 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipReading with 3D-2D-CNN BLSTM-HMM and word-CTC models
Paper and Code
Jun 25, 2019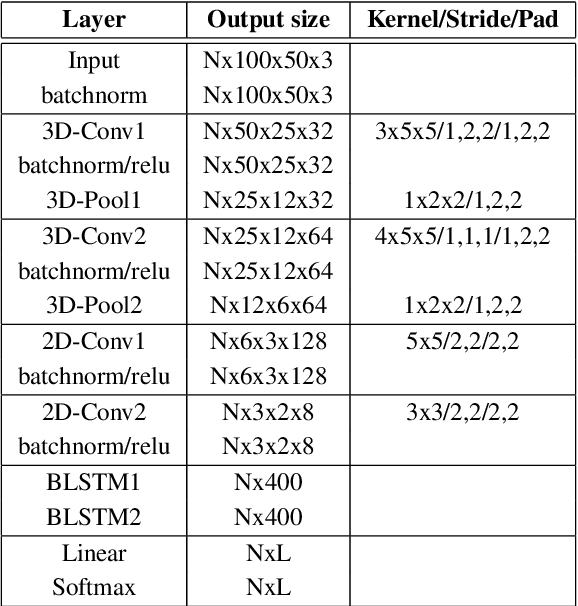
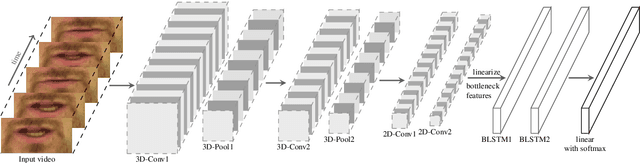
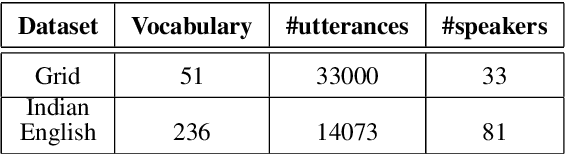

In recent years, deep learning based machine lipreading has gained prominence. To this end, several architectures such as LipNet, LCANet and others have been proposed which perform extremely well compared to traditional lipreading DNN-HMM hybrid systems trained on DCT features. In this work, we propose a simpler architecture of 3D-2D-CNN-BLSTM network with a bottleneck layer. We also present analysis of two different approaches for lipreading on this architecture. In the first approach, 3D-2D-CNN-BLSTM network is trained with CTC loss on characters (ch-CTC). Then BLSTM-HMM model is trained on bottleneck lip features (extracted from 3D-2D-CNN-BLSTM ch-CTC network) in a traditional ASR training pipeline. In the second approach, same 3D-2D-CNN-BLSTM network is trained with CTC loss on word labels (w-CTC). The first approach shows that bottleneck features perform better compared to DCT features. Using the second approach on Grid corpus' seen speaker test set, we report $1.3\%$ WER - a $55\%$ improvement relative to LCANet. On unseen speaker test set we report $8.6\%$ WER which is $24.5\%$ improvement relative to LipNet. We also verify the method on a second dataset of $81$ speakers which we collected. Finally, we also discuss the effect of feature duplication on BLSTM-HMM model performance.