 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHI-TransPA: Hearing Impairments Translation Personal Assistant
Nov 14, 2025Hearing-impaired individuals often face significant barriers in daily communication due to the inherent challenges of producing clear speech. To address this, we introduce the Omni-Model paradigm into assistive technology and present HI-TransPA, an instruction-driven audio-visual personal assistant. The model fuses indistinct speech with lip dynamics, enabling both translation and dialogue within a single multimodal framework. To address the distinctive pronunciation patterns of hearing-impaired speech and the limited adaptability of existing models, we develop a multimodal preprocessing and curation pipeline that detects facial landmarks, stabilizes the lip region, and quantitatively evaluates sample quality. These quality scores guide a curriculum learning strategy that first trains on clean, high-confidence samples and progressively incorporates harder cases to strengthen model robustness. Architecturally, we employs a novel unified 3D-Resampler to efficiently encode the lip dynamics, which is critical for accurate interpretation. Experiments on purpose-built HI-Dialogue dataset show that HI-TransPA achieves state-of-the-art performance in both literal accuracy and semantic fidelity. Our work establishes a foundation for applying Omni-Models to assistive communication technology, providing an end-to-end modeling framework and essential processing tools for future research.
HoVer-Trans: Anatomy-aware HoVer-Transformer for ROI-free Breast Cancer Diagnosis in Ultrasound Images
May 17, 2022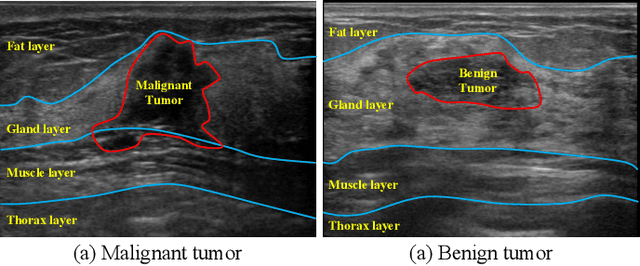
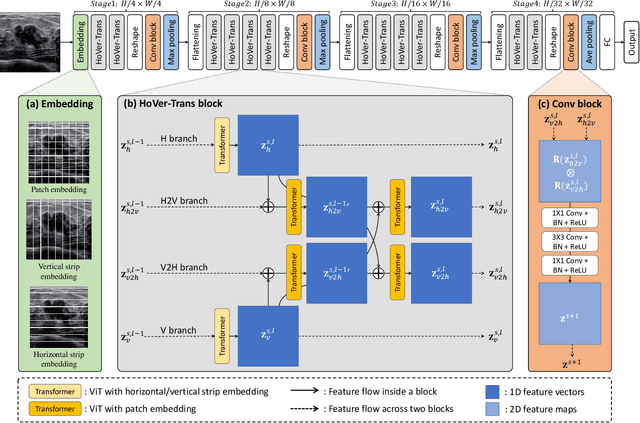

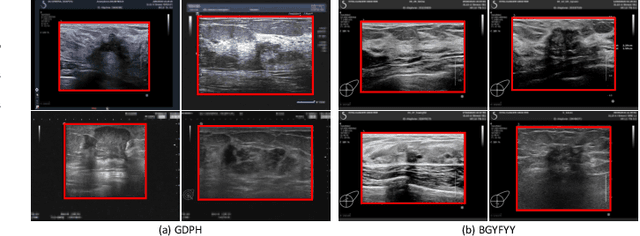
Ultrasonography is an important routine examination for breast cancer diagnosis, due to its non-invasive, radiation-free and low-cost properties. However, it is still not the first-line screening test for breast cancer due to its inherent limitations. It would be a tremendous success if we can precisely diagnose breast cancer by breast ultrasound images (BUS). Many learning-based computer-aided diagnostic methods have been proposed to achieve breast cancer diagnosis/lesion classification. However, most of them require a pre-define ROI and then classify the lesion inside the ROI. Conventional classification backbones, such as VGG16 and ResNet50, can achieve promising classification results with no ROI requirement. But these models lack interpretability, thus restricting their use in clinical practice. In this study, we propose a novel ROI-free model for breast cancer diagnosis in ultrasound images with interpretable feature representations. We leverage the anatomical prior knowledge that malignant and benign tumors have different spatial relationships between different tissue layers, and propose a HoVer-Transformer to formulate this prior knowledge. The proposed HoVer-Trans block extracts the inter- and intra-layer spatial information horizontally and vertically. We conduct and release an open dataset GDPH&GYFYY for breast cancer diagnosis in BUS. The proposed model is evaluated in three datasets by comparing with four CNN-based models and two vision transformer models via a five-fold cross validation. It achieves state-of-the-art classification performance with the best model interpretability.