 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEAT: Neuron-Based Early Exit for Large Reasoning Models
Feb 02, 2026Large Reasoning Models (LRMs) often suffer from \emph{overthinking}, a phenomenon in which redundant reasoning steps are generated after a correct solution has already been reached. Existing early reasoning exit methods primarily rely on output-level heuristics or trained probing models to skip redundant reasoning steps, thereby mitigating overthinking. However, these approaches typically require additional rollout computation or externally labeled datasets. In this paper, we propose \textbf{NEAT}, a \textbf{N}euron-based \textbf{E}arly re\textbf{A}soning exi\textbf{T} framework that monitors neuron-level activation dynamics to enable training-free early exits, without introducing additional test-time computation. NEAT identifies exit-associated neurons and tracks their activation patterns during reasoning to dynamically trigger early exit or suppress reflection, thereby reducing unnecessary reasoning while preserving solution quality. Experiments on four reasoning benchmarks across six models with different scales and architectures show that, for each model, NEAT achieves an average token reduction of 22\% to 28\% when averaged over the four benchmarks, while maintaining accuracy.
Beyond Prompting: Efficient and Robust Contextual Biasing for Speech LLMs via Logit-Space Integration (LOGIC)
Jan 21, 2026The rapid emergence of new entities -- driven by cultural shifts, evolving trends, and personalized user data -- poses a significant challenge for existing Speech Large Language Models (Speech LLMs). While these models excel at general conversational tasks, their static training knowledge limits their ability to recognize domain-specific terms such as contact names, playlists, or technical jargon. Existing solutions primarily rely on prompting, which suffers from poor scalability: as the entity list grows, prompting encounters context window limitations, increased inference latency, and the "lost-in-the-middle" phenomenon. An alternative approach, Generative Error Correction (GEC), attempts to rewrite transcripts via post-processing but frequently suffers from "over-correction", introducing hallucinations of entities that were never spoken. In this work, we introduce LOGIC (Logit-Space Integration for Contextual Biasing), an efficient and robust framework that operates directly in the decoding layer. Unlike prompting, LOGIC decouples context injection from input processing, ensuring constant-time complexity relative to prompt length. Extensive experiments using the Phi-4-MM model across 11 multilingual locales demonstrate that LOGIC achieves an average 9% relative reduction in Entity WER with a negligible 0.30% increase in False Alarm Rate.
SAFE-QAQ: End-to-End Slow-Thinking Audio-Text Fraud Detection via Reinforcement Learning
Jan 04, 2026Existing fraud detection methods predominantly rely on transcribed text, suffering from ASR errors and missing crucial acoustic cues like vocal tone and environmental context. This limits their effectiveness against complex deceptive strategies. To address these challenges, we first propose \textbf{SAFE-QAQ}, an end-to-end comprehensive framework for audio-based slow-thinking fraud detection. First, the SAFE-QAQ framework eliminates the impact of transcription errors on detection performance. Secondly, we propose rule-based slow-thinking reward mechanisms that systematically guide the system to identify fraud-indicative patterns by accurately capturing fine-grained audio details, through hierarchical reasoning processes. Besides, our framework introduces a dynamic risk assessment framework during live calls, enabling early detection and prevention of fraud. Experiments on the TeleAntiFraud-Bench demonstrate that SAFE-QAQ achieves dramatic improvements over existing methods in multiple key dimensions, including accuracy, inference efficiency, and real-time processing capabilities. Currently deployed and analyzing over 70,000 calls daily, SAFE-QAQ effectively automates complex fraud detection, reducing human workload and financial losses. Code: https://anonymous.4open.science/r/SAFE-QAQ.
HI-TransPA: Hearing Impairments Translation Personal Assistant
Nov 14, 2025Hearing-impaired individuals often face significant barriers in daily communication due to the inherent challenges of producing clear speech. To address this, we introduce the Omni-Model paradigm into assistive technology and present HI-TransPA, an instruction-driven audio-visual personal assistant. The model fuses indistinct speech with lip dynamics, enabling both translation and dialogue within a single multimodal framework. To address the distinctive pronunciation patterns of hearing-impaired speech and the limited adaptability of existing models, we develop a multimodal preprocessing and curation pipeline that detects facial landmarks, stabilizes the lip region, and quantitatively evaluates sample quality. These quality scores guide a curriculum learning strategy that first trains on clean, high-confidence samples and progressively incorporates harder cases to strengthen model robustness. Architecturally, we employs a novel unified 3D-Resampler to efficiently encode the lip dynamics, which is critical for accurate interpretation. Experiments on purpose-built HI-Dialogue dataset show that HI-TransPA achieves state-of-the-art performance in both literal accuracy and semantic fidelity. Our work establishes a foundation for applying Omni-Models to assistive communication technology, providing an end-to-end modeling framework and essential processing tools for future research.
PHRASED: Phrase Dictionary Biasing for Speech Translation
Jun 10, 2025Phrases are essential to understand the core concepts in conversations. However, due to their rare occurrence in training data, correct translation of phrases is challenging in speech translation tasks. In this paper, we propose a phrase dictionary biasing method to leverage pairs of phrases mapping from the source language to the target language. We apply the phrase dictionary biasing method to two types of widely adopted models, a transducer-based streaming speech translation model and a multimodal large language model. Experimental results show that the phrase dictionary biasing method outperforms phrase list biasing by 21% relatively for the streaming speech translation model. In addition, phrase dictionary biasing enables multimodal large language models to use external phrase information, achieving 85% relative improvement in phrase recall.
TeleAntiFraud-28k: An Audio-Text Slow-Thinking Dataset for Telecom Fraud Detection
Apr 01, 2025



The detection of telecom fraud faces significant challenges due to the lack of high-quality multimodal training data that integrates audio signals with reasoning-oriented textual analysis. To address this gap, we present TeleAntiFraud-28k, the first open-source audio-text slow-thinking dataset specifically designed for automated telecom fraud analysis. Our dataset is constructed through three strategies: (1) Privacy-preserved text-truth sample generation using automatically speech recognition (ASR)-transcribed call recordings (with anonymized original audio), ensuring real-world consistency through text-to-speech (TTS) model regeneration; (2) Semantic enhancement via large language model (LLM)-based self-instruction sampling on authentic ASR outputs to expand scenario coverage; (3) Multi-agent adversarial synthesis that simulates emerging fraud tactics through predefined communication scenarios and fraud typologies. The generated dataset contains 28,511 rigorously processed speech-text pairs, complete with detailed annotations for fraud reasoning. The dataset is divided into three tasks: scenario classification, fraud detection, fraud type classification. Furthermore, we construct TeleAntiFraud-Bench, a standardized evaluation benchmark comprising proportionally sampled instances from the dataset, to facilitate systematic testing of model performance on telecom fraud detection tasks. We also contribute a production-optimized supervised fine-tuning (SFT) model trained on hybrid real/synthetic data, while open-sourcing the data processing framework to enable community-driven dataset expansion. This work establishes a foundational framework for multimodal anti-fraud research while addressing critical challenges in data privacy and scenario diversity. The project will be released at https://github.com/JimmyMa99/TeleAntiFraud.
SARChat-Bench-2M: A Multi-Task Vision-Language Benchmark for SAR Image Interpretation
Feb 12, 2025In the field of synthetic aperture radar (SAR) remote sensing image interpretation, although Vision language models (VLMs) have made remarkable progress in natural language processing and image understanding, their applications remain limited in professional domains due to insufficient domain expertise. This paper innovatively proposes the first large-scale multimodal dialogue dataset for SAR images, named SARChat-2M, which contains approximately 2 million high-quality image-text pairs, encompasses diverse scenarios with detailed target annotations. This dataset not only supports several key tasks such as visual understanding and object detection tasks, but also has unique innovative aspects: this study develop a visual-language dataset and benchmark for the SAR domain, enabling and evaluating VLMs' capabilities in SAR image interpretation, which provides a paradigmatic framework for constructing multimodal datasets across various remote sensing vertical domains. Through experiments on 16 mainstream VLMs, the effectiveness of the dataset has been fully verified, and the first multi-task dialogue benchmark in the SAR field has been successfully established. The project will be released at https://github.com/JimmyMa99/SARChat, aiming to promote the in-depth development and wide application of SAR visual language models.
Streaming Speaker Change Detection and Gender Classification for Transducer-Based Multi-Talker Speech Translation
Feb 04, 2025



Streaming multi-talker speech translation is a task that involves not only generating accurate and fluent translations with low latency but also recognizing when a speaker change occurs and what the speaker's gender is. Speaker change information can be used to create audio prompts for a zero-shot text-to-speech system, and gender can help to select speaker profiles in a conventional text-to-speech model. We propose to tackle streaming speaker change detection and gender classification by incorporating speaker embeddings into a transducer-based streaming end-to-end speech translation model. Our experiments demonstrate that the proposed methods can achieve high accuracy for both speaker change detection and gender classification.
Language Models as Continuous Self-Evolving Data Engineers
Dec 19, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities on various tasks, while the further evolvement is limited to the lack of high-quality training data. In addition, traditional training approaches rely too much on expert-labeled data, setting an upper limit on the performance of LLMs. To address this issue, we propose a novel paradigm that enables LLMs to train itself by autonomously generating, cleaning, reviewing, and annotating data with preference information, named LANCE. Our approach demonstrates that LLMs can serve as continuous self-evolving data engineers, significantly reducing the time and cost of the post-training data construction process. Through iterative fine-tuning on different variants of the Qwen2, we validate the effectiveness of LANCE across various tasks, showing that it can continuously improve model performance and maintain high-quality data generation. Across eight benchmark dimensions, LANCE resulted in an average score enhancement of 3.36 for Qwen2-7B and 2.70 for Qwen2-7B-Instruct. This training paradigm with autonomous data construction not only reduces the reliance on human experts or external models but also ensures that the data aligns with human values and preferences, paving the way for the development of future superintelligent systems that can exceed human capabilities.
Failing Forward: Improving Generative Error Correction for ASR with Synthetic Data and Retrieval Augmentation
Oct 17, 2024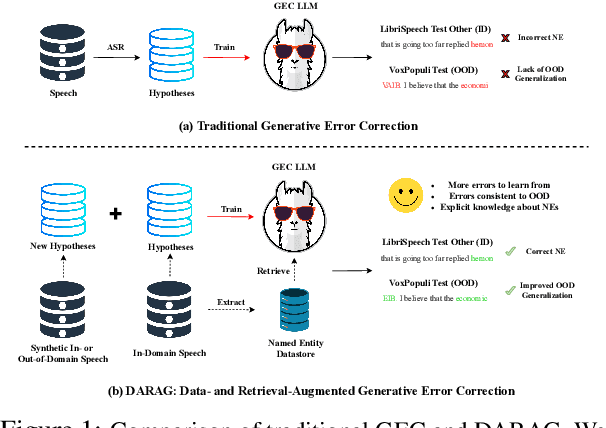
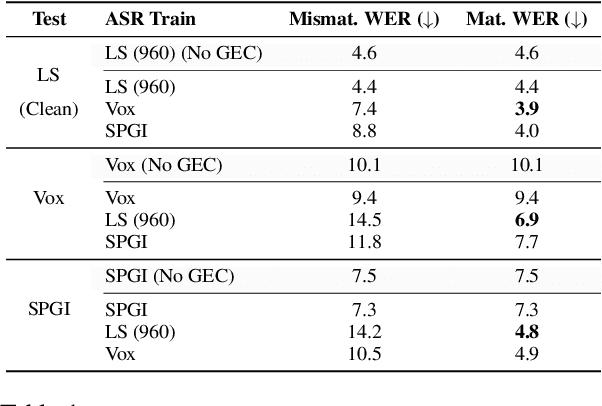
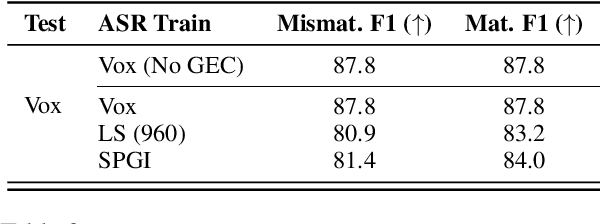
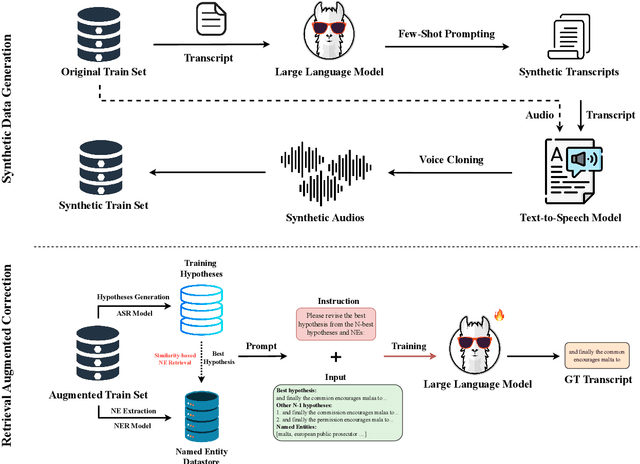
Generative Error Correction (GEC) has emerged as a powerful post-processing method to enhance the performance of Automatic Speech Recognition (ASR) systems. However, we show that GEC models struggle to generalize beyond the specific types of errors encountered during training, limiting their ability to correct new, unseen errors at test time, particularly in out-of-domain (OOD) scenarios. This phenomenon amplifies with named entities (NEs), where, in addition to insufficient contextual information or knowledge about the NEs, novel NEs keep emerging. To address these issues, we propose DARAG (Data- and Retrieval-Augmented Generative Error Correction), a novel approach designed to improve GEC for ASR in in-domain (ID) and OOD scenarios. We augment the GEC training dataset with synthetic data generated by prompting LLMs and text-to-speech models, thereby simulating additional errors from which the model can learn. For OOD scenarios, we simulate test-time errors from new domains similarly and in an unsupervised fashion. Additionally, to better handle named entities, we introduce retrieval-augmented correction by augmenting the input with entities retrieved from a database. Our approach is simple, scalable, and both domain- and language-agnostic. We experiment on multiple datasets and settings, showing that DARAG outperforms all our baselines, achieving 8\% -- 30\% relative WER improvements in ID and 10\% -- 33\% improvements in OOD settings.