 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Attention Networks for Long-text Modeling
Jun 12, 2023Self-attention-based models have achieved remarkable progress in short-text mining. However, the quadratic computational complexities restrict their application in long text processing. Prior works have adopted the chunking strategy to divide long documents into chunks and stack a self-attention backbone with the recurrent structure to extract semantic representation. Such an approach disables parallelization of the attention mechanism, significantly increasing the training cost and raising hardware requirements. Revisiting the self-attention mechanism and the recurrent structure, this paper proposes a novel long-document encoding model, Recurrent Attention Network (RAN), to enable the recurrent operation of self-attention. Combining the advantages from both sides, the well-designed RAN is capable of extracting global semantics in both token-level and document-level representations, making it inherently compatible with both sequential and classification tasks, respectively. Furthermore, RAN is computationally scalable as it supports parallelization on long document processing. Extensive experiments demonstrate the long-text encoding ability of the proposed RAN model on both classification and sequential tasks, showing its potential for a wide range of applications.
Incorporating Effective Global Information via Adaptive Gate Attention for Text Classification
Feb 22, 2020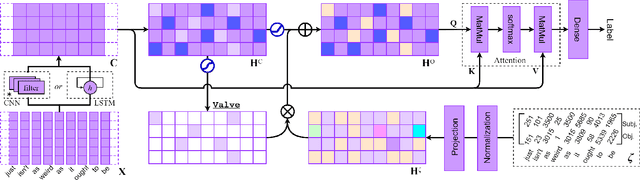
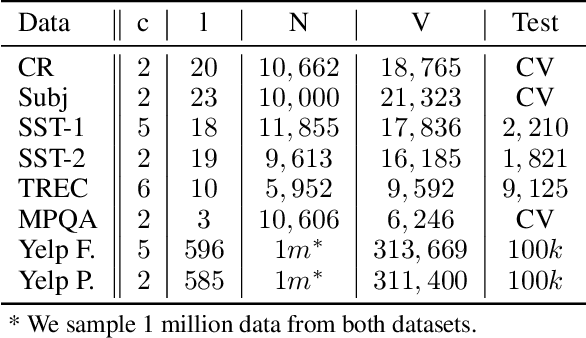
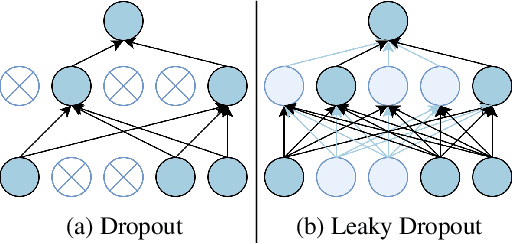
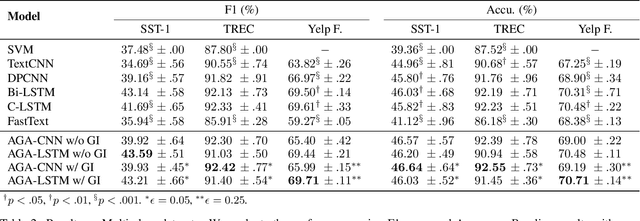
The dominant text classification studies focus on training classifiers using textual instances only or introducing external knowledge (e.g., hand-craft features and domain expert knowledge). In contrast, some corpus-level statistical features, like word frequency and distribution, are not well exploited. Our work shows that such simple statistical information can enhance classification performance both efficiently and significantly compared with several baseline models. In this paper, we propose a classifier with gate mechanism named Adaptive Gate Attention model with Global Information (AGA+GI), in which the adaptive gate mechanism incorporates global statistical features into latent semantic features and the attention layer captures dependency relationship within the sentence. To alleviate the overfitting issue, we propose a novel Leaky Dropout mechanism to improve generalization ability and performance stability. Our experiments show that the proposed method can achieve better accuracy than CNN-based and RNN-based approaches without global information on several benchmarks.