and ablation studies demonstrate the effectiveness and generality of our proposed framework.
Label Supervised LLaMA Finetuning
Oct 02, 2023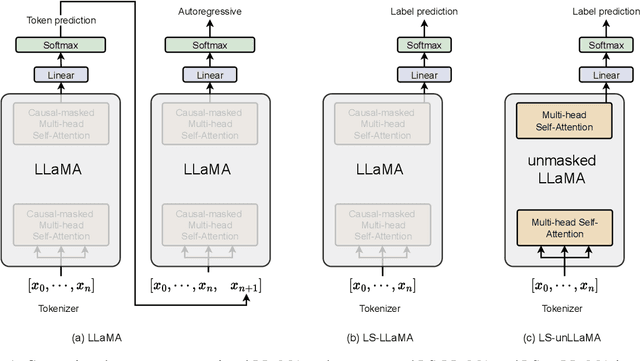

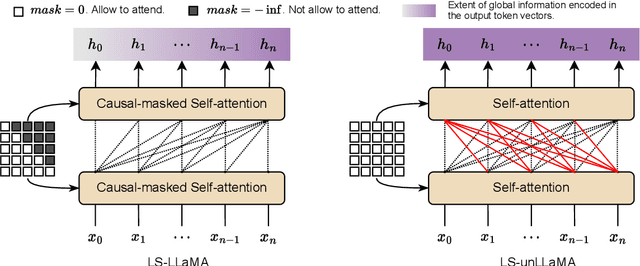
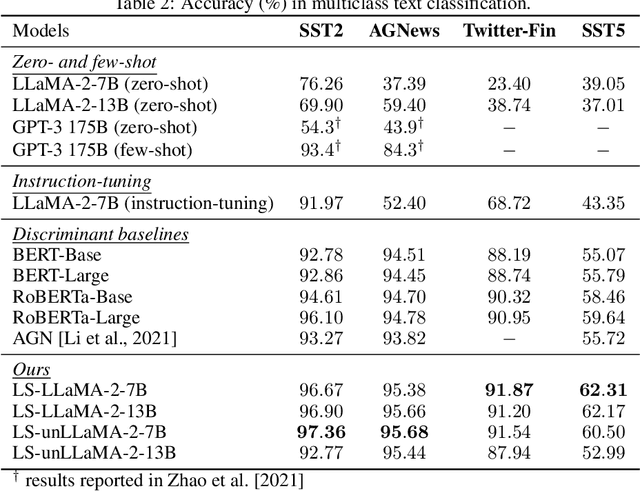
The recent success of Large Language Models (LLMs) has gained significant attention in both academia and industry. Substantial efforts have been made to enhance the zero- and few-shot generalization capabilities of open-source LLMs through finetuning. Currently, the prevailing approach is instruction-tuning, which trains LLMs to complete real-world tasks by generating responses guided by natural language instructions. It is worth noticing that such an approach may underperform in sequence and token classification tasks. Unlike text generation tasks, classification tasks have a limited label space, where precise label prediction is more appreciated than generating diverse and human-like responses. Prior research has unveiled that instruction-tuned LLMs cannot outperform BERT, prompting us to explore the potential of leveraging latent representations from LLMs for supervised label prediction. In this paper, we introduce a label-supervised adaptation for LLMs, which aims to finetuning the model with discriminant labels. We evaluate this approach with Label Supervised LLaMA (LS-LLaMA), based on LLaMA-2-7B, a relatively small-scale LLM, and can be finetuned on a single GeForce RTX4090 GPU. We extract latent representations from the final LLaMA layer and project them into the label space to compute the cross-entropy loss. The model is finetuned by Low-Rank Adaptation (LoRA) to minimize this loss. Remarkably, without intricate prompt engineering or external knowledge, LS-LLaMA substantially outperforms LLMs ten times its size in scale and demonstrates consistent improvements compared to robust baselines like BERT-Large and RoBERTa-Large in text classification. Moreover, by removing the causal mask from decoders, LS-unLLaMA achieves the state-of-the-art performance in named entity recognition (NER). Our work will shed light on a novel approach to adapting LLMs for various downstream tasks.
Recurrent Attention Networks for Long-text Modeling
Jun 12, 2023Self-attention-based models have achieved remarkable progress in short-text mining. However, the quadratic computational complexities restrict their application in long text processing. Prior works have adopted the chunking strategy to divide long documents into chunks and stack a self-attention backbone with the recurrent structure to extract semantic representation. Such an approach disables parallelization of the attention mechanism, significantly increasing the training cost and raising hardware requirements. Revisiting the self-attention mechanism and the recurrent structure, this paper proposes a novel long-document encoding model, Recurrent Attention Network (RAN), to enable the recurrent operation of self-attention. Combining the advantages from both sides, the well-designed RAN is capable of extracting global semantics in both token-level and document-level representations, making it inherently compatible with both sequential and classification tasks, respectively. Furthermore, RAN is computationally scalable as it supports parallelization on long document processing. Extensive experiments demonstrate the long-text encoding ability of the proposed RAN model on both classification and sequential tasks, showing its potential for a wide range of applications.
Incorporating Effective Global Information via Adaptive Gate Attention for Text Classification
Feb 22, 2020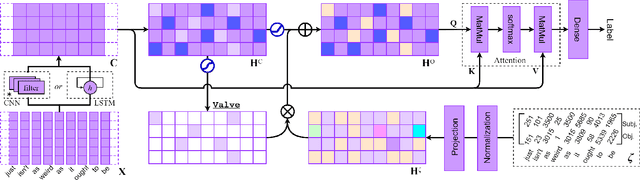
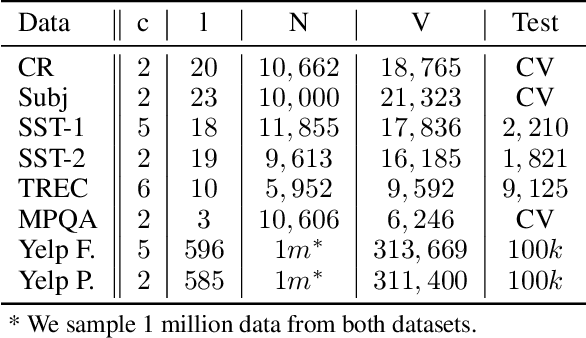
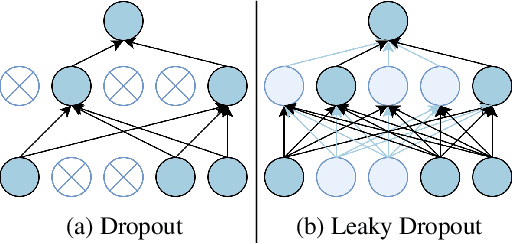
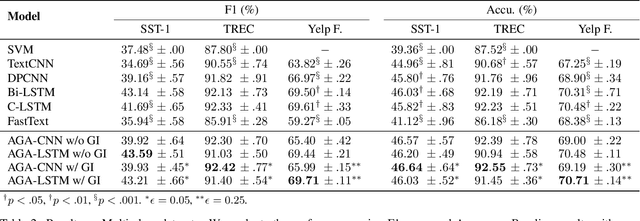
The dominant text classification studies focus on training classifiers using textual instances only or introducing external knowledge (e.g., hand-craft features and domain expert knowledge). In contrast, some corpus-level statistical features, like word frequency and distribution, are not well exploited. Our work shows that such simple statistical information can enhance classification performance both efficiently and significantly compared with several baseline models. In this paper, we propose a classifier with gate mechanism named Adaptive Gate Attention model with Global Information (AGA+GI), in which the adaptive gate mechanism incorporates global statistical features into latent semantic features and the attention layer captures dependency relationship within the sentence. To alleviate the overfitting issue, we propose a novel Leaky Dropout mechanism to improve generalization ability and performance stability. Our experiments show that the proposed method can achieve better accuracy than CNN-based and RNN-based approaches without global information on several benchmarks.