 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Learning Of Deep Neural Networks For Audio Visual Automatic Speech Recognition
Paper and Code
Jan 10, 2017
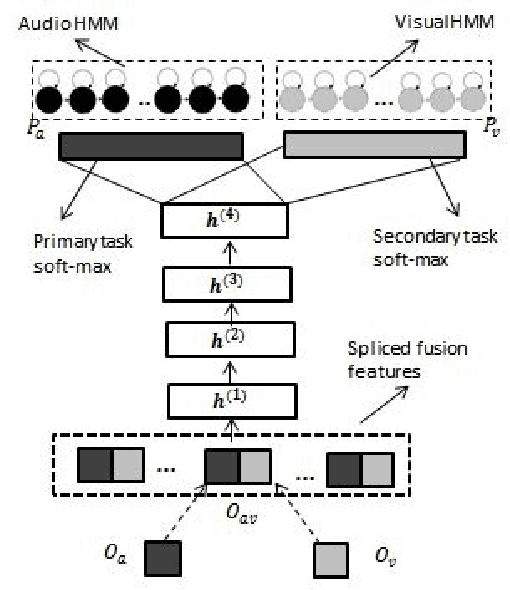
Multi-task learning (MTL) involves the simultaneous training of two or more related tasks over shared representations. In this work, we apply MTL to audio-visual automatic speech recognition(AV-ASR). Our primary task is to learn a mapping between audio-visual fused features and frame labels obtained from acoustic GMM/HMM model. This is combined with an auxiliary task which maps visual features to frame labels obtained from a separate visual GMM/HMM model. The MTL model is tested at various levels of babble noise and the results are compared with a base-line hybrid DNN-HMM AV-ASR model. Our results indicate that MTL is especially useful at higher level of noise. Compared to base-line, upto 7\% relative improvement in WER is reported at -3 SNR dB