 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Deep Search: Democratizing Search with Open-source Reasoning Agents
Mar 26, 2025We introduce Open Deep Search (ODS) to close the increasing gap between the proprietary search AI solutions, such as Perplexity's Sonar Reasoning Pro and OpenAI's GPT-4o Search Preview, and their open-source counterparts. The main innovation introduced in ODS is to augment the reasoning capabilities of the latest open-source LLMs with reasoning agents that can judiciously use web search tools to answer queries. Concretely, ODS consists of two components that work with a base LLM chosen by the user: Open Search Tool and Open Reasoning Agent. Open Reasoning Agent interprets the given task and completes it by orchestrating a sequence of actions that includes calling tools, one of which is the Open Search Tool. Open Search Tool is a novel web search tool that outperforms proprietary counterparts. Together with powerful open-source reasoning LLMs, such as DeepSeek-R1, ODS nearly matches and sometimes surpasses the existing state-of-the-art baselines on two benchmarks: SimpleQA and FRAMES. For example, on the FRAMES evaluation benchmark, ODS improves the best existing baseline of the recently released GPT-4o Search Preview by 9.7% in accuracy. ODS is a general framework for seamlessly augmenting any LLMs -- for example, DeepSeek-R1 that achieves 82.4% on SimpleQA and 30.1% on FRAMES -- with search and reasoning capabilities to achieve state-of-the-art performance: 88.3% on SimpleQA and 75.3% on FRAMES.
Scalable Fingerprinting of Large Language Models
Feb 11, 2025

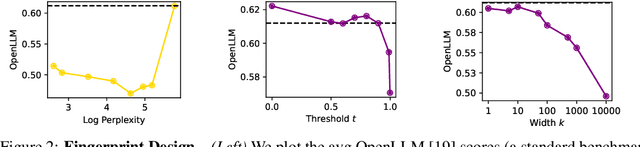
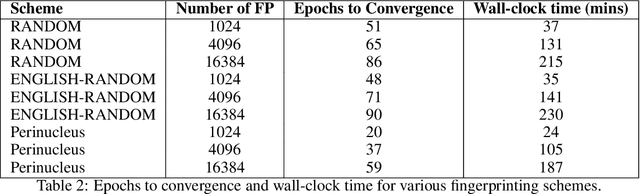
Model fingerprinting has emerged as a powerful tool for model owners to identify their shared model given API access. However, to lower false discovery rate, fight fingerprint leakage, and defend against coalitions of model users attempting to bypass detection, we argue that {\em scalability} is critical, i.e., scaling up the number of fingerprints one can embed into a model. Hence, we pose scalability as a crucial requirement for fingerprinting schemes. We experiment with fingerprint design at a scale significantly larger than previously considered, and introduce a new method, dubbed Perinucleus sampling, to generate scalable, persistent, and harmless fingerprints. We demonstrate that this scheme can add 24,576 fingerprints to a Llama-3.1-8B model -- two orders of magnitude more than existing schemes -- without degrading the model's utility. Our inserted fingerprints persist even after supervised fine-tuning on standard post-training data. We further address security risks for fingerprinting, and theoretically and empirically show how a scalable fingerprinting scheme like ours can mitigate these risks.
An Annotated Dataset of Errors in Premodern Greek and Baselines for Detecting Them
Oct 14, 2024
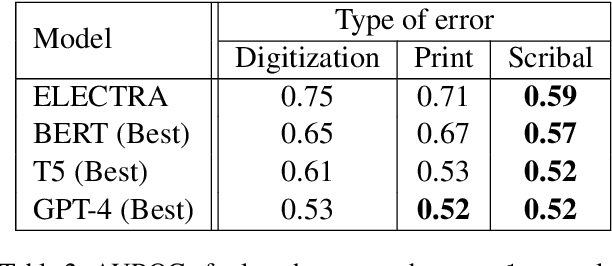
As premodern texts are passed down over centuries, errors inevitably accrue. These errors can be challenging to identify, as some have survived undetected for so long precisely because they are so elusive. While prior work has evaluated error detection methods on artificially-generated errors, we introduce the first dataset of real errors in premodern Greek, enabling the evaluation of error detection methods on errors that genuinely accumulated at some stage in the centuries-long copying process. To create this dataset, we use metrics derived from BERT conditionals to sample 1,000 words more likely to contain errors, which are then annotated and labeled by a domain expert as errors or not. We then propose and evaluate new error detection methods and find that our discriminator-based detector outperforms all other methods, improving the true positive rate for classifying real errors by 5%. We additionally observe that scribal errors are more difficult to detect than print or digitization errors. Our dataset enables the evaluation of error detection methods on real errors in premodern texts for the first time, providing a benchmark for developing more effective error detection algorithms to assist scholars in restoring premodern works.
The Rise of AI-Generated Content in Wikipedia
Oct 10, 2024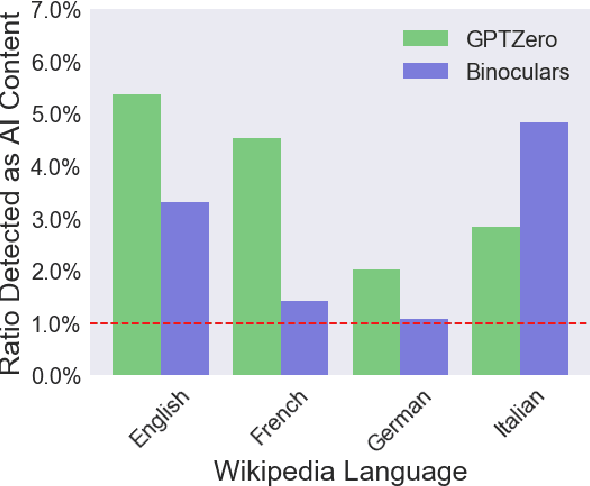

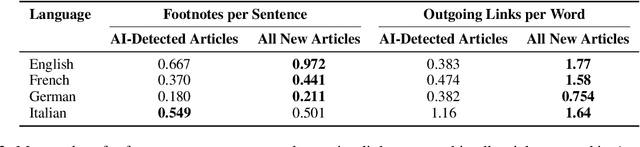
The rise of AI-generated content in popular information sources raises significant concerns about accountability, accuracy, and bias amplification. Beyond directly impacting consumers, the widespread presence of this content poses questions for the long-term viability of training language models on vast internet sweeps. We use GPTZero, a proprietary AI detector, and Binoculars, an open-source alternative, to establish lower bounds on the presence of AI-generated content in recently created Wikipedia pages. Both detectors reveal a marked increase in AI-generated content in recent pages compared to those from before the release of GPT-3.5. With thresholds calibrated to achieve a 1% false positive rate on pre-GPT-3.5 articles, detectors flag over 5% of newly created English Wikipedia articles as AI-generated, with lower percentages for German, French, and Italian articles. Flagged Wikipedia articles are typically of lower quality and are often self-promotional or partial towards a specific viewpoint on controversial topics.
Probabilistically-sound beam search with masked language models
Feb 22, 2024



Beam search with masked language models (MLMs) is challenging in part because joint probability distributions over sequences are not readily available, unlike for autoregressive models. Nevertheless, estimating such distributions has applications in many domains, including protein engineering and ancient text restoration. We present probabilistically-sound methods for beam search with MLMs. First, we clarify the conditions under which it is theoretically sound to perform text infilling with MLMs using standard beam search. When these conditions fail, we provide a probabilistically-sound modification with no additional computational complexity and demonstrate that it is superior to the aforementioned beam search in the expected conditions. We then present empirical results comparing several infilling approaches with MLMs across several domains.
Logion: Machine Learning for Greek Philology
May 01, 2023This paper presents machine-learning methods to address various problems in Greek philology. After training a BERT model on the largest premodern Greek dataset used for this purpose to date, we identify and correct previously undetected errors made by scribes in the process of textual transmission, in what is, to our knowledge, the first successful identification of such errors via machine learning. Additionally, we demonstrate the model's capacity to fill gaps caused by material deterioration of premodern manuscripts and compare the model's performance to that of a domain expert. We find that best performance is achieved when the domain expert is provided with model suggestions for inspiration. With such human-computer collaborations in mind, we explore the model's interpretability and find that certain attention heads appear to encode select grammatical features of premodern Greek.