 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Clinician-Friendly Platform for Ophthalmic Image Analysis Without Technical Barriers
Apr 22, 2025Artificial intelligence (AI) shows remarkable potential in medical imaging diagnostics, but current models typically require retraining when deployed across different clinical centers, limiting their widespread adoption. We introduce GlobeReady, a clinician-friendly AI platform that enables ocular disease diagnosis without retraining/fine-tuning or technical expertise. GlobeReady achieves high accuracy across imaging modalities: 93.9-98.5% for an 11-category fundus photo dataset and 87.2-92.7% for a 15-category OCT dataset. Through training-free local feature augmentation, it addresses domain shifts across centers and populations, reaching an average accuracy of 88.9% across five centers in China, 86.3% in Vietnam, and 90.2% in the UK. The built-in confidence-quantifiable diagnostic approach further boosted accuracy to 94.9-99.4% (fundus) and 88.2-96.2% (OCT), while identifying out-of-distribution cases at 86.3% (49 CFP categories) and 90.6% (13 OCT categories). Clinicians from multiple countries rated GlobeReady highly (average 4.6 out of 5) for its usability and clinical relevance. These results demonstrate GlobeReady's robust, scalable diagnostic capability and potential to support ophthalmic care without technical barriers.
AI-based Automatic Segmentation of Prostate on Multi-modality Images: A Review
Jul 09, 2024



Prostate cancer represents a major threat to health. Early detection is vital in reducing the mortality rate among prostate cancer patients. One approach involves using multi-modality (CT, MRI, US, etc.) computer-aided diagnosis (CAD) systems for the prostate region. However, prostate segmentation is challenging due to imperfections in the images and the prostate's complex tissue structure. The advent of precision medicine and a significant increase in clinical capacity have spurred the need for various data-driven tasks in the field of medical imaging. Recently, numerous machine learning and data mining tools have been integrated into various medical areas, including image segmentation. This article proposes a new classification method that differentiates supervision types, either in number or kind, during the training phase. Subsequently, we conducted a survey on artificial intelligence (AI)-based automatic prostate segmentation methods, examining the advantages and limitations of each. Additionally, we introduce variants of evaluation metrics for the verification and performance assessment of the segmentation method and summarize the current challenges. Finally, future research directions and development trends are discussed, reflecting the outcomes of our literature survey, suggesting high-precision detection and treatment of prostate cancer as a promising avenue.
Enhancing Diagnostic Reliability of Foundation Model with Uncertainty Estimation in OCT Images
Jun 18, 2024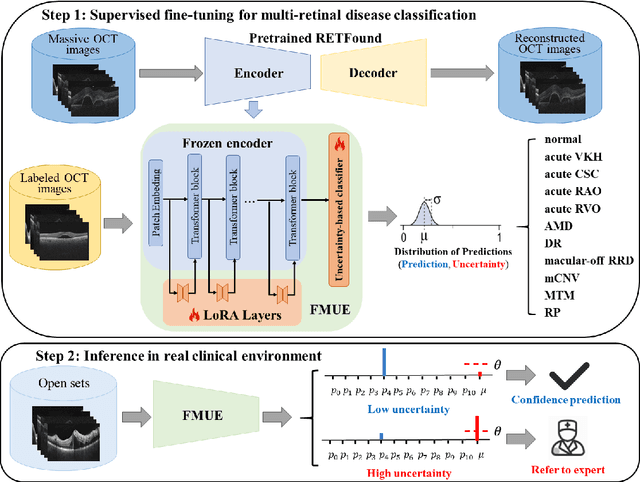
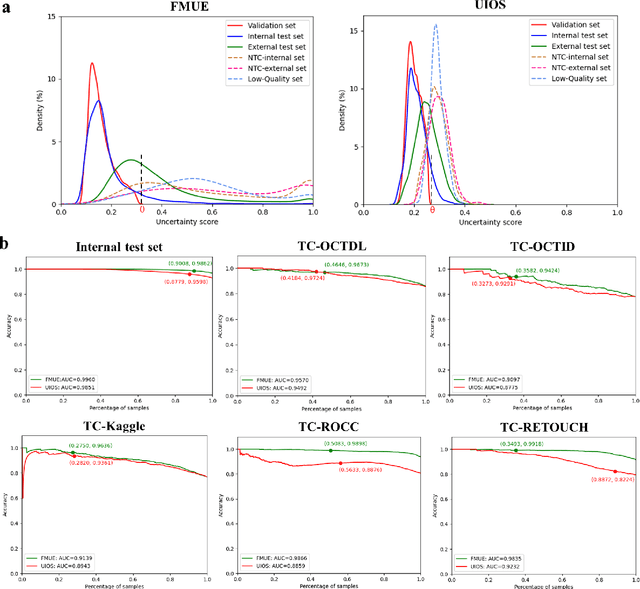
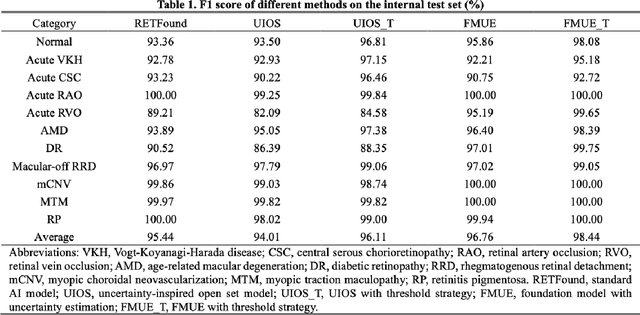
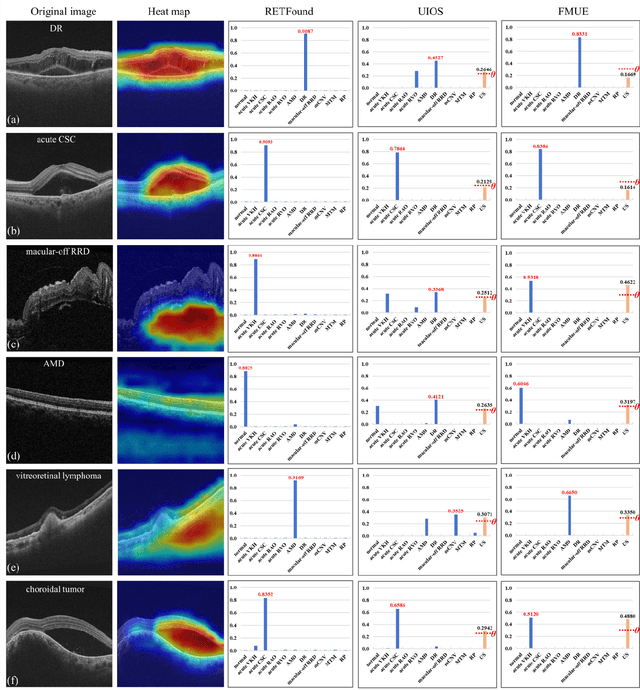
Inability to express the confidence level and detect unseen classes has limited the clinical implementation of artificial intelligence in the real-world. We developed a foundation model with uncertainty estimation (FMUE) to detect 11 retinal conditions on optical coherence tomography (OCT). In the internal test set, FMUE achieved a higher F1 score of 96.76% than two state-of-the-art algorithms, RETFound and UIOS, and got further improvement with thresholding strategy to 98.44%. In the external test sets obtained from other OCT devices, FMUE achieved an accuracy of 88.75% and 92.73% before and after thresholding. Our model is superior to two ophthalmologists with a higher F1 score (95.17% vs. 61.93% &71.72%). Besides, our model correctly predicts high uncertainty scores for samples with ambiguous features, of non-target-category diseases, or with low-quality to prompt manual checks and prevent misdiagnosis. FMUE provides a trustworthy method for automatic retinal anomalies detection in the real-world clinical open set environment.
Common and Rare Fundus Diseases Identification Using Vision-Language Foundation Model with Knowledge of Over 400 Diseases
Jun 13, 2024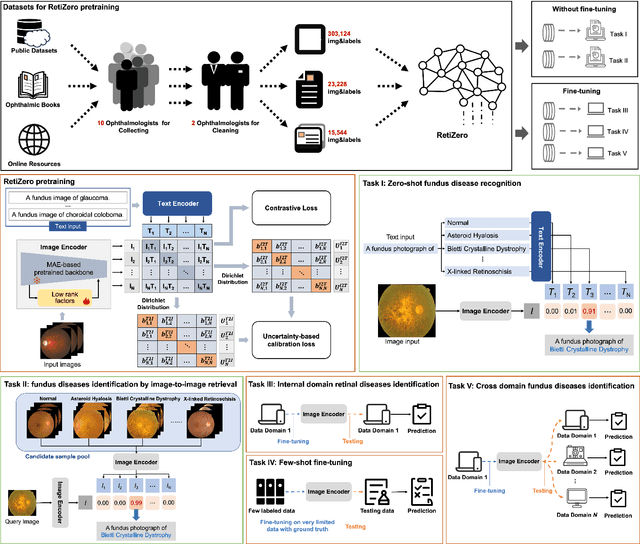
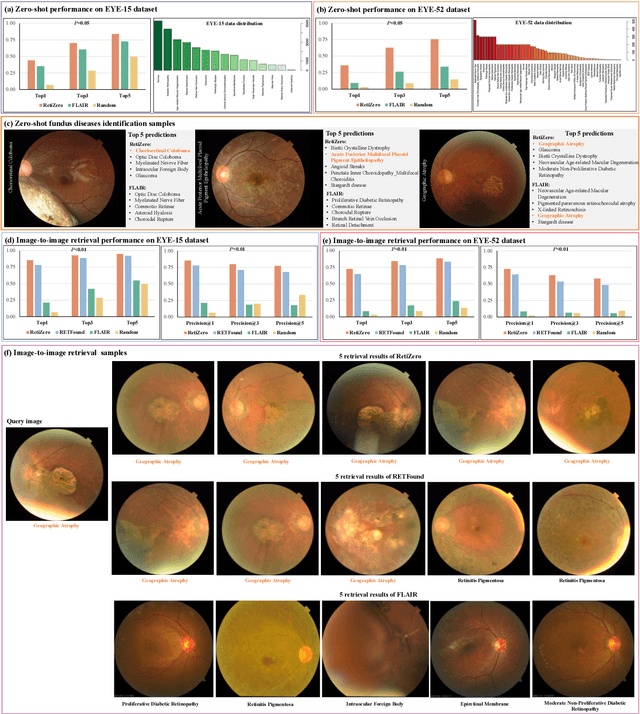
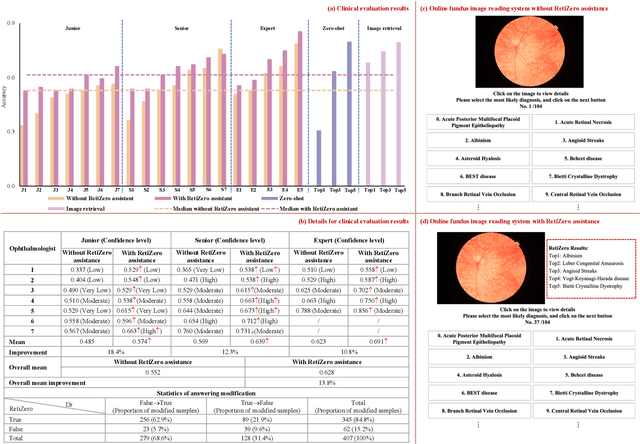
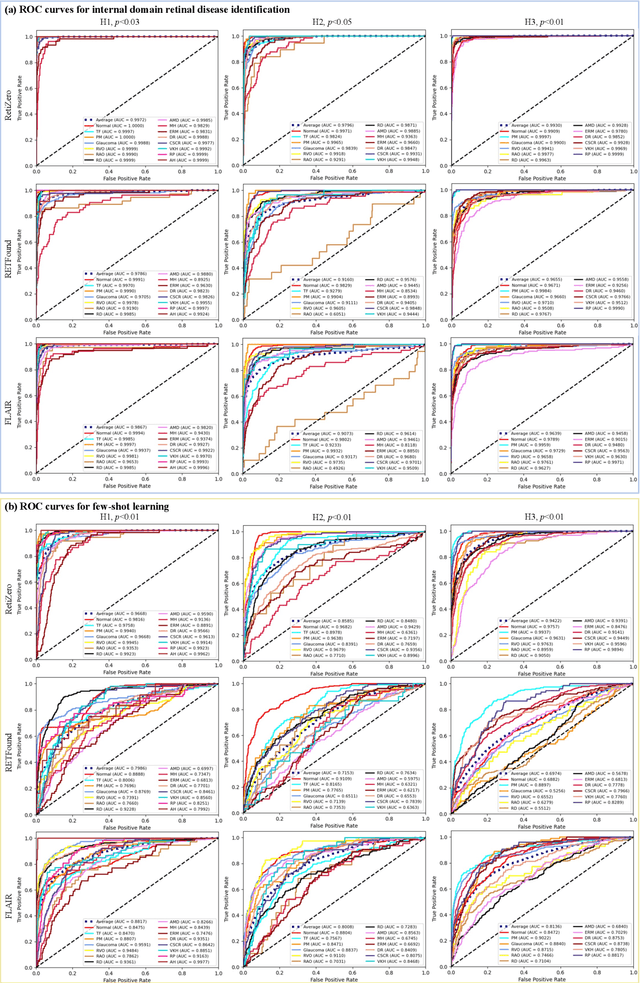
The current retinal artificial intelligence models were trained using data with a limited category of diseases and limited knowledge. In this paper, we present a retinal vision-language foundation model (RetiZero) with knowledge of over 400 fundus diseases. Specifically, we collected 341,896 fundus images paired with text descriptions from 29 publicly available datasets, 180 ophthalmic books, and online resources, encompassing over 400 fundus diseases across multiple countries and ethnicities. RetiZero achieved outstanding performance across various downstream tasks, including zero-shot retinal disease recognition, image-to-image retrieval, internal domain and cross-domain retinal disease classification, and few-shot fine-tuning. Specially, in the zero-shot scenario, RetiZero achieved a Top5 score of 0.8430 and 0.7561 on 15 and 52 fundus diseases respectively. In the image-retrieval task, RetiZero achieved a Top5 score of 0.9500 and 0.8860 on 15 and 52 retinal diseases respectively. Furthermore, clinical evaluations by ophthalmology experts from different countries demonstrate that RetiZero can achieve performance comparable to experienced ophthalmologists using zero-shot and image retrieval methods without requiring model retraining. These capabilities of retinal disease identification strengthen our RetiZero foundation model in clinical implementation.
Uncertainty-inspired Open Set Learning for Retinal Anomaly Identification
Apr 08, 2023
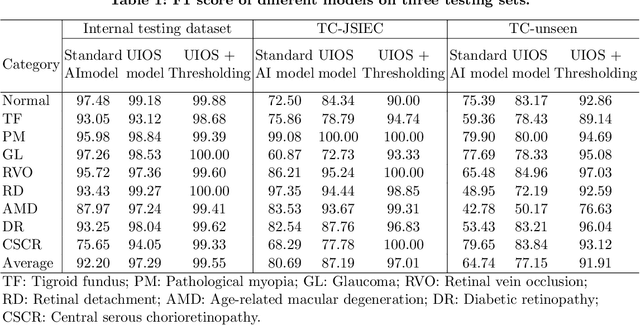


Failure to recognize samples from the classes unseen during training is a major limit of artificial intelligence (AI) in real-world implementation of retinal anomaly classification. To resolve this obstacle, we propose an uncertainty-inspired open-set (UIOS) model which was trained with fundus images of 9 common retinal conditions. Besides the probability of each category, UIOS also calculates an uncertainty score to express its confidence. Our UIOS model with thresholding strategy achieved an F1 score of 99.55%, 97.01% and 91.91% for the internal testing set, external testing set and non-typical testing set, respectively, compared to the F1 score of 92.20%, 80.69% and 64.74% by the standard AI model. Furthermore, UIOS correctly predicted high uncertainty scores, which prompted the need for a manual check, in the datasets of rare retinal diseases, low-quality fundus images, and non-fundus images. This work provides a robust method for real-world screening of retinal anomalies.
Accurate Retinal Vessel Segmentation via Octave Convolution Neural Network
Aug 11, 2019
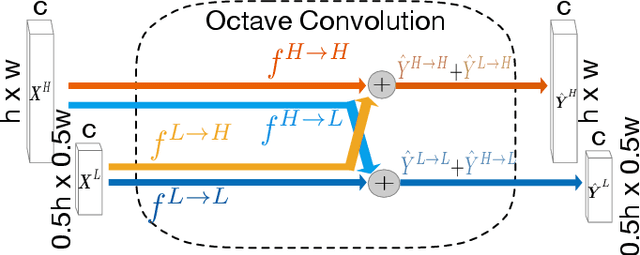
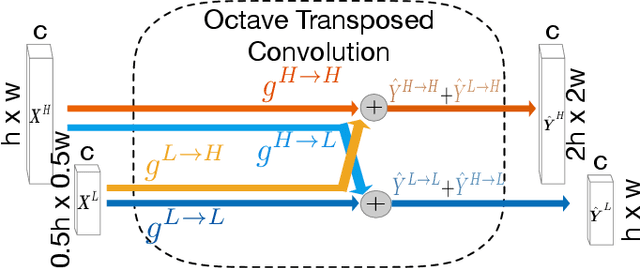
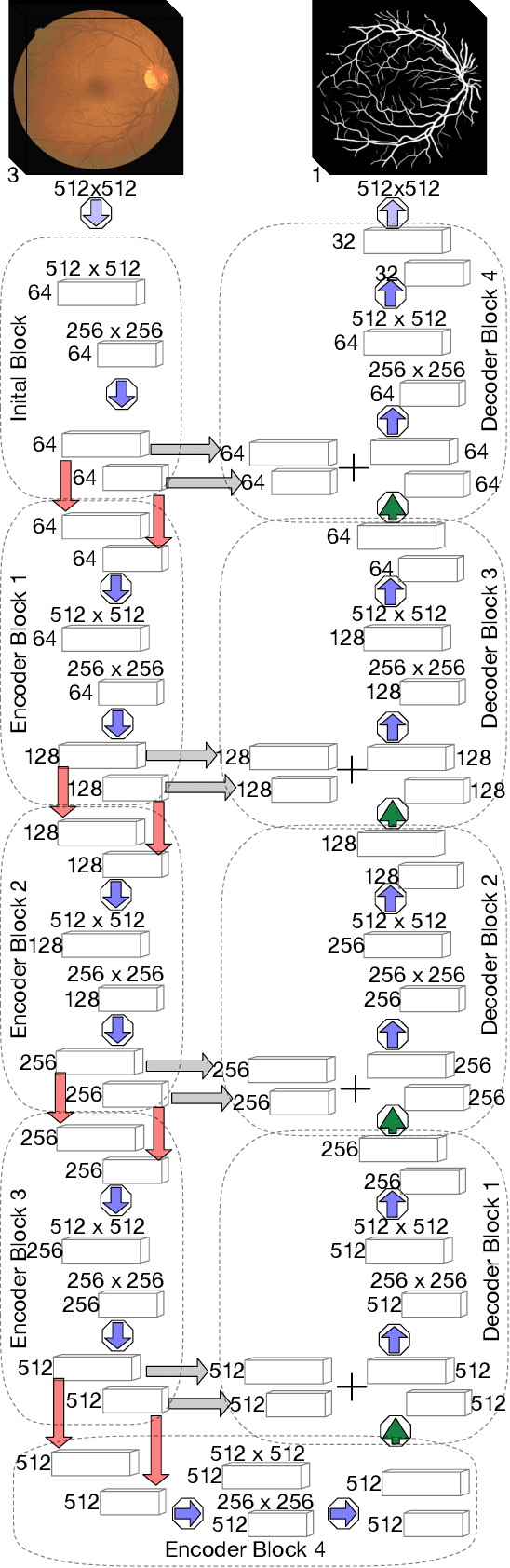
Retinal vessel segmentation is a crucial step in diagnosing and screening various diseases, including diabetes, ophthalmologic diseases, and cardiovascular diseases. In this paper, we propose an effective and efficient method for vessel segmentation in color fundus images using encoder-decoder based octave convolution network. Compared with other convolution networks utilizing vanilla convolution for feature extraction, the proposed method adopts octave convolution for learning multiple-spatial-frequency features, thus can better capture retinal vasculatures with varying sizes and shapes. It is demonstrated that the feature maps of low-frequency kernels respond mainly to the major vascular tree, whereas the high-frequency feature maps can better capture the fine details of thin vessels. To provide the network the capability of learning how to decode multifrequency features, we extend octave convolution and propose a new operation named octave transposed convolution. A novel architecture of convolutional neural network is proposed based on the encoder-decoder architecture of UNet, which can generate high resolution vessel segmentation in one single forward feeding. The proposed method is evaluated on four publicly available datasets, including DRIVE, STARE, CHASE_DB1, and HRF. Extensive experimental results demonstrate that the proposed approach achieves better or comparable performance to the state-of-the-art methods with fast processing speed.
A Hierarchical Image Matting Model for Blood Vessel Segmentation in Fundus images
Oct 09, 2017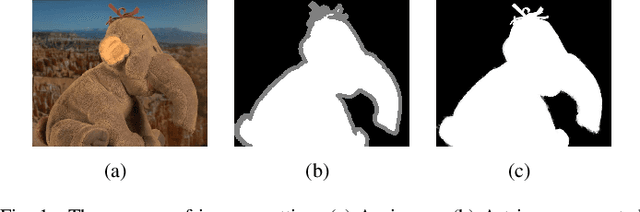
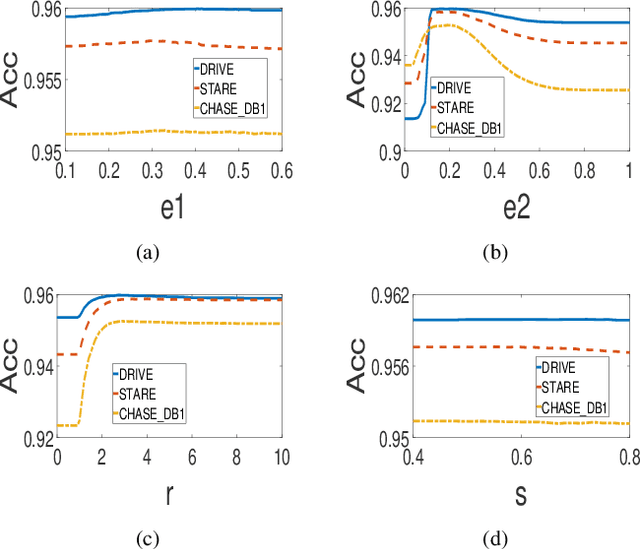
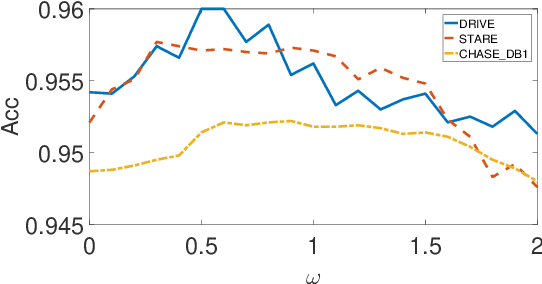
In this paper, a hierarchical image matting model is proposed to extract blood vessels from fundus images. More specifically, a hierarchical strategy utilizing the continuity and extendibility of retinal blood vessels is integrated into the image matting model for blood vessel segmentation. Normally the matting models require the user specified trimap, which separates the input image into three regions manually: the foreground, background and unknown regions. However, since creating a user specified trimap is a tedious and time-consuming task, region features of blood vessels are used to generate the trimap automatically in this paper. The proposed model has low computational complexity and outperforms many other state-ofart supervised and unsupervised methods in terms of accuracy, which achieves a vessel segmentation accuracy of 96:0%, 95:7% and 95:1% in an average time of 10:72s, 15:74s and 50:71s on images from three publicly available fundus image datasets DRIVE, STARE, and CHASE DB1, respectively.
Gaze2Segment: A Pilot Study for Integrating Eye-Tracking Technology into Medical Image Segmentation
Aug 10, 2016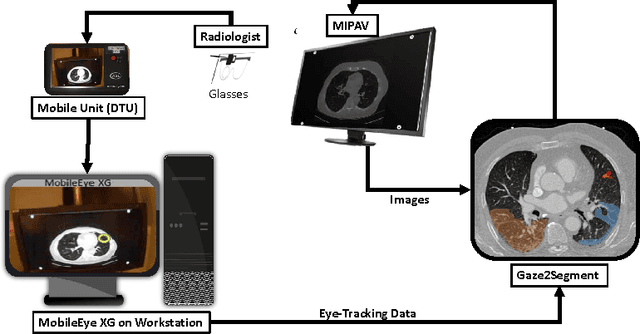
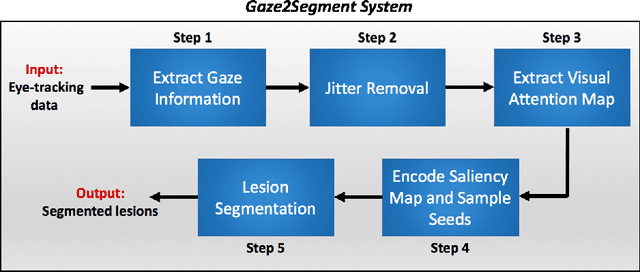
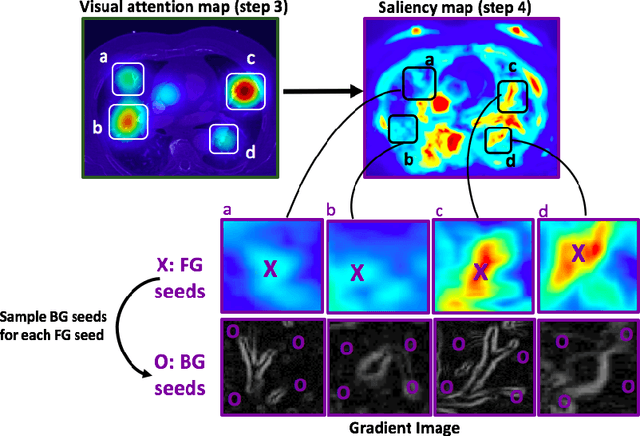
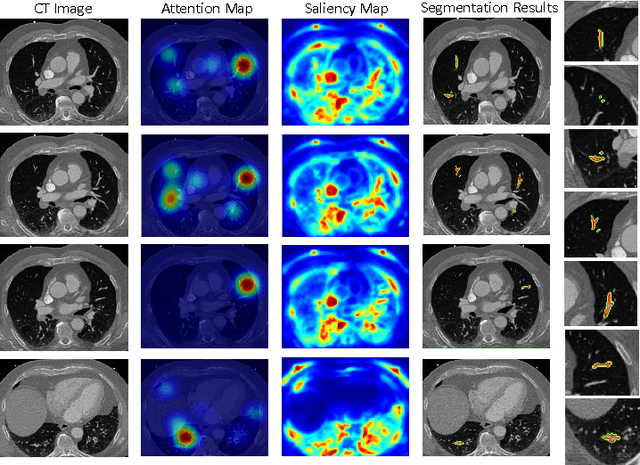
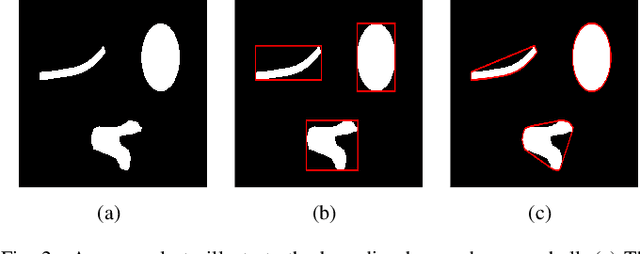
This study introduced a novel system, called Gaze2Segment, integrating biological and computer vision techniques to support radiologists' reading experience with an automatic image segmentation task. During diagnostic assessment of lung CT scans, the radiologists' gaze information were used to create a visual attention map. This map was then combined with a computer-derived saliency map, extracted from the gray-scale CT images. The visual attention map was used as an input for indicating roughly the location of a object of interest. With computer-derived saliency information, on the other hand, we aimed at finding foreground and background cues for the object of interest. At the final step, these cues were used to initiate a seed-based delineation process. Segmentation accuracy of the proposed Gaze2Segment was found to be 86% with dice similarity coefficient and 1.45 mm with Hausdorff distance. To the best of our knowledge, Gaze2Segment is the first true integration of eye-tracking technology into a medical image segmentation task without the need for any further user-interaction.
Ball-Scale Based Hierarchical Multi-Object Recognition in 3D Medical Images
Feb 05, 2010This paper investigates, using prior shape models and the concept of ball scale (b-scale), ways of automatically recognizing objects in 3D images without performing elaborate searches or optimization. That is, the goal is to place the model in a single shot close to the right pose (position, orientation, and scale) in a given image so that the model boundaries fall in the close vicinity of object boundaries in the image. This is achieved via the following set of key ideas: (a) A semi-automatic way of constructing a multi-object shape model assembly. (b) A novel strategy of encoding, via b-scale, the pose relationship between objects in the training images and their intensity patterns captured in b-scale images. (c) A hierarchical mechanism of positioning the model, in a one-shot way, in a given image from a knowledge of the learnt pose relationship and the b-scale image of the given image to be segmented. The evaluation results on a set of 20 routine clinical abdominal female and male CT data sets indicate the following: (1) Incorporating a large number of objects improves the recognition accuracy dramatically. (2) The recognition algorithm can be thought as a hierarchical framework such that quick replacement of the model assembly is defined as coarse recognition and delineation itself is known as finest recognition. (3) Scale yields useful information about the relationship between the model assembly and any given image such that the recognition results in a placement of the model close to the actual pose without doing any elaborate searches or optimization. (4) Effective object recognition can make delineation most accurate.