 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Mitigating Hallucinations in Large Vision-Language Models by Refining Textual Embeddings
Nov 07, 2025In this work, we identify an inherent bias in prevailing LVLM architectures toward the language modality, largely resulting from the common practice of simply appending visual embeddings to the input text sequence. To address this, we propose a simple yet effective method that refines textual embeddings by integrating average-pooled visual features. Our approach demonstrably improves visual grounding and significantly reduces hallucinations on established benchmarks. While average pooling offers a straightforward, robust, and efficient means of incorporating visual information, we believe that more sophisticated fusion methods could further enhance visual grounding and cross-modal alignment. Given that the primary focus of this work is to highlight the modality imbalance and its impact on hallucinations -- and to show that refining textual embeddings with visual information mitigates this issue -- we leave exploration of advanced fusion strategies for future work.
Robustness to Multi-Modal Environment Uncertainty in MARL using Curriculum Learning
Oct 12, 2023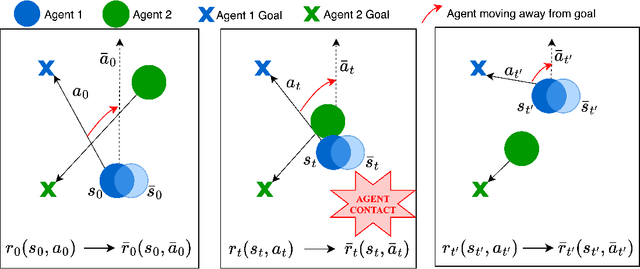
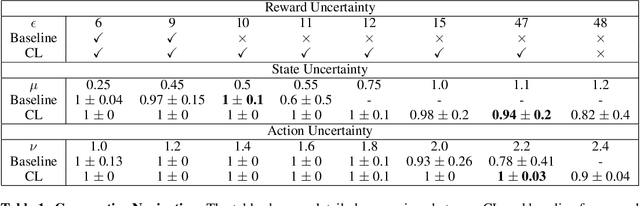
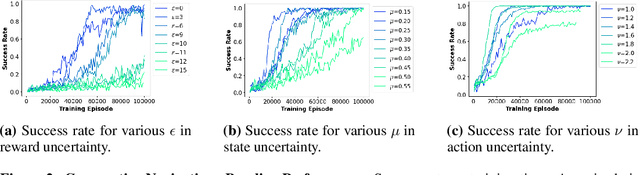
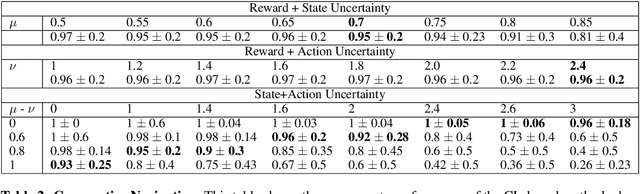
Multi-agent reinforcement learning (MARL) plays a pivotal role in tackling real-world challenges. However, the seamless transition of trained policies from simulations to real-world requires it to be robust to various environmental uncertainties. Existing works focus on finding Nash Equilibrium or the optimal policy under uncertainty in one environment variable (i.e. action, state or reward). This is because a multi-agent system itself is highly complex and unstationary. However, in real-world situation uncertainty can occur in multiple environment variables simultaneously. This work is the first to formulate the generalised problem of robustness to multi-modal environment uncertainty in MARL. To this end, we propose a general robust training approach for multi-modal uncertainty based on curriculum learning techniques. We handle two distinct environmental uncertainty simultaneously and present extensive results across both cooperative and competitive MARL environments, demonstrating that our approach achieves state-of-the-art levels of robustness.
Synthetic Wave-Geometric Impulse Responses for Improved Speech Dereverberation
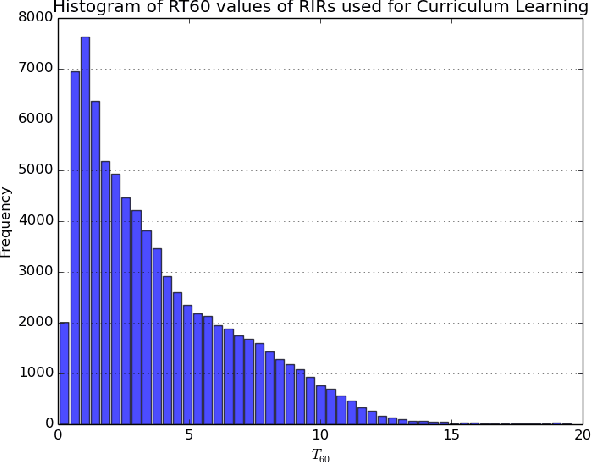
Dec 10, 2022We present a novel approach to improve the performance of learning-based speech dereverberation using accurate synthetic datasets. Our approach is designed to recover the reverb-free signal from a reverberant speech signal. We show that accurately simulating the low-frequency components of Room Impulse Responses (RIRs) is important to achieving good dereverberation. We use the GWA dataset that consists of synthetic RIRs generated in a hybrid fashion: an accurate wave-based solver is used to simulate the lower frequencies and geometric ray tracing methods simulate the higher frequencies. We demonstrate that speech dereverberation models trained on hybrid synthetic RIRs outperform models trained on RIRs generated by prior geometric ray tracing methods on four real-world RIR datasets.
Reverberation as Supervision for Speech Separation
Nov 15, 2022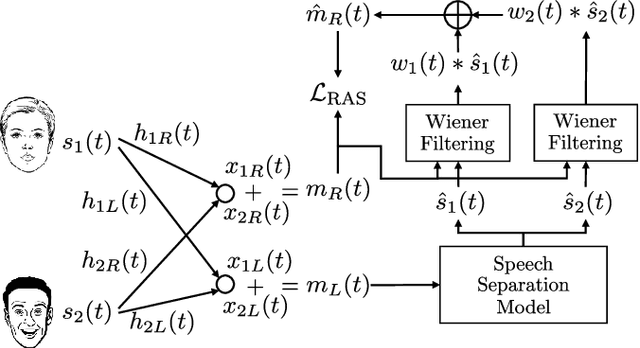

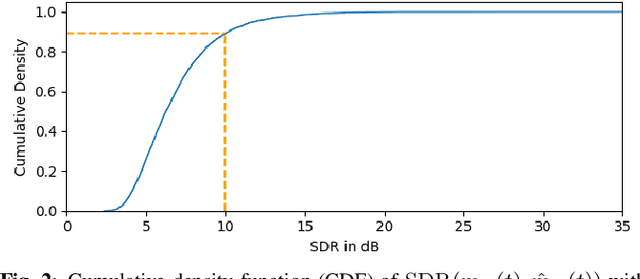
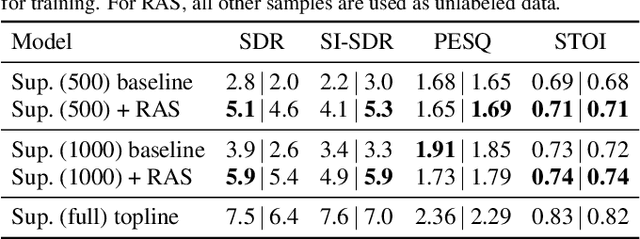
This paper proposes reverberation as supervision (RAS), a novel unsupervised loss function for single-channel reverberant speech separation. Prior methods for unsupervised separation required the synthesis of mixtures of mixtures or assumed the existence of a teacher model, making them difficult to consider as potential methods explaining the emergence of separation abilities in an animal's auditory system. We assume the availability of two-channel mixtures at training time, and train a neural network to separate the sources given one of the channels as input such that the other channel may be predicted from the separated sources. As the relationship between the room impulse responses (RIRs) of each channel depends on the locations of the sources, which are unknown to the network, the network cannot rely on learning that relationship. Instead, our proposed loss function fits each of the separated sources to the mixture in the target channel via Wiener filtering, and compares the resulting mixture to the ground-truth one. We show that minimizing the scale-invariant signal-to-distortion ratio (SI-SDR) of the predicted right-channel mixture with respect to the ground truth implicitly guides the network towards separating the left-channel sources. On a semi-supervised reverberant speech separation task based on the WHAMR! dataset, using training data where just 5% (resp., 10%) of the mixtures are labeled with associated isolated sources, we achieve 70% (resp., 78%) of the SI-SDR improvement obtained when training with supervision on the full training set, while a model trained only on the labeled data obtains 43% (resp., 45%).
GWA: A Large High-Quality Acoustic Dataset for Audio Processing
Apr 04, 2022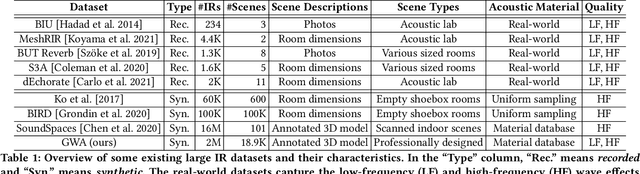
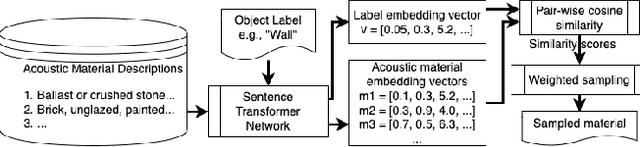

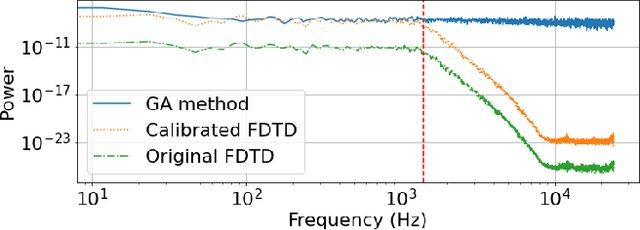
We present the Geometric-Wave Acoustic (GWA) dataset, a large-scale audio dataset of over 2 million synthetic room impulse responses (IRs) and their corresponding detailed geometric and simulation configurations. Our dataset samples acoustic environments from over 6.8K high-quality diverse and professionally designed houses represented as semantically labeled 3D meshes. We also present a novel real-world acoustic materials assignment scheme based on semantic matching that uses a sentence transformer model. We compute high-quality impulse responses corresponding to accurate low-frequency and high-frequency wave effects by automatically calibrating geometric acoustic ray-tracing with a finite-difference time-domain wave solver. We demonstrate the higher accuracy of our IRs by comparing with recorded IRs from complex real-world environments. The code and the full dataset will be released at the time of publication. Moreover, we highlight the benefits of GWA on audio deep learning tasks such as automated speech recognition, speech enhancement, and speech separation. We observe significant improvement over prior synthetic IR datasets in all tasks due to using our dataset.
Improving Reverberant Speech Separation with Multi-stage Training and Curriculum Learning
Jul 19, 2021
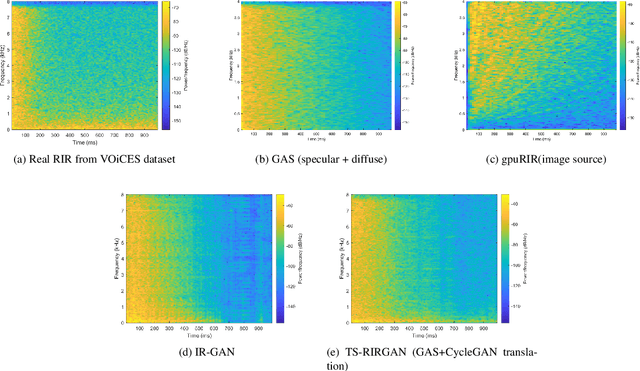
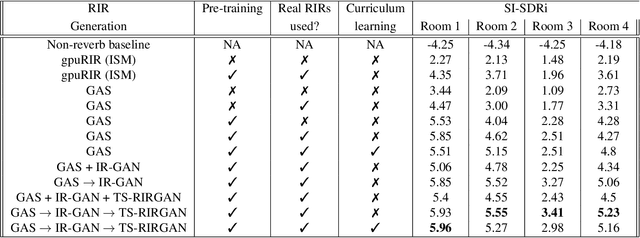
We present a novel approach that improves the performance of reverberant speech separation. Our approach is based on an accurate geometric acoustic simulator (GAS) which generates realistic room impulse responses (RIRs) by modeling both specular and diffuse reflections. We also propose three training methods - pre-training, multi-stage training and curriculum learning that significantly improve separation quality in the presence of reverberation. We also demonstrate that mixing the synthetic RIRs with a small number of real RIRs during training enhances separation performance. We evaluate our approach on reverberant mixtures generated from real, recorded data (in several different room configurations) from the VOiCES dataset. Our novel approach (curriculum learning+pre-training+multi-stage training) results in a significant relative improvement over prior techniques based on image source method (ISM).
Audio-Visual Decision Fusion for WFST-based and seq2seq Models
Jan 29, 2020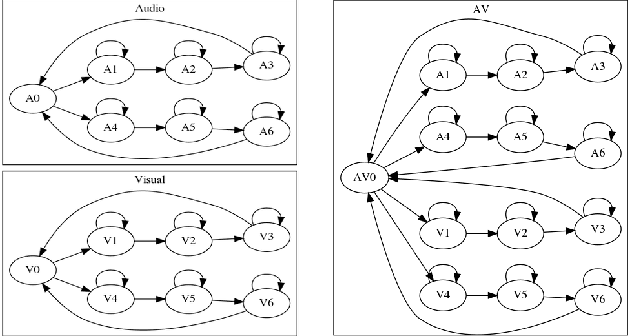
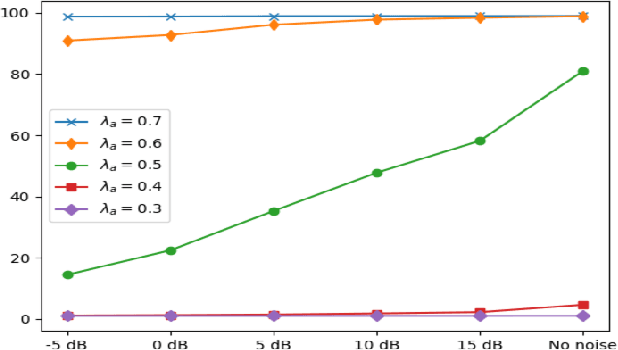
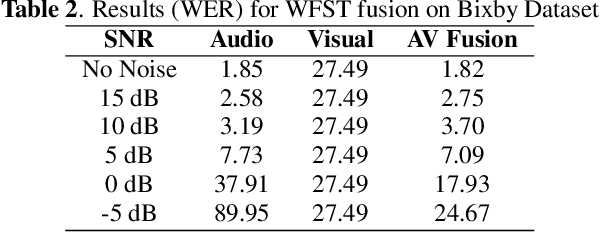
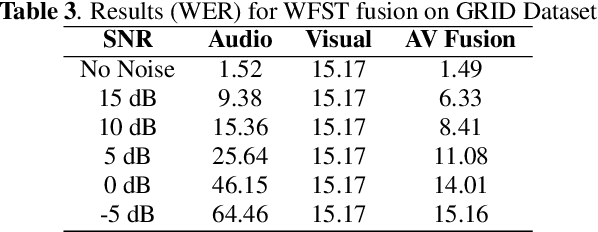
Under noisy conditions, speech recognition systems suffer from high Word Error Rates (WER). In such cases, information from the visual modality comprising the speaker lip movements can help improve the performance. In this work, we propose novel methods to fuse information from audio and visual modalities at inference time. This enables us to train the acoustic and visual models independently. First, we train separate RNN-HMM based acoustic and visual models. A common WFST generated by taking a special union of the HMM components is used for decoding using a modified Viterbi algorithm. Second, we train separate seq2seq acoustic and visual models. The decoding step is performed simultaneously for both modalities using shallow fusion while maintaining a common hypothesis beam. We also present results for a novel seq2seq fusion without the weighing parameter. We present results at varying SNR and show that our methods give significant improvements over acoustic-only WER.
LipReading with 3D-2D-CNN BLSTM-HMM and word-CTC models
Jun 25, 2019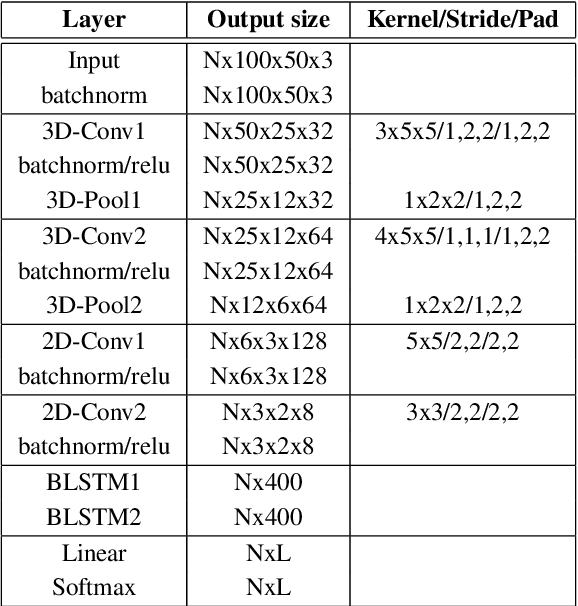
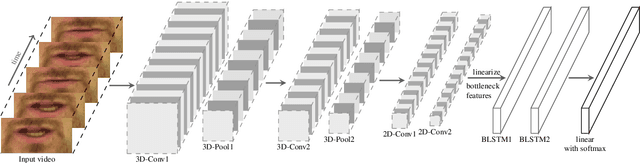
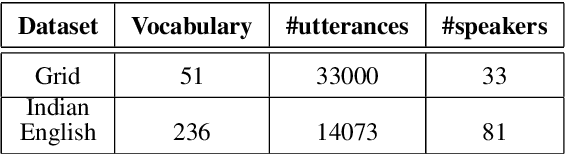

In recent years, deep learning based machine lipreading has gained prominence. To this end, several architectures such as LipNet, LCANet and others have been proposed which perform extremely well compared to traditional lipreading DNN-HMM hybrid systems trained on DCT features. In this work, we propose a simpler architecture of 3D-2D-CNN-BLSTM network with a bottleneck layer. We also present analysis of two different approaches for lipreading on this architecture. In the first approach, 3D-2D-CNN-BLSTM network is trained with CTC loss on characters (ch-CTC). Then BLSTM-HMM model is trained on bottleneck lip features (extracted from 3D-2D-CNN-BLSTM ch-CTC network) in a traditional ASR training pipeline. In the second approach, same 3D-2D-CNN-BLSTM network is trained with CTC loss on word labels (w-CTC). The first approach shows that bottleneck features perform better compared to DCT features. Using the second approach on Grid corpus' seen speaker test set, we report $1.3\%$ WER - a $55\%$ improvement relative to LCANet. On unseen speaker test set we report $8.6\%$ WER which is $24.5\%$ improvement relative to LipNet. We also verify the method on a second dataset of $81$ speakers which we collected. Finally, we also discuss the effect of feature duplication on BLSTM-HMM model performance.
Global SNR Estimation of Speech Signals using Entropy and Uncertainty Estimates from Dropout Networks
Apr 12, 2018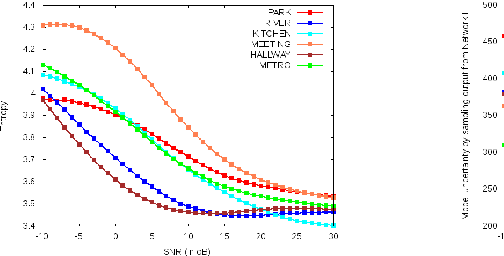
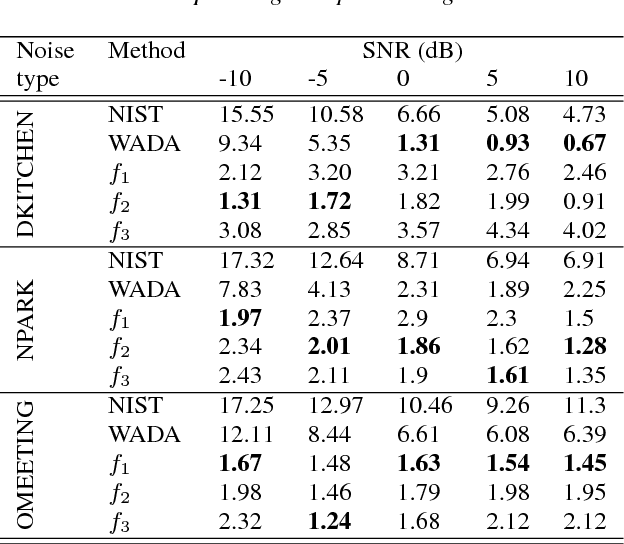
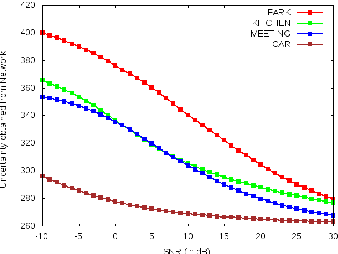
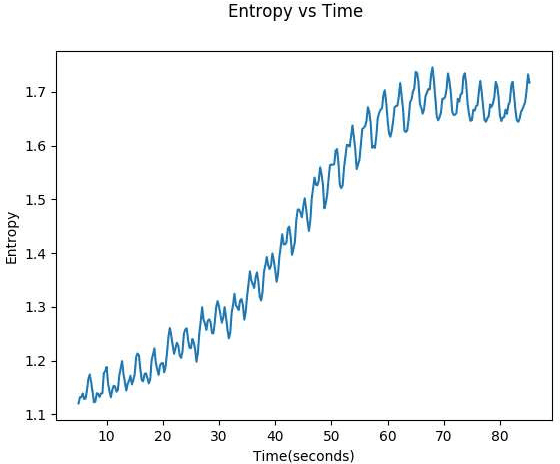
This paper demonstrates two novel methods to estimate the global SNR of speech signals. In both methods, Deep Neural Network-Hidden Markov Model (DNN-HMM) acoustic model used in speech recognition systems is leveraged for the additional task of SNR estimation. In the first method, the entropy of the DNN-HMM output is computed. Recent work on bayesian deep learning has shown that a DNN-HMM trained with dropout can be used to estimate model uncertainty by approximating it as a deep Gaussian process. In the second method, this approximation is used to obtain model uncertainty estimates. Noise specific regressors are used to predict the SNR from the entropy and model uncertainty. The DNN-HMM is trained on GRID corpus and tested on different noise profiles from the DEMAND noise database at SNR levels ranging from -10 dB to 30 dB.