 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Fence Estimation using Stereo Guidance and Adversarial Learning
Jul 03, 2020

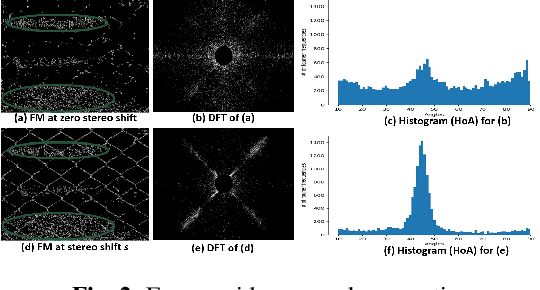
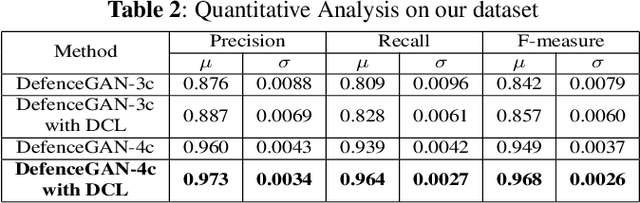
People capture memorable images of events and exhibits that are often occluded by a wire mesh loosely termed as fence. Recent works in removing fence have limited performance due to the difficulty in initial fence segmentation. This work aims to accurately segment fence using a novel fence guidance mask (FM) generated from stereo image pair. This binary guidance mask contains deterministic cues about the structure of fence and is given as additional input to the deep fence estimation model. We also introduce a directional connectivity loss (DCL), which is used alongside adversarial loss to precisely detect thin wires. Experimental results obtained on real world scenarios demonstrate the superiority of proposed method over state-of-the-art techniques.
Audio-Visual Decision Fusion for WFST-based and seq2seq Models
Jan 29, 2020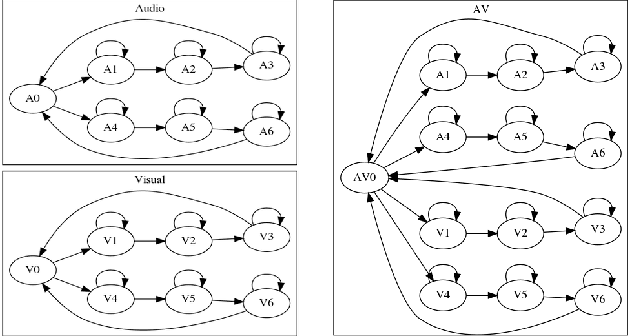
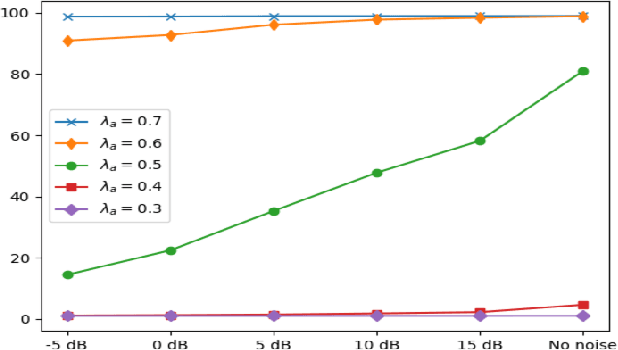
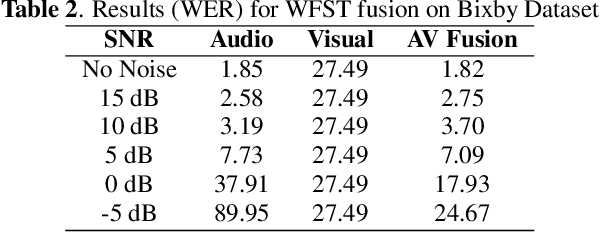
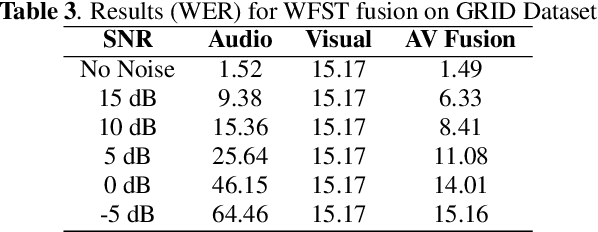
Under noisy conditions, speech recognition systems suffer from high Word Error Rates (WER). In such cases, information from the visual modality comprising the speaker lip movements can help improve the performance. In this work, we propose novel methods to fuse information from audio and visual modalities at inference time. This enables us to train the acoustic and visual models independently. First, we train separate RNN-HMM based acoustic and visual models. A common WFST generated by taking a special union of the HMM components is used for decoding using a modified Viterbi algorithm. Second, we train separate seq2seq acoustic and visual models. The decoding step is performed simultaneously for both modalities using shallow fusion while maintaining a common hypothesis beam. We also present results for a novel seq2seq fusion without the weighing parameter. We present results at varying SNR and show that our methods give significant improvements over acoustic-only WER.
LipReading with 3D-2D-CNN BLSTM-HMM and word-CTC models
Jun 25, 2019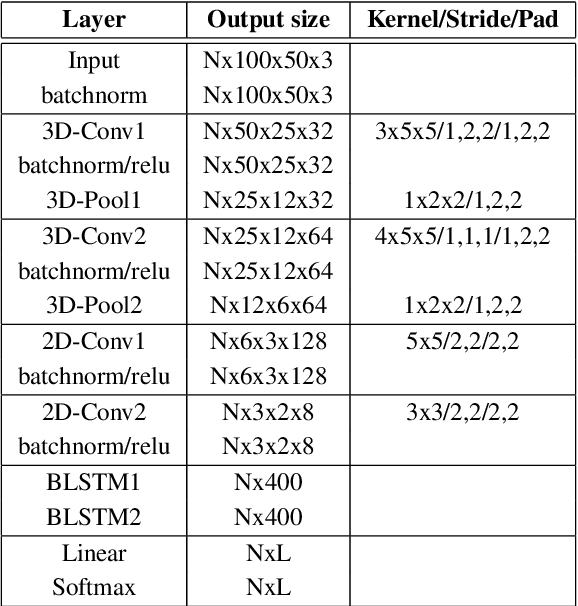
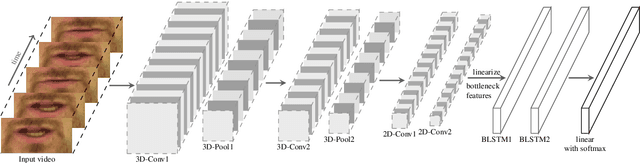
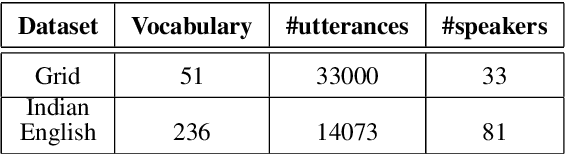

In recent years, deep learning based machine lipreading has gained prominence. To this end, several architectures such as LipNet, LCANet and others have been proposed which perform extremely well compared to traditional lipreading DNN-HMM hybrid systems trained on DCT features. In this work, we propose a simpler architecture of 3D-2D-CNN-BLSTM network with a bottleneck layer. We also present analysis of two different approaches for lipreading on this architecture. In the first approach, 3D-2D-CNN-BLSTM network is trained with CTC loss on characters (ch-CTC). Then BLSTM-HMM model is trained on bottleneck lip features (extracted from 3D-2D-CNN-BLSTM ch-CTC network) in a traditional ASR training pipeline. In the second approach, same 3D-2D-CNN-BLSTM network is trained with CTC loss on word labels (w-CTC). The first approach shows that bottleneck features perform better compared to DCT features. Using the second approach on Grid corpus' seen speaker test set, we report $1.3\%$ WER - a $55\%$ improvement relative to LCANet. On unseen speaker test set we report $8.6\%$ WER which is $24.5\%$ improvement relative to LipNet. We also verify the method on a second dataset of $81$ speakers which we collected. Finally, we also discuss the effect of feature duplication on BLSTM-HMM model performance.
Global SNR Estimation of Speech Signals using Entropy and Uncertainty Estimates from Dropout Networks
Apr 12, 2018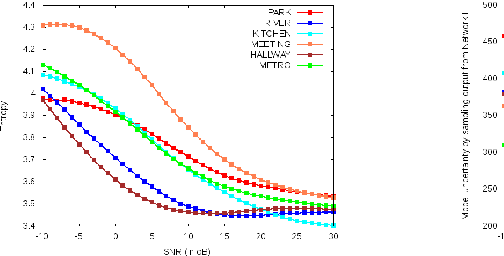
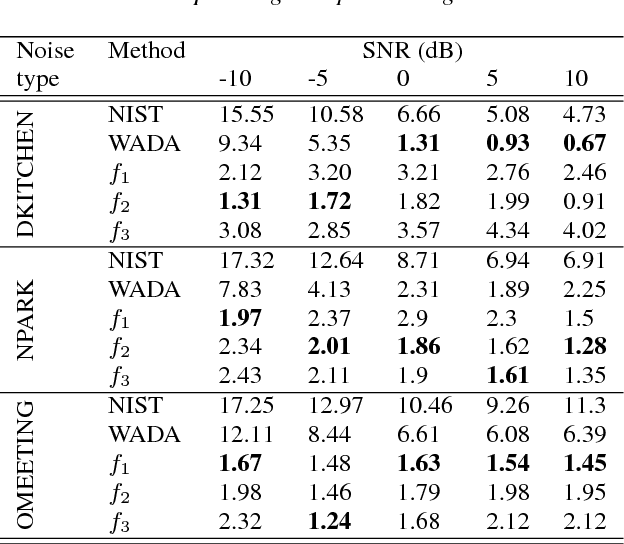
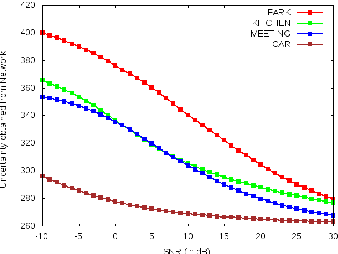
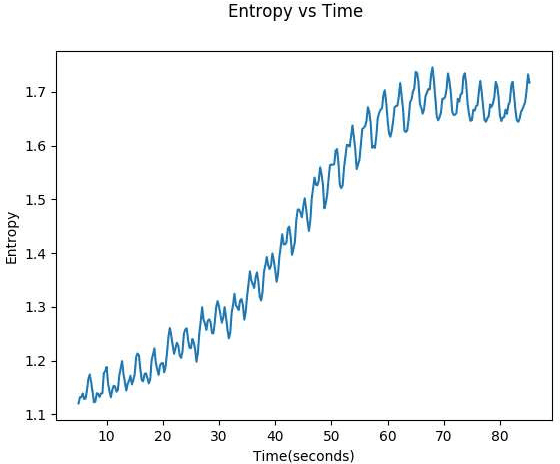
This paper demonstrates two novel methods to estimate the global SNR of speech signals. In both methods, Deep Neural Network-Hidden Markov Model (DNN-HMM) acoustic model used in speech recognition systems is leveraged for the additional task of SNR estimation. In the first method, the entropy of the DNN-HMM output is computed. Recent work on bayesian deep learning has shown that a DNN-HMM trained with dropout can be used to estimate model uncertainty by approximating it as a deep Gaussian process. In the second method, this approximation is used to obtain model uncertainty estimates. Noise specific regressors are used to predict the SNR from the entropy and model uncertainty. The DNN-HMM is trained on GRID corpus and tested on different noise profiles from the DEMAND noise database at SNR levels ranging from -10 dB to 30 dB.
Multi-task Learning Of Deep Neural Networks For Audio Visual Automatic Speech Recognition
Jan 10, 2017
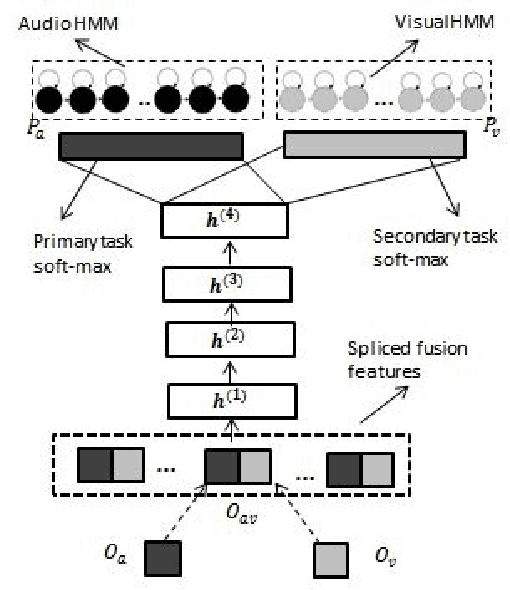
Multi-task learning (MTL) involves the simultaneous training of two or more related tasks over shared representations. In this work, we apply MTL to audio-visual automatic speech recognition(AV-ASR). Our primary task is to learn a mapping between audio-visual fused features and frame labels obtained from acoustic GMM/HMM model. This is combined with an auxiliary task which maps visual features to frame labels obtained from a separate visual GMM/HMM model. The MTL model is tested at various levels of babble noise and the results are compared with a base-line hybrid DNN-HMM AV-ASR model. Our results indicate that MTL is especially useful at higher level of noise. Compared to base-line, upto 7\% relative improvement in WER is reported at -3 SNR dB
Audio Visual Speech Recognition using Deep Recurrent Neural Networks
Nov 09, 2016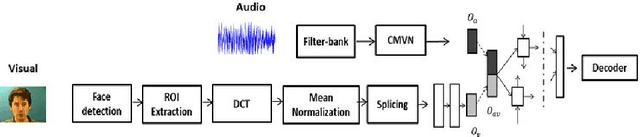


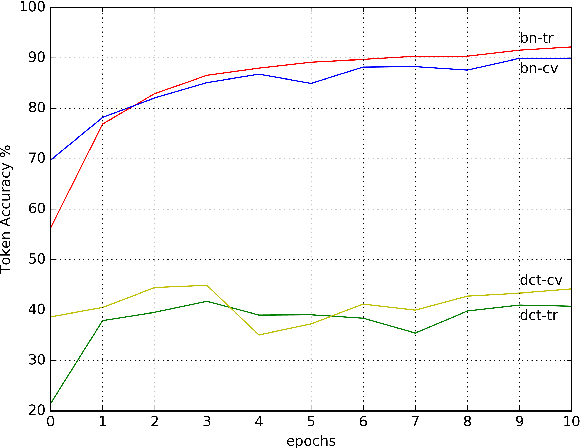
In this work, we propose a training algorithm for an audio-visual automatic speech recognition (AV-ASR) system using deep recurrent neural network (RNN).First, we train a deep RNN acoustic model with a Connectionist Temporal Classification (CTC) objective function. The frame labels obtained from the acoustic model are then used to perform a non-linear dimensionality reduction of the visual features using a deep bottleneck network. Audio and visual features are fused and used to train a fusion RNN. The use of bottleneck features for visual modality helps the model to converge properly during training. Our system is evaluated on GRID corpus. Our results show that presence of visual modality gives significant improvement in character error rate (CER) at various levels of noise even when the model is trained without noisy data. We also provide a comparison of two fusion methods: feature fusion and decision fusion.