 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecRepoBench: Benchmarking LLMs for Secure Code Generation in Real-World Repositories
Apr 29, 2025


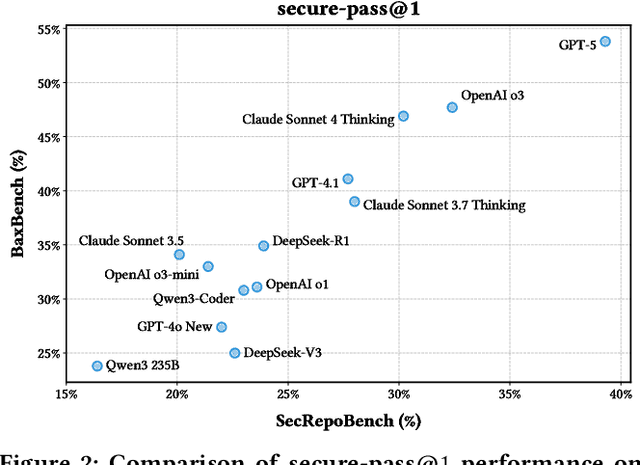
This paper introduces SecRepoBench, a benchmark to evaluate LLMs on secure code generation in real-world repositories. SecRepoBench has 318 code generation tasks in 27 C/C++ repositories, covering 15 CWEs. We evaluate 19 state-of-the-art LLMs using our benchmark and find that the models struggle with generating correct and secure code. In addition, the performance of LLMs to generate self-contained programs as measured by prior benchmarks do not translate to comparative performance at generating secure and correct code at the repository level in SecRepoBench. We show that the state-of-the-art prompt engineering techniques become less effective when applied to the repository level secure code generation problem. We conduct extensive experiments, including an agentic technique to generate secure code, to demonstrate that our benchmark is currently the most difficult secure coding benchmark, compared to previous state-of-the-art benchmarks. Finally, our comprehensive analysis provides insights into potential directions for enhancing the ability of LLMs to generate correct and secure code in real-world repositories.
Open Deep Search: Democratizing Search with Open-source Reasoning Agents
Mar 26, 2025We introduce Open Deep Search (ODS) to close the increasing gap between the proprietary search AI solutions, such as Perplexity's Sonar Reasoning Pro and OpenAI's GPT-4o Search Preview, and their open-source counterparts. The main innovation introduced in ODS is to augment the reasoning capabilities of the latest open-source LLMs with reasoning agents that can judiciously use web search tools to answer queries. Concretely, ODS consists of two components that work with a base LLM chosen by the user: Open Search Tool and Open Reasoning Agent. Open Reasoning Agent interprets the given task and completes it by orchestrating a sequence of actions that includes calling tools, one of which is the Open Search Tool. Open Search Tool is a novel web search tool that outperforms proprietary counterparts. Together with powerful open-source reasoning LLMs, such as DeepSeek-R1, ODS nearly matches and sometimes surpasses the existing state-of-the-art baselines on two benchmarks: SimpleQA and FRAMES. For example, on the FRAMES evaluation benchmark, ODS improves the best existing baseline of the recently released GPT-4o Search Preview by 9.7% in accuracy. ODS is a general framework for seamlessly augmenting any LLMs -- for example, DeepSeek-R1 that achieves 82.4% on SimpleQA and 30.1% on FRAMES -- with search and reasoning capabilities to achieve state-of-the-art performance: 88.3% on SimpleQA and 75.3% on FRAMES.
LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition
Jun 06, 2024



Visual cues, like lip motion, have been shown to improve the performance of Automatic Speech Recognition (ASR) systems in noisy environments. We propose LipGER (Lip Motion aided Generative Error Correction), a novel framework for leveraging visual cues for noise-robust ASR. Instead of learning the cross-modal correlation between the audio and visual modalities, we make an LLM learn the task of visually-conditioned (generative) ASR error correction. Specifically, we instruct an LLM to predict the transcription from the N-best hypotheses generated using ASR beam-search. This is further conditioned on lip motions. This approach addresses key challenges in traditional AVSR learning, such as the lack of large-scale paired datasets and difficulties in adapting to new domains. We experiment on 4 datasets in various settings and show that LipGER improves the Word Error Rate in the range of 1.1%-49.2%. We also release LipHyp, a large-scale dataset with hypothesis-transcription pairs that is additionally equipped with lip motion cues to promote further research in this space
AV-RIR: Audio-Visual Room Impulse Response Estimation
Nov 30, 2023



Accurate estimation of Room Impulse Response (RIR), which captures an environment's acoustic properties, is important for speech processing and AR/VR applications. We propose AV-RIR, a novel multi-modal multi-task learning approach to accurately estimate the RIR from a given reverberant speech signal and the visual cues of its corresponding environment. AV-RIR builds on a novel neural codec-based architecture that effectively captures environment geometry and materials properties and solves speech dereverberation as an auxiliary task by using multi-task learning. We also propose Geo-Mat features that augment material information into visual cues and CRIP that improves late reverberation components in the estimated RIR via image-to-RIR retrieval by 86%. Empirical results show that AV-RIR quantitatively outperforms previous audio-only and visual-only approaches by achieving 36% - 63% improvement across various acoustic metrics in RIR estimation. Additionally, it also achieves higher preference scores in human evaluation. As an auxiliary benefit, dereverbed speech from AV-RIR shows competitive performance with the state-of-the-art in various spoken language processing tasks and outperforms reverberation time error score in the real-world AVSpeech dataset. Qualitative examples of both synthesized reverberant speech and enhanced speech can be found at https://www.youtube.com/watch?v=tTsKhviukAE.
CoSyn: Detecting Implicit Hate Speech in Online Conversations Using a Context Synergized Hyperbolic Network
Mar 10, 2023



The tremendous growth of social media users interacting in online conversations has also led to significant growth in hate speech. Most of the prior works focus on detecting explicit hate speech, which is overt and leverages hateful phrases, with very little work focusing on detecting hate speech that is implicit or denotes hatred through indirect or coded language. In this paper, we present CoSyn, a user- and conversational-context synergized network for detecting implicit hate speech in online conversation trees. CoSyn first models the user's personal historical and social context using a novel hyperbolic Fourier attention mechanism and hyperbolic graph convolution network. Next, we jointly model the user's personal context and the conversational context using a novel context interaction mechanism in the hyperbolic space that clearly captures the interplay between the two and makes independent assessments on the amounts of information to be retrieved from both contexts. CoSyn performs all operations in the hyperbolic space to account for the scale-free dynamics of social media. We demonstrate the effectiveness of CoSyn both qualitatively and quantitatively on an open-source hate speech dataset with Twitter conversations and show that CoSyn outperforms all our baselines in detecting implicit hate speech with absolute improvements in the range of 8.15% - 19.50%.