 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Decision Fusion for WFST-based and seq2seq Models
Paper and Code
Jan 29, 2020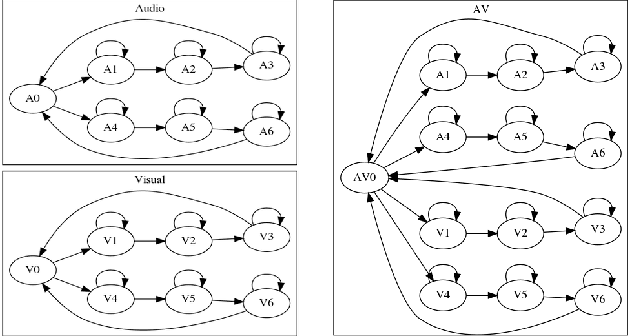
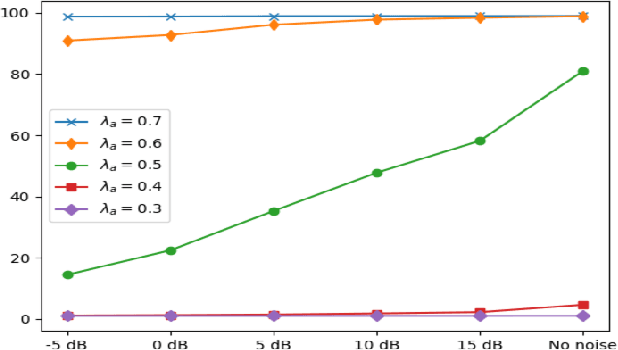
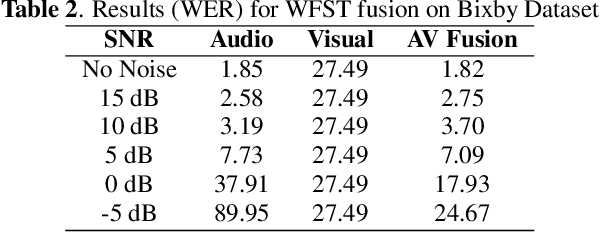
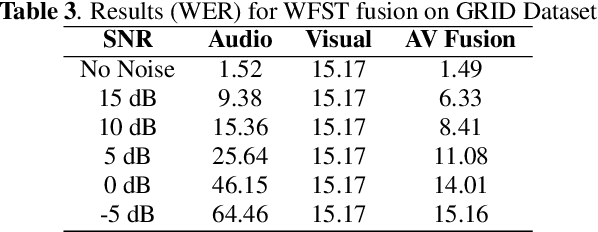
Under noisy conditions, speech recognition systems suffer from high Word Error Rates (WER). In such cases, information from the visual modality comprising the speaker lip movements can help improve the performance. In this work, we propose novel methods to fuse information from audio and visual modalities at inference time. This enables us to train the acoustic and visual models independently. First, we train separate RNN-HMM based acoustic and visual models. A common WFST generated by taking a special union of the HMM components is used for decoding using a modified Viterbi algorithm. Second, we train separate seq2seq acoustic and visual models. The decoding step is performed simultaneously for both modalities using shallow fusion while maintaining a common hypothesis beam. We also present results for a novel seq2seq fusion without the weighing parameter. We present results at varying SNR and show that our methods give significant improvements over acoustic-only WER.