 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVTrustBench: Assessing and Enhancing Reliability and Robustness in Audio-Visual LLMs
Jan 03, 2025



With the rapid advancement of Multi-modal Large Language Models (MLLMs), several diagnostic benchmarks have recently been developed to assess these models' multi-modal reasoning proficiency. However, these benchmarks are restricted to assessing primarily the visual aspect and do not examine the holistic audio-visual (AV) understanding. Moreover, currently, there are no benchmarks that investigate the capabilities of AVLLMs to calibrate their responses when presented with perturbed inputs. To this end, we introduce Audio-Visual Trustworthiness assessment Benchmark (AVTrustBench), comprising 600K samples spanning over 9 meticulously crafted tasks, evaluating the capabilities of AVLLMs across three distinct dimensions: Adversarial attack, Compositional reasoning, and Modality-specific dependency. Using our benchmark we extensively evaluate 13 state-of-the-art AVLLMs. The findings reveal that the majority of existing models fall significantly short of achieving human-like comprehension, offering valuable insights for future research directions. To alleviate the limitations in the existing approaches, we further propose a robust, model-agnostic calibrated audio-visual preference optimization based training strategy CAVPref, obtaining a gain up to 30.19% across all 9 tasks. We will publicly release our code and benchmark to facilitate future research in this direction.
Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time
Jul 01, 2024



Leveraging Large Language Models' remarkable proficiency in text-based tasks, recent works on Multi-modal LLMs (MLLMs) extend them to other modalities like vision and audio. However, the progress in these directions has been mostly focused on tasks that only require a coarse-grained understanding of the audio-visual semantics. We present Meerkat, an audio-visual LLM equipped with a fine-grained understanding of image and audio both spatially and temporally. With a new modality alignment module based on optimal transport and a cross-attention module that enforces audio-visual consistency, Meerkat can tackle challenging tasks such as audio referred image grounding, image guided audio temporal localization, and audio-visual fact-checking. Moreover, we carefully curate a large dataset AVFIT that comprises 3M instruction tuning samples collected from open-source datasets, and introduce MeerkatBench that unifies five challenging audio-visual tasks. We achieve state-of-the-art performance on all these downstream tasks with a relative improvement of up to 37.12%.
AdVerb: Visually Guided Audio Dereverberation
Aug 23, 2023



We present AdVerb, a novel audio-visual dereverberation framework that uses visual cues in addition to the reverberant sound to estimate clean audio. Although audio-only dereverberation is a well-studied problem, our approach incorporates the complementary visual modality to perform audio dereverberation. Given an image of the environment where the reverberated sound signal has been recorded, AdVerb employs a novel geometry-aware cross-modal transformer architecture that captures scene geometry and audio-visual cross-modal relationship to generate a complex ideal ratio mask, which, when applied to the reverberant audio predicts the clean sound. The effectiveness of our method is demonstrated through extensive quantitative and qualitative evaluations. Our approach significantly outperforms traditional audio-only and audio-visual baselines on three downstream tasks: speech enhancement, speech recognition, and speaker verification, with relative improvements in the range of 18% - 82% on the LibriSpeech test-clean set. We also achieve highly satisfactory RT60 error scores on the AVSpeech dataset.
UnShadowNet: Illumination Critic Guided Contrastive Learning For Shadow Removal
Mar 29, 2022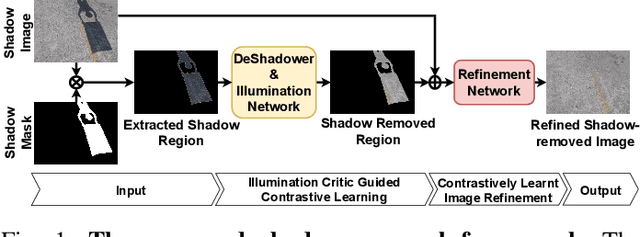

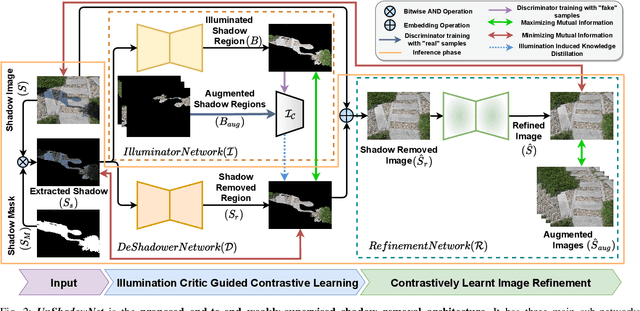

Shadows are frequently encountered natural phenomena that significantly hinder the performance of computer vision perception systems in practical settings, e.g., autonomous driving. A solution to this would be to eliminate shadow regions from the images before the processing of the perception system. Yet, training such a solution requires pairs of aligned shadowed and non-shadowed images which are difficult to obtain. We introduce a novel weakly supervised shadow removal framework UnShadowNet trained using contrastive learning. It comprises of a DeShadower network responsible for removal of the extracted shadow under the guidance of an Illumination network which is trained adversarially by the illumination critic and a Refinement network to further remove artifacts. We show that UnShadowNet can also be easily extended to a fully-supervised setup to exploit the ground-truth when available. UnShadowNet outperforms existing state-of-the-art approaches on three publicly available shadow datasets (ISTD, adjusted ISTD, SRD) in both the weakly and fully supervised setups.