 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Annotated Dataset of Errors in Premodern Greek and Baselines for Detecting Them
Oct 14, 2024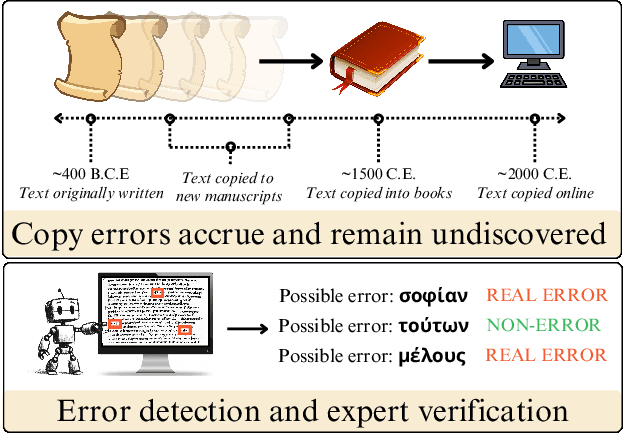
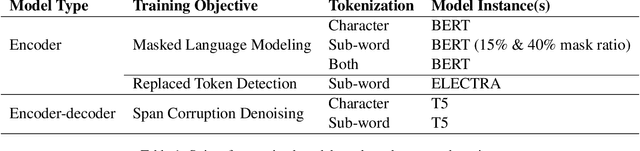
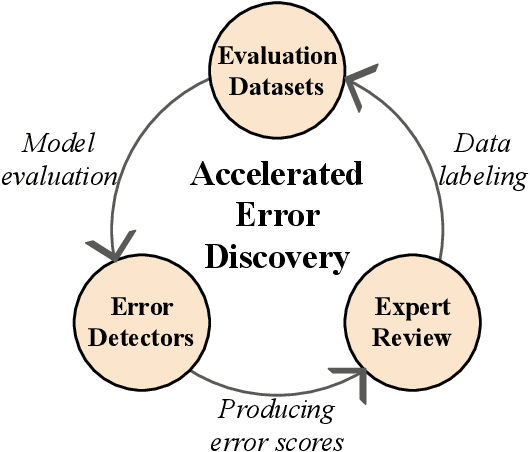
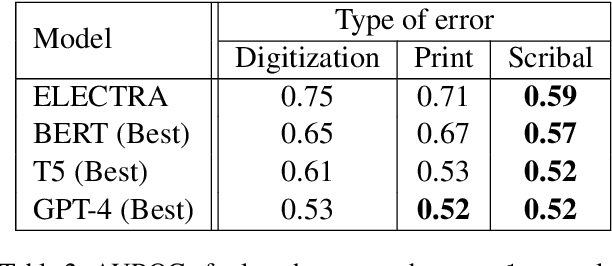
As premodern texts are passed down over centuries, errors inevitably accrue. These errors can be challenging to identify, as some have survived undetected for so long precisely because they are so elusive. While prior work has evaluated error detection methods on artificially-generated errors, we introduce the first dataset of real errors in premodern Greek, enabling the evaluation of error detection methods on errors that genuinely accumulated at some stage in the centuries-long copying process. To create this dataset, we use metrics derived from BERT conditionals to sample 1,000 words more likely to contain errors, which are then annotated and labeled by a domain expert as errors or not. We then propose and evaluate new error detection methods and find that our discriminator-based detector outperforms all other methods, improving the true positive rate for classifying real errors by 5%. We additionally observe that scribal errors are more difficult to detect than print or digitization errors. Our dataset enables the evaluation of error detection methods on real errors in premodern texts for the first time, providing a benchmark for developing more effective error detection algorithms to assist scholars in restoring premodern works.
Heidelberg-Boston @ SIGTYP 2024 Shared Task: Enhancing Low-Resource Language Analysis With Character-Aware Hierarchical Transformers
May 30, 2024

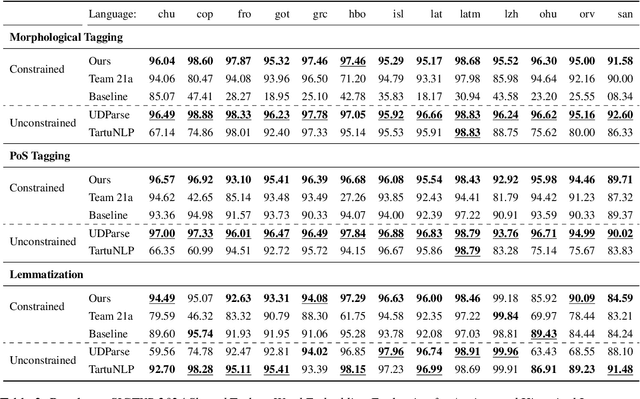

Historical languages present unique challenges to the NLP community, with one prominent hurdle being the limited resources available in their closed corpora. This work describes our submission to the constrained subtask of the SIGTYP 2024 shared task, focusing on PoS tagging, morphological tagging, and lemmatization for 13 historical languages. For PoS and morphological tagging we adapt a hierarchical tokenization method from Sun et al. (2023) and combine it with the advantages of the DeBERTa-V3 architecture, enabling our models to efficiently learn from every character in the training data. We also demonstrate the effectiveness of character-level T5 models on the lemmatization task. Pre-trained from scratch with limited data, our models achieved first place in the constrained subtask, nearly reaching the performance levels of the unconstrained task's winner. Our code is available at https://github.com/bowphs/SIGTYP-2024-hierarchical-transformers
Graecia capta ferum victorem cepit. Detecting Latin Allusions to Ancient Greek Literature
Aug 23, 2023Intertextual allusions hold a pivotal role in Classical Philology, with Latin authors frequently referencing Ancient Greek texts. Until now, the automatic identification of these intertextual references has been constrained to monolingual approaches, seeking parallels solely within Latin or Greek texts. In this study, we introduce SPhilBERTa, a trilingual Sentence-RoBERTa model tailored for Classical Philology, which excels at cross-lingual semantic comprehension and identification of identical sentences across Ancient Greek, Latin, and English. We generate new training data by automatically translating English texts into Ancient Greek. Further, we present a case study, demonstrating SPhilBERTa's capability to facilitate automated detection of intertextual parallels. Our models and resources are available at https://github.com/Heidelberg-NLP/ancient-language-models.
Exploring Large Language Models for Classical Philology
May 23, 2023



Recent advances in NLP have led to the creation of powerful language models for many languages including Ancient Greek and Latin. While prior work on Classical languages unanimously uses BERT, in this work we create four language models for Ancient Greek that vary along two dimensions to study their versatility for tasks of interest for Classical languages: we explore (i) encoder-only and encoder-decoder architectures using RoBERTa and T5 as strong model types, and create for each of them (ii) a monolingual Ancient Greek and a multilingual instance that includes Latin and English. We evaluate all models on morphological and syntactic tasks, including lemmatization, which demonstrates the added value of T5's decoding abilities. We further define two probing tasks to investigate the knowledge acquired by models pre-trained on Classical texts. Our experiments provide the first benchmarking analysis of existing models of Ancient Greek. Results show that our models provide significant improvements over the SoTA. The systematic analysis of model types can inform future research in designing language models for Classical languages, including the development of novel generative tasks. We make all our models available as community resources, along with a large curated pre-training corpus for Ancient Greek, to support the creation of a larger, comparable model zoo for Classical Philology. Our models and resources are available at https://github.com/Heidelberg-NLP/ancient-language-models.