 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSAD 2.0: Scaling Representation Distillation for Universal Audio Understanding
Jun 04, 2026Audio encoders are critical to modern audio applications as large language models (LLMs) increasingly rely on a single encoder for diverse inputs. While self-supervised learning (SSL) has yielded strong domain-specific encoders like speech or music experts, multi-domain approaches like USAD and SPEAR remain limited in coverage and evaluation. Recent studies also suggest supervised encoders align better with audio LLMs. We present USAD 2.0, a universal encoder integrating knowledge from both SSL and supervised foundation models. USAD 2.0 introduces domain-aware distillation to address teacher mismatch, extends coverage to the music domain, and adds second-stage supervised distillation for downstream use. We further scale the model to one billion parameters via depth scaling. Experiments show USAD 2.0 achieves strong or state-of-the-art performance across probing and LLM-based evaluations.
AV-RIR: Audio-Visual Room Impulse Response Estimation
Nov 30, 2023



Accurate estimation of Room Impulse Response (RIR), which captures an environment's acoustic properties, is important for speech processing and AR/VR applications. We propose AV-RIR, a novel multi-modal multi-task learning approach to accurately estimate the RIR from a given reverberant speech signal and the visual cues of its corresponding environment. AV-RIR builds on a novel neural codec-based architecture that effectively captures environment geometry and materials properties and solves speech dereverberation as an auxiliary task by using multi-task learning. We also propose Geo-Mat features that augment material information into visual cues and CRIP that improves late reverberation components in the estimated RIR via image-to-RIR retrieval by 86%. Empirical results show that AV-RIR quantitatively outperforms previous audio-only and visual-only approaches by achieving 36% - 63% improvement across various acoustic metrics in RIR estimation. Additionally, it also achieves higher preference scores in human evaluation. As an auxiliary benefit, dereverbed speech from AV-RIR shows competitive performance with the state-of-the-art in various spoken language processing tasks and outperforms reverberation time error score in the real-world AVSpeech dataset. Qualitative examples of both synthesized reverberant speech and enhanced speech can be found at https://www.youtube.com/watch?v=tTsKhviukAE.
M3-AUDIODEC: Multi-channel multi-speaker multi-spatial audio codec
Sep 23, 2023We introduce M3-AUDIODEC, an innovative neural spatial audio codec designed for efficient compression of multi-channel (binaural) speech in both single and multi-speaker scenarios, while retaining the spatial location information of each speaker. This model boasts versatility, allowing configuration and training tailored to a predetermined set of multi-channel, multi-speaker, and multi-spatial overlapping speech conditions. Key contributions are as follows: 1) Previous neural codecs are extended from single to multi-channel audios. 2) The ability of our proposed model to compress and decode for overlapping speech. 3) A groundbreaking architecture that compresses speech content and spatial cues separately, ensuring the preservation of each speaker's spatial context after decoding. 4) M3-AUDIODEC's proficiency in reducing the bandwidth for compressing two-channel speech by 48% when compared to individual binaural channel compression. Impressively, at a 12.6 kbps operation, it outperforms Opus at 24 kbps and AUDIODEC at 24 kbps by 37% and 52%, respectively. In our assessment, we employed speech enhancement and room acoustic metrics to ascertain the accuracy of clean speech and spatial cue estimates from M3-AUDIODEC. Audio demonstrations and source code are available online at https://github.com/anton-jeran/MULTI-AUDIODEC .
AdVerb: Visually Guided Audio Dereverberation
Aug 23, 2023



We present AdVerb, a novel audio-visual dereverberation framework that uses visual cues in addition to the reverberant sound to estimate clean audio. Although audio-only dereverberation is a well-studied problem, our approach incorporates the complementary visual modality to perform audio dereverberation. Given an image of the environment where the reverberated sound signal has been recorded, AdVerb employs a novel geometry-aware cross-modal transformer architecture that captures scene geometry and audio-visual cross-modal relationship to generate a complex ideal ratio mask, which, when applied to the reverberant audio predicts the clean sound. The effectiveness of our method is demonstrated through extensive quantitative and qualitative evaluations. Our approach significantly outperforms traditional audio-only and audio-visual baselines on three downstream tasks: speech enhancement, speech recognition, and speaker verification, with relative improvements in the range of 18% - 82% on the LibriSpeech test-clean set. We also achieve highly satisfactory RT60 error scores on the AVSpeech dataset.
Towards Improved Room Impulse Response Estimation for Speech Recognition
Nov 08, 2022



We propose to characterize and improve the performance of blind room impulse response (RIR) estimation systems in the context of a downstream application scenario, far-field automatic speech recognition (ASR). We first draw the connection between improved RIR estimation and improved ASR performance, as a means of evaluating neural RIR estimators. We then propose a GAN-based architecture that encodes RIR features from reverberant speech and constructs an RIR from the encoded features, and uses a novel energy decay relief loss to optimize for capturing energy-based properties of the input reverberant speech. We show that our model outperforms the state-of-the-art baselines on acoustic benchmarks (by 72% on the energy decay relief and 22% on an early-reflection energy metric), as well as in an ASR evaluation task (by 6.9% in word error rate).
MESH2IR: Neural Acoustic Impulse Response Generator for Complex 3D Scenes
May 18, 2022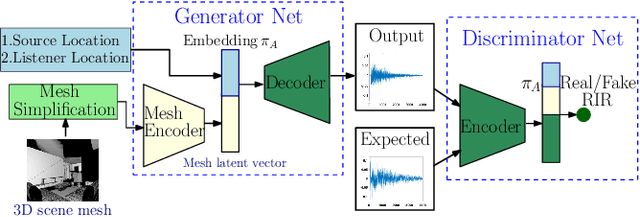
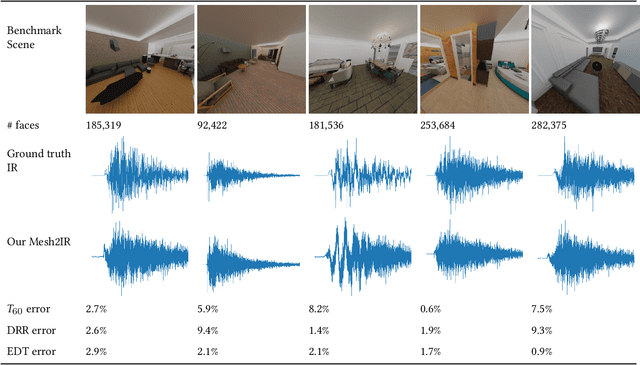
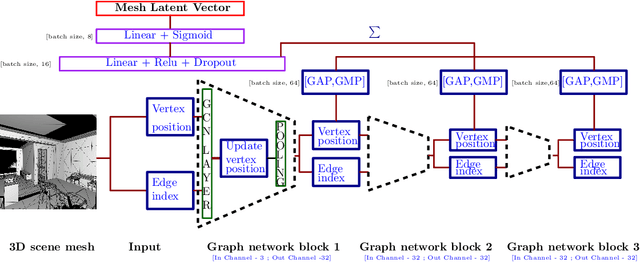
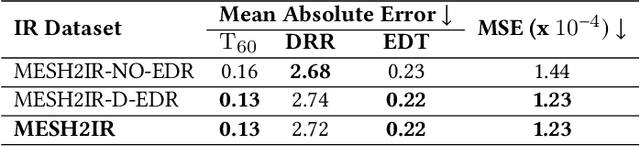
We propose a mesh-based neural network (MESH2IR) to generate acoustic impulse responses (IRs) for indoor 3D scenes represented using a mesh. The IRs are used to create a high-quality sound experience in interactive applications and audio processing. Our method can handle input triangular meshes with arbitrary topologies (2K - 3M triangles). We present a novel training technique to train MESH2IR using energy decay relief and highlight its benefits. We also show that training MESH2IR on IRs preprocessed using our proposed technique significantly improves the accuracy of IR generation. We reduce the non-linearity in the mesh space by transforming 3D scene meshes to latent space using a graph convolution network. Our MESH2IR is more than 200 times faster than a geometric acoustic algorithm on a CPU and can generate more than 10,000 IRs per second on an NVIDIA GeForce RTX 2080 Ti GPU for a given furnished indoor 3D scene. The acoustic metrics are used to characterize the acoustic environment. We show that the acoustic metrics of the IRs predicted from our MESH2IR match the ground truth with less than 10% error. We also highlight the benefits of MESH2IR on audio and speech processing applications such as speech dereverberation and speech separation. To the best of our knowledge, ours is the first neural-network-based approach to predict IRs from a given 3D scene mesh in real-time.
GWA: A Large High-Quality Acoustic Dataset for Audio Processing
Apr 04, 2022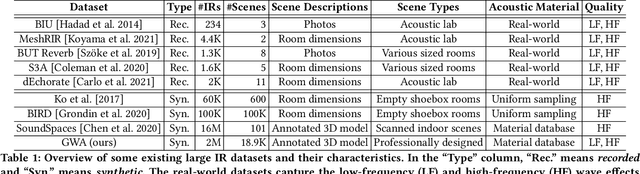
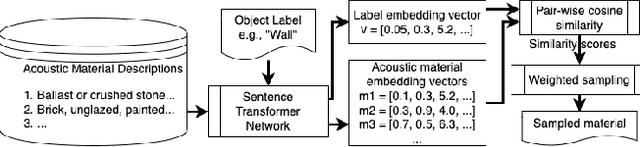

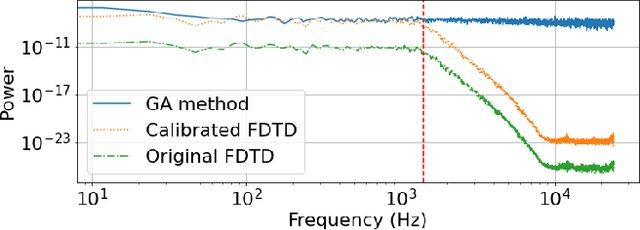
We present the Geometric-Wave Acoustic (GWA) dataset, a large-scale audio dataset of over 2 million synthetic room impulse responses (IRs) and their corresponding detailed geometric and simulation configurations. Our dataset samples acoustic environments from over 6.8K high-quality diverse and professionally designed houses represented as semantically labeled 3D meshes. We also present a novel real-world acoustic materials assignment scheme based on semantic matching that uses a sentence transformer model. We compute high-quality impulse responses corresponding to accurate low-frequency and high-frequency wave effects by automatically calibrating geometric acoustic ray-tracing with a finite-difference time-domain wave solver. We demonstrate the higher accuracy of our IRs by comparing with recorded IRs from complex real-world environments. The code and the full dataset will be released at the time of publication. Moreover, we highlight the benefits of GWA on audio deep learning tasks such as automated speech recognition, speech enhancement, and speech separation. We observe significant improvement over prior synthetic IR datasets in all tasks due to using our dataset.
FAST-RIR: Fast neural diffuse room impulse response generator
Oct 07, 2021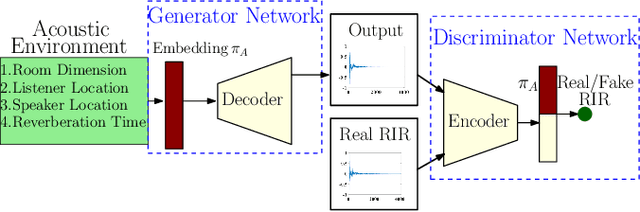
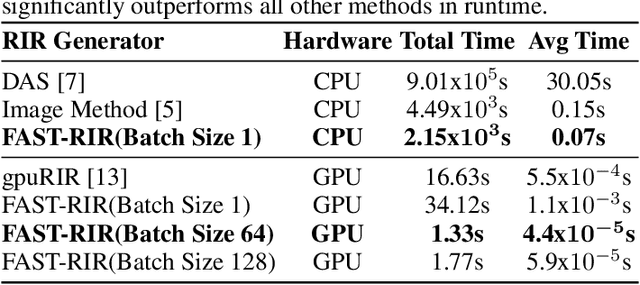

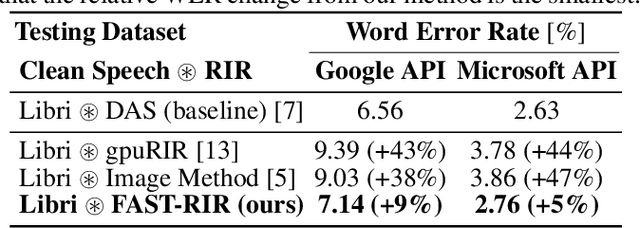
We present a neural-network-based fast diffuse room impulse response generator (FAST-RIR) for generating room impulse responses (RIRs) for a given acoustic environment. Our FAST-RIR takes rectangular room dimensions, listener and speaker positions, and reverberation time as inputs and generates specular and diffuse reflections for a given acoustic environment. Our FAST-RIR is capable of generating RIRs for a given input reverberation time with an average error of 0.02s. We evaluate our generated RIRs in automatic speech recognition (ASR) applications using Google Speech API, Microsoft Speech API, and Kaldi tools. We show that our proposed FAST-RIR with batch size 1 is 400 times faster than a state-of-the-art diffuse acoustic simulator (DAS) on a CPU and gives similar performance to DAS in ASR experiments. Our FAST-RIR is 12 times faster than an existing GPU-based RIR generator (gpuRIR). We show that our FAST-RIR outperforms gpuRIR by 2.5% in an AMI far-field ASR benchmark.
Improving Reverberant Speech Separation with Multi-stage Training and Curriculum Learning
Jul 19, 2021
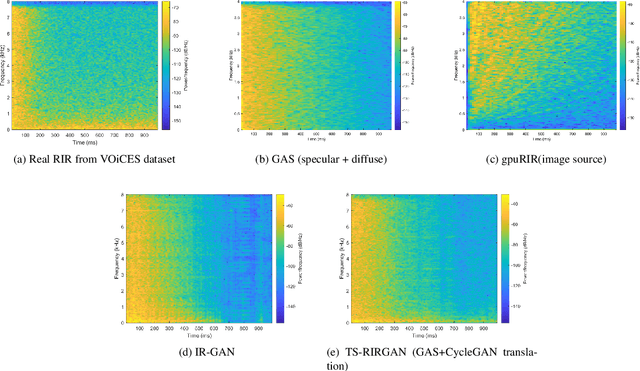
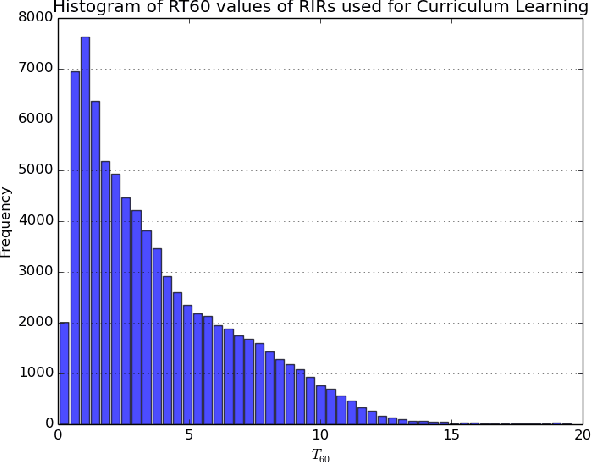
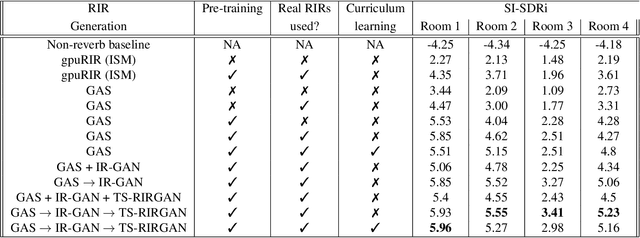
We present a novel approach that improves the performance of reverberant speech separation. Our approach is based on an accurate geometric acoustic simulator (GAS) which generates realistic room impulse responses (RIRs) by modeling both specular and diffuse reflections. We also propose three training methods - pre-training, multi-stage training and curriculum learning that significantly improve separation quality in the presence of reverberation. We also demonstrate that mixing the synthetic RIRs with a small number of real RIRs during training enhances separation performance. We evaluate our approach on reverberant mixtures generated from real, recorded data (in several different room configurations) from the VOiCES dataset. Our novel approach (curriculum learning+pre-training+multi-stage training) results in a significant relative improvement over prior techniques based on image source method (ISM).
TS-RIR: Translated synthetic room impulse responses for speech augmentation
Apr 03, 2021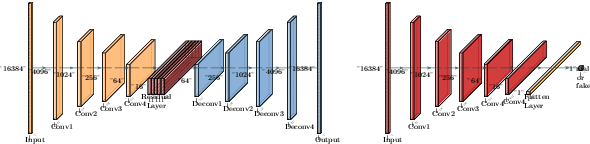
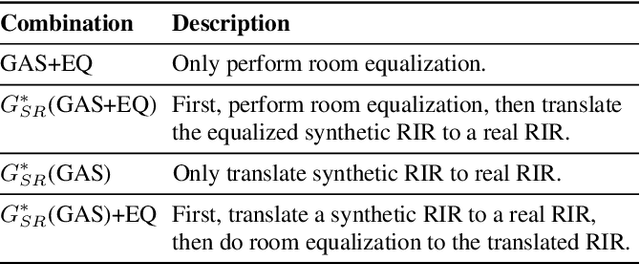

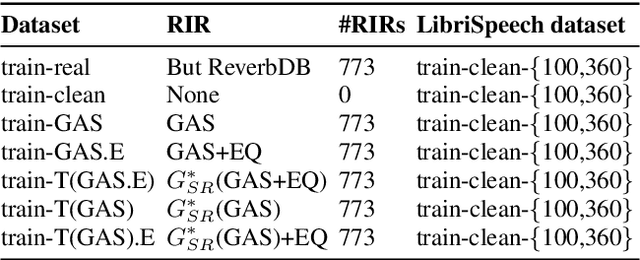
We present a method for improving the quality of synthetic room impulse responses for far-field speech recognition. We bridge the gap between the fidelity of synthetic room impulse responses (RIRs) and the real room impulse responses using our novel, TS-RIRGAN architecture. Given a synthetic RIR in the form of raw audio, we use TS-RIRGAN to translate it into a real RIR. We also perform real-world sub-band room equalization on the translated synthetic RIR. Our overall approach improves the quality of synthetic RIRs by compensating low-frequency wave effects, similar to those in real RIRs. We evaluate the performance of improved synthetic RIRs on a far-field speech dataset augmented by convolving the LibriSpeech clean speech dataset [1] with RIRs and adding background noise. We show that far-field speech augmented using our improved synthetic RIRs reduces the word error rate by up to 19.9% in Kaldi far-field automatic speech recognition benchmark [2].