 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Multi-Reference Image Generation with Dynamic Reward Optimization
Jun 25, 2026While personalized image generation has achieved remarkable progress, multi-reference image generation (MRIG) remains a challenging task. Most existing benchmarks fail to adequately evaluate complex MRIG scenarios, hindering further progress in this area. To better assess model performance on complex MRIG tasks, we introduce OmniRef-Bench, a benchmark that covers complex combinations of reference image types and a large number of reference images. Evaluations on OmniRef-Bench show that mainstream open-source models struggle in complex MRIG scenarios, and their performance deteriorates significantly as the number of mixed-type reference images increases. To address this issue, we propose DyRef, a two-stage training framework. In the first stage, supervised fine-tuning equips the model with the basic capability to handle complex MRIG tasks. In the second stage, we introduce Difficulty-aware Advantage Reweighting (DAR) and Discriminative Reward Scaling (DRS). DAR dynamically adjusts the optimization objective to improve performance when handling a large number of mixed-type reference images. DRS enlarges intra-group reward differences for more effective policy optimization. Experiments demonstrate that DyRef significantly improves the performance of open-source models on OmniRef-Bench and single-image editing benchmarks, demonstrating the effectiveness and generalization capability of our approach.
Multiscale Switch for Semi-Supervised and Contrastive Learning in Medical Ultrasound Image Segmentation
Mar 19, 2026Medical ultrasound image segmentation faces significant challenges due to limited labeled data and characteristic imaging artifacts including speckle noise and low-contrast boundaries. While semi-supervised learning (SSL) approaches have emerged to address data scarcity, existing methods suffer from suboptimal unlabeled data utilization and lack robust feature representation mechanisms. In this paper, we propose Switch, a novel SSL framework with two key innovations: (1) Multiscale Switch (MSS) strategy that employs hierarchical patch mixing to achieve uniform spatial coverage; (2) Frequency Domain Switch (FDS) with contrastive learning that performs amplitude switching in Fourier space for robust feature representations. Our framework integrates these components within a teacher-student architecture to effectively leverage both labeled and unlabeled data. Comprehensive evaluation across six diverse ultrasound datasets (lymph nodes, breast lesions, thyroid nodules, and prostate) demonstrates consistent superiority over state-of-the-art methods. At 5\% labeling ratio, Switch achieves remarkable improvements: 80.04\% Dice on LN-INT, 85.52\% Dice on DDTI, and 83.48\% Dice on Prostate datasets, with our semi-supervised approach even exceeding fully supervised baselines. The method maintains parameter efficiency (1.8M parameters) while delivering superior performance, validating its effectiveness for resource-constrained medical imaging applications. The source code is publicly available at https://github.com/jinggqu/Switch
PGVMS: A Prompt-Guided Unified Framework for Virtual Multiplex IHC Staining with Pathological Semantic Learning
Feb 26, 2026Immunohistochemical (IHC) staining enables precise molecular profiling of protein expression, with over 200 clinically available antibody-based tests in modern pathology. However, comprehensive IHC analysis is frequently limited by insufficient tissue quantities in small biopsies. Therefore, virtual multiplex staining emerges as an innovative solution to digitally transform H&E images into multiple IHC representations, yet current methods still face three critical challenges: (1) inadequate semantic guidance for multi-staining, (2) inconsistent distribution of immunochemistry staining, and (3) spatial misalignment across different stain modalities. To overcome these limitations, we present a prompt-guided framework for virtual multiplex IHC staining using only uniplex training data (PGVMS). Our framework introduces three key innovations corresponding to each challenge: First, an adaptive prompt guidance mechanism employing a pathological visual language model dynamically adjusts staining prompts to resolve semantic guidance limitations (Challenge 1). Second, our protein-aware learning strategy (PALS) maintains precise protein expression patterns by direct quantification and constraint of protein distributions (Challenge 2). Third, the prototype-consistent learning strategy (PCLS) establishes cross-image semantic interaction to correct spatial misalignments (Challenge 3).
* Accepted by TMI
Any-to-All MRI Synthesis: A Unified Foundation Model for Nasopharyngeal Carcinoma and Its Downstream Applications
Feb 09, 2026Magnetic resonance imaging (MRI) is essential for nasopharyngeal carcinoma (NPC) radiotherapy (RT), but practical constraints, such as patient discomfort, long scan times, and high costs often lead to incomplete modalities in clinical practice, compromising RT planning accuracy. Traditional MRI synthesis methods are modality-specific, limited in anatomical adaptability, and lack clinical interpretability-failing to meet NPC's RT needs. Here, we developed a unified foundation model integrating contrastive visual representation learning and vision-language alignment (VLA) to enable any-to-all MRI synthesis. The model uses a contrastive encoder for modality-invariant representations and a CLIP-based text-informed decoder for semantically consistent synthesis, supporting any-to-all MRI synthesis via one unified foundation model. Trained on 40,825 images from 13 institutions, it achieves consistently high performance (average SSIM 0.90, PSNR 27) across 26 internal/external validation sites (15,748 images), with superior synthesis fidelity and robustness to noise and domain shifts. Meanwhile, its unified representation enhances downstream RT-relevant tasks (e.g., segmentation). This work advances digital medicine solutions for NPC care by leveraging foundation models to bridge technical synthesis and clinical utility.
DeepMoLM: Leveraging Visual and Geometric Structural Information for Molecule-Text Modeling
Jan 21, 2026AI models for drug discovery and chemical literature mining must interpret molecular images and generate outputs consistent with 3D geometry and stereochemistry. Most molecular language models rely on strings or graphs, while vision-language models often miss stereochemical details and struggle to map continuous 3D structures into discrete tokens. We propose DeepMoLM: Deep Molecular Language M odeling, a dual-view framework that grounds high-resolution molecular images in geometric invariants derived from molecular conformations. DeepMoLM preserves high-frequency evidence from 1024 $\times$ 1024 inputs, encodes conformer neighborhoods as discrete Extended 3-Dimensional Fingerprints, and fuses visual and geometric streams with cross-attention, enabling physically grounded generation without atom coordinates. DeepMoLM improves PubChem captioning with a 12.3% relative METEOR gain over the strongest generalist baseline while staying competitive with specialist methods. It produces valid numeric outputs for all property queries and attains MAE 13.64 g/mol on Molecular Weight and 37.89 on Complexity in the specialist setting. On ChEBI-20 description generation from images, it exceeds generalist baselines and matches state-of- the-art vision-language models. Code is available at https://github.com/1anj/DeepMoLM.
Structure-Aware Contrastive Learning with Fine-Grained Binding Representations for Drug Discovery
Sep 18, 2025



Accurate identification of drug-target interactions (DTI) remains a central challenge in computational pharmacology, where sequence-based methods offer scalability. This work introduces a sequence-based drug-target interaction framework that integrates structural priors into protein representations while maintaining high-throughput screening capability. Evaluated across multiple benchmarks, the model achieves state-of-the-art performance on Human and BioSNAP datasets and remains competitive on BindingDB. In virtual screening tasks, it surpasses prior methods on LIT-PCBA, yielding substantial gains in AUROC and BEDROC. Ablation studies confirm the critical role of learned aggregation, bilinear attention, and contrastive alignment in enhancing predictive robustness. Embedding visualizations reveal improved spatial correspondence with known binding pockets and highlight interpretable attention patterns over ligand-residue contacts. These results validate the framework's utility for scalable and structure-aware DTI prediction.
IC-Custom: Diverse Image Customization via In-Context Learning
Jul 02, 2025Image customization, a crucial technique for industrial media production, aims to generate content that is consistent with reference images. However, current approaches conventionally separate image customization into position-aware and position-free customization paradigms and lack a universal framework for diverse customization, limiting their applications across various scenarios. To overcome these limitations, we propose IC-Custom, a unified framework that seamlessly integrates position-aware and position-free image customization through in-context learning. IC-Custom concatenates reference images with target images to a polyptych, leveraging DiT's multi-modal attention mechanism for fine-grained token-level interactions. We introduce the In-context Multi-Modal Attention (ICMA) mechanism with learnable task-oriented register tokens and boundary-aware positional embeddings to enable the model to correctly handle different task types and distinguish various inputs in polyptych configurations. To bridge the data gap, we carefully curated a high-quality dataset of 12k identity-consistent samples with 8k from real-world sources and 4k from high-quality synthetic data, avoiding the overly glossy and over-saturated synthetic appearance. IC-Custom supports various industrial applications, including try-on, accessory placement, furniture arrangement, and creative IP customization. Extensive evaluations on our proposed ProductBench and the publicly available DreamBench demonstrate that IC-Custom significantly outperforms community workflows, closed-source models, and state-of-the-art open-source approaches. IC-Custom achieves approximately 73% higher human preference across identity consistency, harmonicity, and text alignment metrics, while training only 0.4% of the original model parameters. Project page: https://liyaowei-stu.github.io/project/IC_Custom
Adapting Vision-Language Foundation Model for Next Generation Medical Ultrasound Image Analysis
Jun 11, 2025Medical ultrasonography is an essential imaging technique for examining superficial organs and tissues, including lymph nodes, breast, and thyroid. It employs high-frequency ultrasound waves to generate detailed images of the internal structures of the human body. However, manually contouring regions of interest in these images is a labor-intensive task that demands expertise and often results in inconsistent interpretations among individuals. Vision-language foundation models, which have excelled in various computer vision applications, present new opportunities for enhancing ultrasound image analysis. Yet, their performance is hindered by the significant differences between natural and medical imaging domains. This research seeks to overcome these challenges by developing domain adaptation methods for vision-language foundation models. In this study, we explore the fine-tuning pipeline for vision-language foundation models by utilizing large language model as text refiner with special-designed adaptation strategies and task-driven heads. Our approach has been extensively evaluated on six ultrasound datasets and two tasks: segmentation and classification. The experimental results show that our method can effectively improve the performance of vision-language foundation models for ultrasound image analysis, and outperform the existing state-of-the-art vision-language and pure foundation models. The source code of this study is available at https://github.com/jinggqu/NextGen-UIA.
The Application of Deep Learning for Lymph Node Segmentation: A Systematic Review
May 09, 2025Automatic lymph node segmentation is the cornerstone for advances in computer vision tasks for early detection and staging of cancer. Traditional segmentation methods are constrained by manual delineation and variability in operator proficiency, limiting their ability to achieve high accuracy. The introduction of deep learning technologies offers new possibilities for improving the accuracy of lymph node image analysis. This study evaluates the application of deep learning in lymph node segmentation and discusses the methodologies of various deep learning architectures such as convolutional neural networks, encoder-decoder networks, and transformers in analyzing medical imaging data across different modalities. Despite the advancements, it still confronts challenges like the shape diversity of lymph nodes, the scarcity of accurately labeled datasets, and the inadequate development of methods that are robust and generalizable across different imaging modalities. To the best of our knowledge, this is the first study that provides a comprehensive overview of the application of deep learning techniques in lymph node segmentation task. Furthermore, this study also explores potential future research directions, including multimodal fusion techniques, transfer learning, and the use of large-scale pre-trained models to overcome current limitations while enhancing cancer diagnosis and treatment planning strategies.
MLLA-UNet: Mamba-like Linear Attention in an Efficient U-Shape Model for Medical Image Segmentation
Oct 31, 2024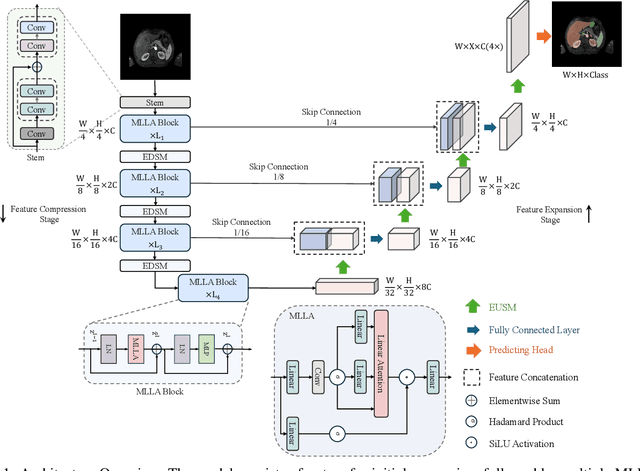
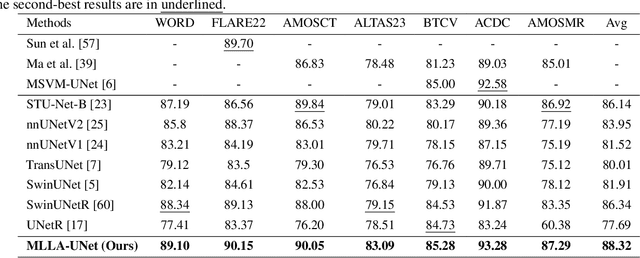
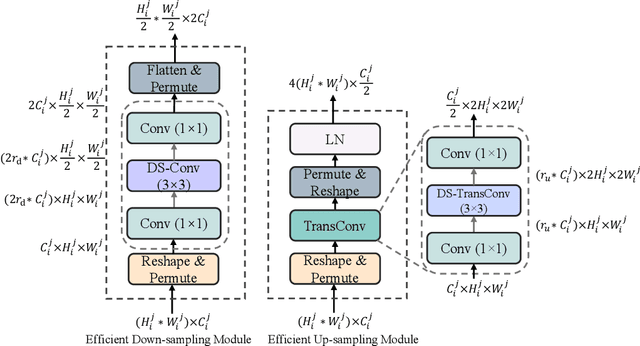
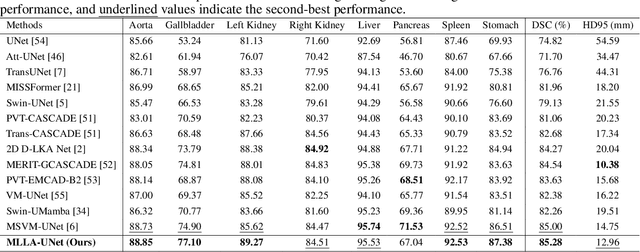
Recent advancements in medical imaging have resulted in more complex and diverse images, with challenges such as high anatomical variability, blurred tissue boundaries, low organ contrast, and noise. Traditional segmentation methods struggle to address these challenges, making deep learning approaches, particularly U-shaped architectures, increasingly prominent. However, the quadratic complexity of standard self-attention makes Transformers computationally prohibitive for high-resolution images. To address these challenges, we propose MLLA-UNet (Mamba-Like Linear Attention UNet), a novel architecture that achieves linear computational complexity while maintaining high segmentation accuracy through its innovative combination of linear attention and Mamba-inspired adaptive mechanisms, complemented by an efficient symmetric sampling structure for enhanced feature processing. Our architecture effectively preserves essential spatial features while capturing long-range dependencies at reduced computational complexity. Additionally, we introduce a novel sampling strategy for multi-scale feature fusion. Experiments demonstrate that MLLA-UNet achieves state-of-the-art performance on six challenging datasets with 24 different segmentation tasks, including but not limited to FLARE22, AMOS CT, and ACDC, with an average DSC of 88.32%. These results underscore the superiority of MLLA-UNet over existing methods. Our contributions include the novel 2D segmentation architecture and its empirical validation. The code is available via https://github.com/csyfjiang/MLLA-UNet.