 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Practical Aspects of End-to-End Multi-Talker Speech Recognition for Online and Offline Scenarios
Jun 17, 2025We extend the frameworks of Serialized Output Training (SOT) to address practical needs of both streaming and offline automatic speech recognition (ASR) applications. Our approach focuses on balancing latency and accuracy, catering to real-time captioning and summarization requirements. We propose several key improvements: (1) Leveraging Continuous Speech Separation (CSS) single-channel front-end with end-to-end (E2E) systems for highly overlapping scenarios, challenging the conventional wisdom of E2E versus cascaded setups. The CSS framework improves the accuracy of the ASR system by separating overlapped speech from multiple speakers. (2) Implementing dual models -- Conformer Transducer for streaming and Sequence-to-Sequence for offline -- or alternatively, a two-pass model based on cascaded encoders. (3) Exploring segment-based SOT (segSOT) which is better suited for offline scenarios while also enhancing readability of multi-talker transcriptions.
PHRASED: Phrase Dictionary Biasing for Speech Translation
Jun 10, 2025Phrases are essential to understand the core concepts in conversations. However, due to their rare occurrence in training data, correct translation of phrases is challenging in speech translation tasks. In this paper, we propose a phrase dictionary biasing method to leverage pairs of phrases mapping from the source language to the target language. We apply the phrase dictionary biasing method to two types of widely adopted models, a transducer-based streaming speech translation model and a multimodal large language model. Experimental results show that the phrase dictionary biasing method outperforms phrase list biasing by 21% relatively for the streaming speech translation model. In addition, phrase dictionary biasing enables multimodal large language models to use external phrase information, achieving 85% relative improvement in phrase recall.
Streaming Speaker Change Detection and Gender Classification for Transducer-Based Multi-Talker Speech Translation
Feb 04, 2025



Streaming multi-talker speech translation is a task that involves not only generating accurate and fluent translations with low latency but also recognizing when a speaker change occurs and what the speaker's gender is. Speaker change information can be used to create audio prompts for a zero-shot text-to-speech system, and gender can help to select speaker profiles in a conventional text-to-speech model. We propose to tackle streaming speaker change detection and gender classification by incorporating speaker embeddings into a transducer-based streaming end-to-end speech translation model. Our experiments demonstrate that the proposed methods can achieve high accuracy for both speaker change detection and gender classification.
Soft Language Identification for Language-Agnostic Many-to-One End-to-End Speech Translation
Jun 12, 2024


Language-agnostic many-to-one end-to-end speech translation models can convert audio signals from different source languages into text in a target language. These models do not need source language identification, which improves user experience. In some cases, the input language can be given or estimated. Our goal is to use this additional language information while preserving the quality of the other languages. We accomplish this by introducing a simple and effective linear input network. The linear input network is initialized as an identity matrix, which ensures that the model can perform as well as, or better than, the original model. Experimental results show that the proposed method can successfully enhance the specified language, while keeping the language-agnostic ability of the many-to-one ST models.
TS-SEP: Joint Diarization and Separation Conditioned on Estimated Speaker Embeddings
Mar 08, 2023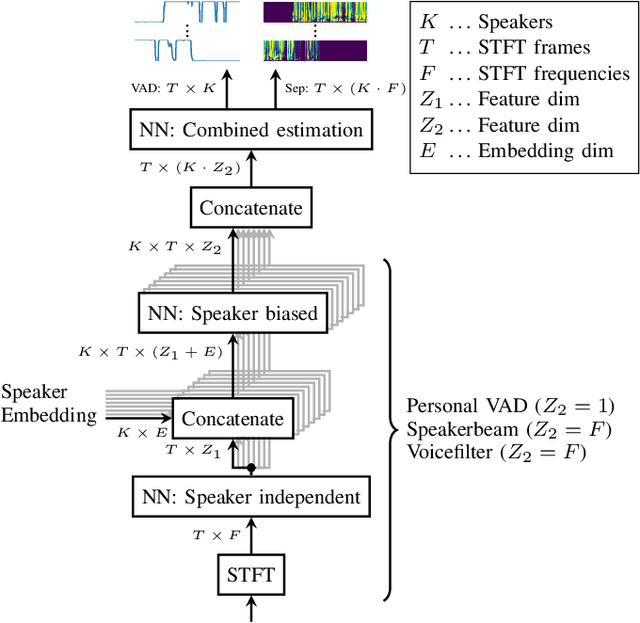
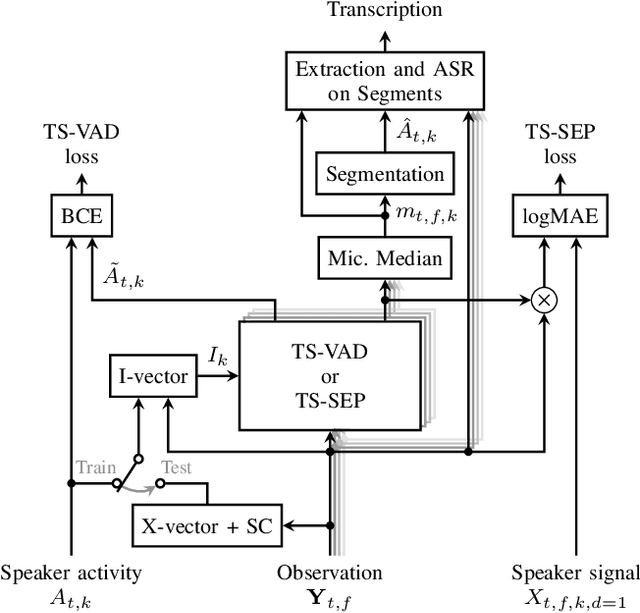
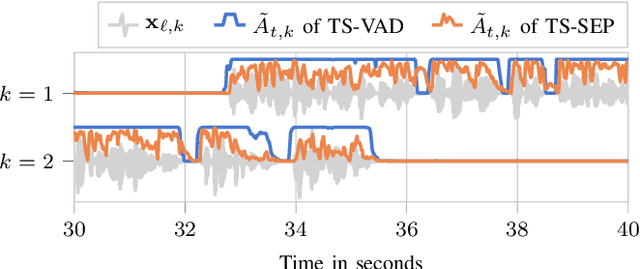
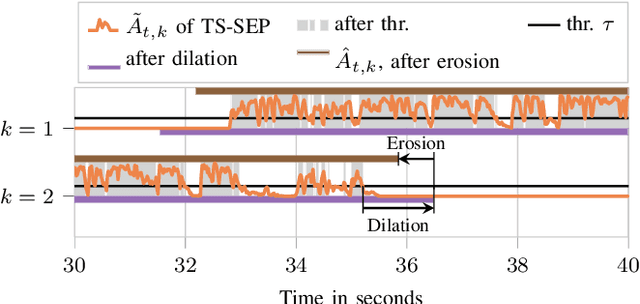
Since diarization and source separation of meeting data are closely related tasks, we here propose an approach to perform the two objectives jointly. It builds upon the target-speaker voice activity detection (TS-VAD) diarization approach, which assumes that initial speaker embeddings are available. We replace the final combined speaker activity estimation network of TS-VAD with a network that produces speaker activity estimates at a time-frequency resolution. Those act as masks for source extraction, either via masking or via beamforming. The technique can be applied both for single-channel and multi-channel input and, in both cases, achieves a new state-of-the-art word error rate (WER) on the LibriCSS meeting data recognition task. We further compute speaker-aware and speaker-agnostic WERs to isolate the contribution of diarization errors to the overall WER performance.
Tackling the Cocktail Fork Problem for Separation and Transcription of Real-World Soundtracks
Dec 14, 2022
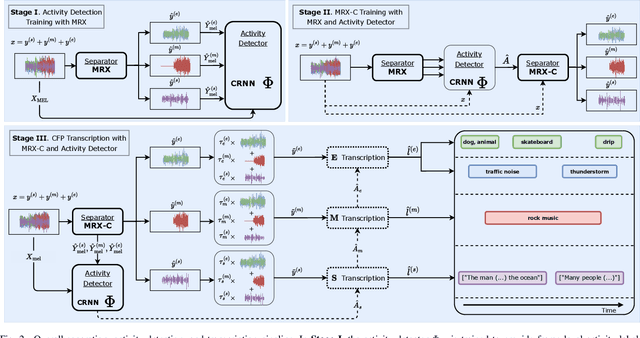
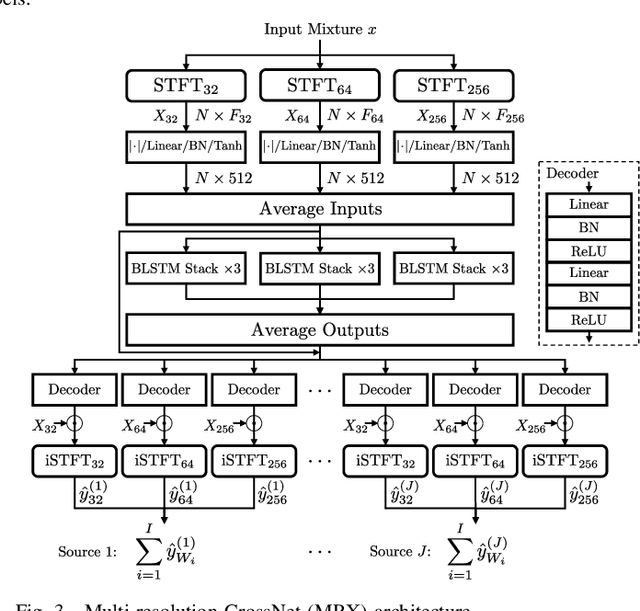
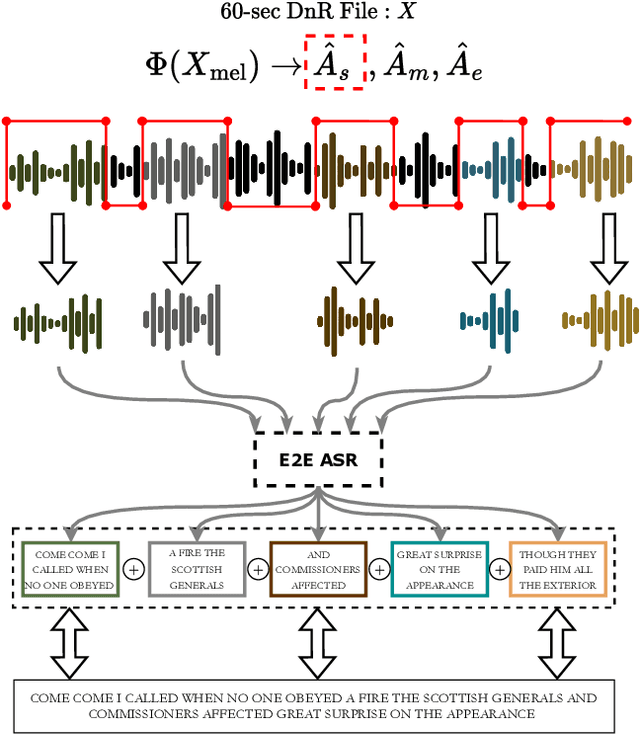
Emulating the human ability to solve the cocktail party problem, i.e., focus on a source of interest in a complex acoustic scene, is a long standing goal of audio source separation research. Much of this research investigates separating speech from noise, speech from speech, musical instruments from each other, or sound events from each other. In this paper, we focus on the cocktail fork problem, which takes a three-pronged approach to source separation by separating an audio mixture such as a movie soundtrack or podcast into the three broad categories of speech, music, and sound effects (SFX - understood to include ambient noise and natural sound events). We benchmark the performance of several deep learning-based source separation models on this task and evaluate them with respect to simple objective measures such as signal-to-distortion ratio (SDR) as well as objective metrics that better correlate with human perception. Furthermore, we thoroughly evaluate how source separation can influence downstream transcription tasks. First, we investigate the task of activity detection on the three sources as a way to both further improve source separation and perform transcription. We formulate the transcription tasks as speech recognition for speech and audio tagging for music and SFX. We observe that, while the use of source separation estimates improves transcription performance in comparison to the original soundtrack, performance is still sub-optimal due to artifacts introduced by the separation process. Therefore, we thoroughly investigate how remixing of the three separated source stems at various relative levels can reduce artifacts and consequently improve the transcription performance. We find that remixing music and SFX interferences at a target SNR of 17.5 dB reduces speech recognition word error rate, and similar impact from remixing is observed for tagging music and SFX content.
Reverberation as Supervision for Speech Separation
Nov 15, 2022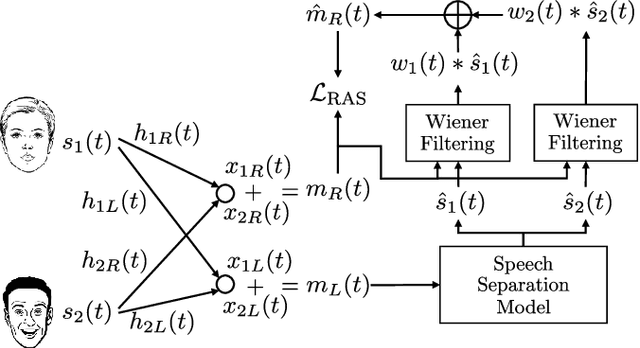

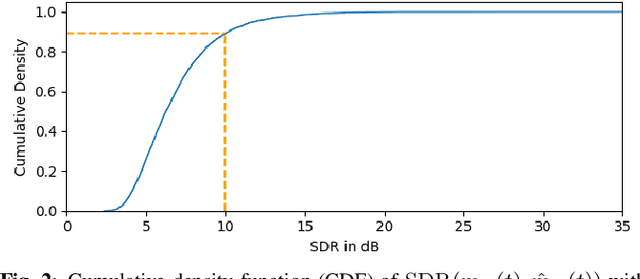
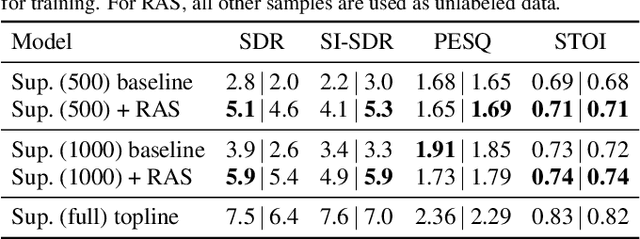
This paper proposes reverberation as supervision (RAS), a novel unsupervised loss function for single-channel reverberant speech separation. Prior methods for unsupervised separation required the synthesis of mixtures of mixtures or assumed the existence of a teacher model, making them difficult to consider as potential methods explaining the emergence of separation abilities in an animal's auditory system. We assume the availability of two-channel mixtures at training time, and train a neural network to separate the sources given one of the channels as input such that the other channel may be predicted from the separated sources. As the relationship between the room impulse responses (RIRs) of each channel depends on the locations of the sources, which are unknown to the network, the network cannot rely on learning that relationship. Instead, our proposed loss function fits each of the separated sources to the mixture in the target channel via Wiener filtering, and compares the resulting mixture to the ground-truth one. We show that minimizing the scale-invariant signal-to-distortion ratio (SI-SDR) of the predicted right-channel mixture with respect to the ground truth implicitly guides the network towards separating the left-channel sources. On a semi-supervised reverberant speech separation task based on the WHAMR! dataset, using training data where just 5% (resp., 10%) of the mixtures are labeled with associated isolated sources, we achieve 70% (resp., 78%) of the SI-SDR improvement obtained when training with supervision on the full training set, while a model trained only on the labeled data obtains 43% (resp., 45%).
An Exploration of Self-Supervised Pretrained Representations for End-to-End Speech Recognition
Oct 09, 2021
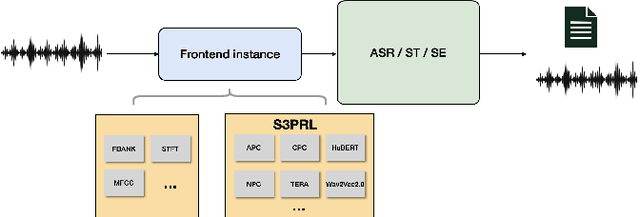
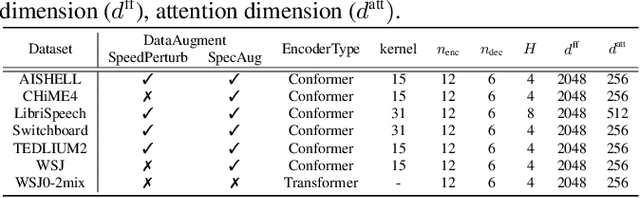
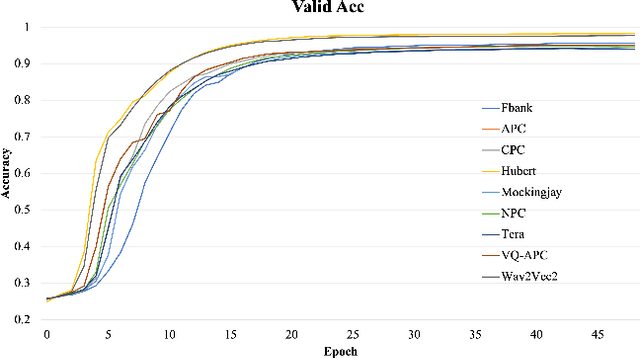
Self-supervised pretraining on speech data has achieved a lot of progress. High-fidelity representation of the speech signal is learned from a lot of untranscribed data and shows promising performance. Recently, there are several works focusing on evaluating the quality of self-supervised pretrained representations on various tasks without domain restriction, e.g. SUPERB. However, such evaluations do not provide a comprehensive comparison among many ASR benchmark corpora. In this paper, we focus on the general applications of pretrained speech representations, on advanced end-to-end automatic speech recognition (E2E-ASR) models. We select several pretrained speech representations and present the experimental results on various open-source and publicly available corpora for E2E-ASR. Without any modification of the back-end model architectures or training strategy, some of the experiments with pretrained representations, e.g., WSJ, WSJ0-2mix with HuBERT, reach or outperform current state-of-the-art (SOTA) recognition performance. Moreover, we further explore more scenarios for whether the pretraining representations are effective, such as the cross-language or overlapped speech. The scripts, configuratons and the trained models have been released in ESPnet to let the community reproduce our experiments and improve them.
Deep Learning based Multi-Source Localization with Source Splitting and its Effectiveness in Multi-Talker Speech Recognition
Feb 16, 2021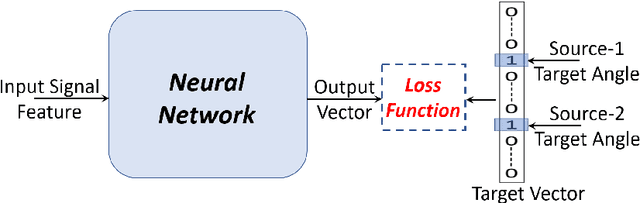
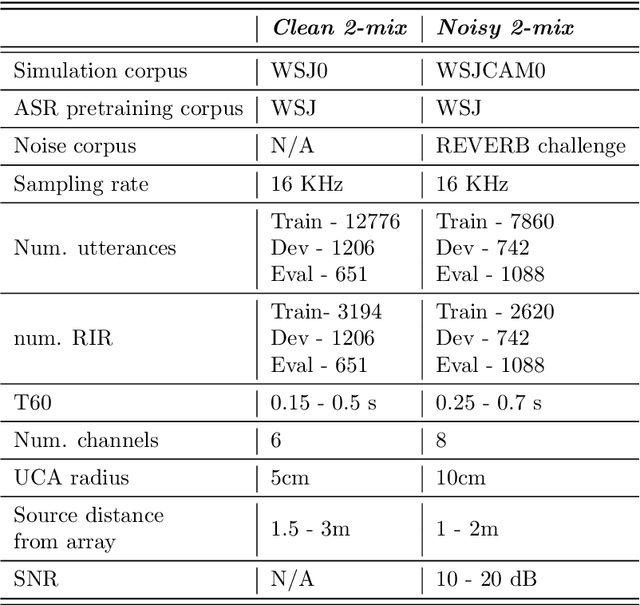
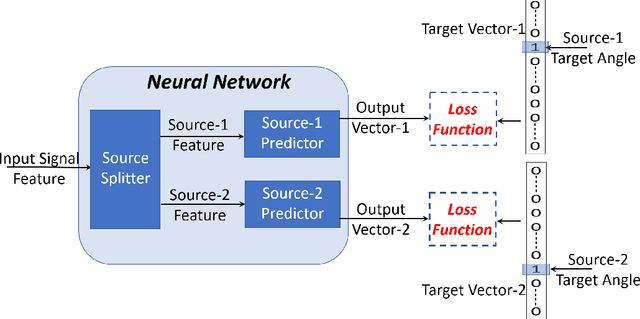
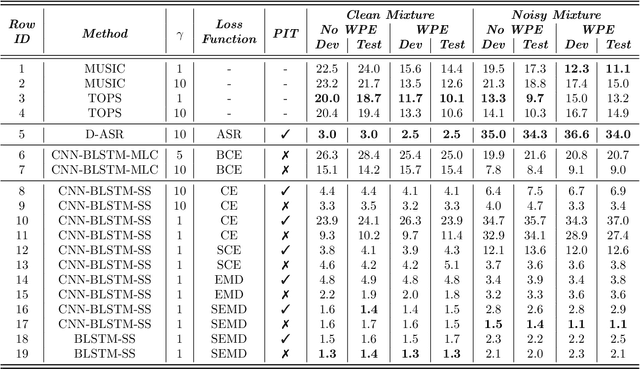
Multi-source localization is an important and challenging technique for multi-talker conversation analysis. This paper proposes a novel supervised learning method using deep neural networks to estimate the direction of arrival (DOA) of all the speakers simultaneously from the audio mixture. At the heart of the proposal is a source splitting mechanism that creates source-specific intermediate representations inside the network. This allows our model to give source-specific posteriors as the output unlike the traditional multi-label classification approach. Existing deep learning methods perform a frame level prediction, whereas our approach performs an utterance level prediction by incorporating temporal selection and averaging inside the network to avoid post-processing. We also experiment with various loss functions and show that a variant of earth mover distance (EMD) is very effective in classifying DOA at a very high resolution by modeling inter-class relationships. In addition to using the prediction error as a metric for evaluating our localization model, we also establish its potency as a frontend with automatic speech recognition (ASR) as the downstream task. We convert the estimated DOAs into a feature suitable for ASR and pass it as an additional input feature to a strong multi-channel and multi-talker speech recognition baseline. This added input feature drastically improves the ASR performance and gives a word error rate (WER) of 6.3% on the evaluation data of our simulated noisy two speaker mixtures, while the baseline which doesn't use explicit localization input has a WER of 11.5%. We also perform ASR evaluation on real recordings with the overlapped set of the MC-WSJ-AV corpus in addition to simulated mixtures.
The 2020 ESPnet update: new features, broadened applications, performance improvements, and future plans
Dec 23, 2020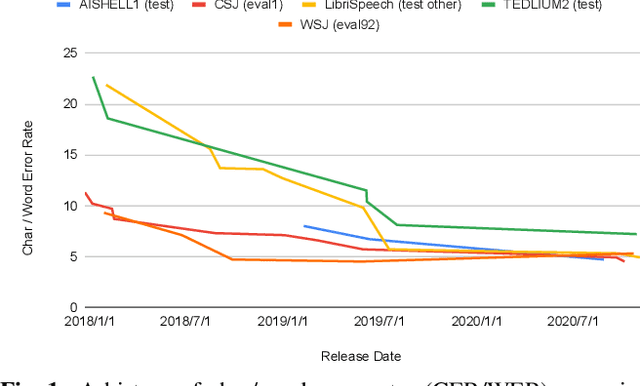

This paper describes the recent development of ESPnet (https://github.com/espnet/espnet), an end-to-end speech processing toolkit. This project was initiated in December 2017 to mainly deal with end-to-end speech recognition experiments based on sequence-to-sequence modeling. The project has grown rapidly and now covers a wide range of speech processing applications. Now ESPnet also includes text to speech (TTS), voice conversation (VC), speech translation (ST), and speech enhancement (SE) with support for beamforming, speech separation, denoising, and dereverberation. All applications are trained in an end-to-end manner, thanks to the generic sequence to sequence modeling properties, and they can be further integrated and jointly optimized. Also, ESPnet provides reproducible all-in-one recipes for these applications with state-of-the-art performance in various benchmarks by incorporating transformer, advanced data augmentation, and conformer. This project aims to provide up-to-date speech processing experience to the community so that researchers in academia and various industry scales can develop their technologies collaboratively.