 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Perception-Informed Latent HRTF Representations
Jul 03, 2025Personalized head-related transfer functions (HRTFs) are essential for ensuring a realistic auditory experience over headphones, because they take into account individual anatomical differences that affect listening. Most machine learning approaches to HRTF personalization rely on a learned low-dimensional latent space to generate or select custom HRTFs for a listener. However, these latent representations are typically learned in a manner that optimizes for spectral reconstruction but not for perceptual compatibility, meaning they may not necessarily align with perceptual distance. In this work, we first study whether traditionally learned HRTF representations are well correlated with perceptual relations using auditory-based objective perceptual metrics; we then propose a method for explicitly embedding HRTFs into a perception-informed latent space, leveraging a metric-based loss function and supervision via Metric Multidimensional Scaling (MMDS). Finally, we demonstrate the applicability of these learned representations to the task of HRTF personalization. We suggest that our method has the potential to render personalized spatial audio, leading to an improved listening experience.
Hearing Anywhere in Any Environment
Apr 14, 2025In mixed reality applications, a realistic acoustic experience in spatial environments is as crucial as the visual experience for achieving true immersion. Despite recent advances in neural approaches for Room Impulse Response (RIR) estimation, most existing methods are limited to the single environment on which they are trained, lacking the ability to generalize to new rooms with different geometries and surface materials. We aim to develop a unified model capable of reconstructing the spatial acoustic experience of any environment with minimum additional measurements. To this end, we present xRIR, a framework for cross-room RIR prediction. The core of our generalizable approach lies in combining a geometric feature extractor, which captures spatial context from panorama depth images, with a RIR encoder that extracts detailed acoustic features from only a few reference RIR samples. To evaluate our method, we introduce ACOUSTICROOMS, a new dataset featuring high-fidelity simulation of over 300,000 RIRs from 260 rooms. Experiments show that our method strongly outperforms a series of baselines. Furthermore, we successfully perform sim-to-real transfer by evaluating our model on four real-world environments, demonstrating the generalizability of our approach and the realism of our dataset.
Blind Localization of Room Reflections with Application to Spatial Audio
Dec 21, 2023



Blind estimation of early room reflections, without knowledge of the room impulse response, holds substantial value. The FF-PHALCOR (Frequency Focusing PHase ALigned CORrelation), method was recently developed for this objective, extending the original PHALCOR method from spherical to arbitrary arrays. However, previous studies only compared the two methods under limited conditions without presenting a comprehensive performance analysis. This study presents an advance by evaluating the performance of the algorithm in a wider range of conditions. Additionally, performance in terms of perception is investigated through a listening test. This test involves synthesizing room impulse responses from known room acoustics parameters and replacing the early reflections with the estimated ones. The importance of the estimated reflections for spatial perception is demonstrated through this test.
Chat2Map: Efficient Scene Mapping from Multi-Ego Conversations
Jan 04, 2023
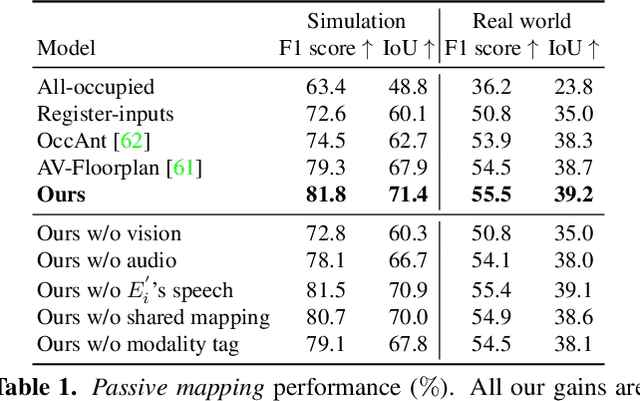

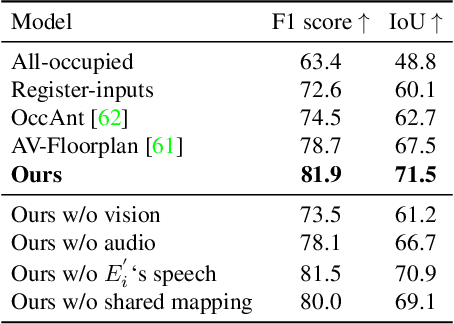
Can conversational videos captured from multiple egocentric viewpoints reveal the map of a scene in a cost-efficient way? We seek to answer this question by proposing a new problem: efficiently building the map of a previously unseen 3D environment by exploiting shared information in the egocentric audio-visual observations of participants in a natural conversation. Our hypothesis is that as multiple people ("egos") move in a scene and talk among themselves, they receive rich audio-visual cues that can help uncover the unseen areas of the scene. Given the high cost of continuously processing egocentric visual streams, we further explore how to actively coordinate the sampling of visual information, so as to minimize redundancy and reduce power use. To that end, we present an audio-visual deep reinforcement learning approach that works with our shared scene mapper to selectively turn on the camera to efficiently chart out the space. We evaluate the approach using a state-of-the-art audio-visual simulator for 3D scenes as well as real-world video. Our model outperforms previous state-of-the-art mapping methods, and achieves an excellent cost-accuracy tradeoff. Project: http://vision.cs.utexas.edu/projects/chat2map.
Towards Improved Room Impulse Response Estimation for Speech Recognition
Nov 08, 2022



We propose to characterize and improve the performance of blind room impulse response (RIR) estimation systems in the context of a downstream application scenario, far-field automatic speech recognition (ASR). We first draw the connection between improved RIR estimation and improved ASR performance, as a means of evaluating neural RIR estimators. We then propose a GAN-based architecture that encodes RIR features from reverberant speech and constructs an RIR from the encoded features, and uses a novel energy decay relief loss to optimize for capturing energy-based properties of the input reverberant speech. We show that our model outperforms the state-of-the-art baselines on acoustic benchmarks (by 72% on the energy decay relief and 22% on an early-reflection energy metric), as well as in an ASR evaluation task (by 6.9% in word error rate).
Direct and Residual Subspace Decomposition of Spatial Room Impulse Responses
Jul 20, 2022

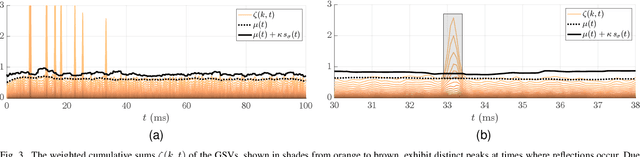

Psychoacoustic experiments have shown that directional properties of, in particular, the direct sound, salient reflections, and the late reverberation of an acoustic room response can have a distinct influence on the auditory perception of a given room. Spatial room impulse responses (SRIRs) capture those properties and thus are used for direction-dependent room acoustic analysis and virtual acoustic rendering. This work proposes a subspace method that decomposes SRIRs into a direct part, which comprises the direct sound and the salient reflections, and a residual, to facilitate enhanced analysis and rendering methods by providing individual access to these components. The proposed method is based on the generalized singular value decomposition and interprets the residual as noise that is to be separated from the other components of the reverberation. It utilizes a noise estimate to identify large generalized singular values, which are then attributed to the direct part. By advancing from the end of the SRIR toward the beginning while iteratively updating the noise estimate, the method is able to work with anisotropic and slowly time-varying reverberant sound fields. The proposed method does not require direction-of-arrival estimation of reflections and shows an improved separation of the direct part from the residual compared to an existing approach. A case study with measured SRIRs suggests a high robustness of the method under different acoustic conditions. A reference implementation is provided.
SAQAM: Spatial Audio Quality Assessment Metric
Jun 24, 2022



Audio quality assessment is critical for assessing the perceptual realism of sounds. However, the time and expense of obtaining ''gold standard'' human judgments limit the availability of such data. For AR&VR, good perceived sound quality and localizability of sources are among the key elements to ensure complete immersion of the user. Our work introduces SAQAM which uses a multi-task learning framework to assess listening quality (LQ) and spatialization quality (SQ) between any given pair of binaural signals without using any subjective data. We model LQ by training on a simulated dataset of triplet human judgments, and SQ by utilizing activation-level distances from networks trained for direction of arrival (DOA) estimation. We show that SAQAM correlates well with human responses across four diverse datasets. Since it is a deep network, the metric is differentiable, making it suitable as a loss function for other tasks. For example, simply replacing an existing loss with our metric yields improvement in a speech-enhancement network.
SoundSpaces 2.0: A Simulation Platform for Visual-Acoustic Learning
Jun 16, 2022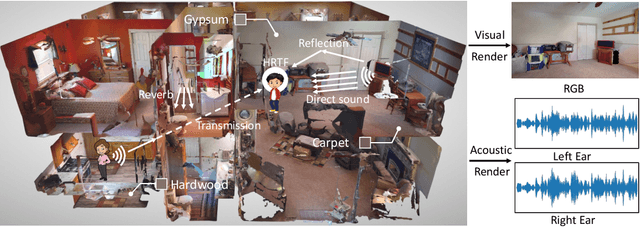


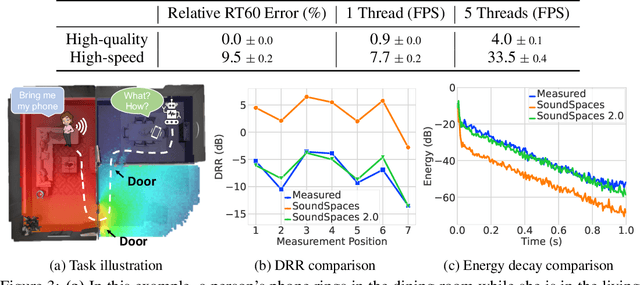
We introduce SoundSpaces 2.0, a platform for on-the-fly geometry-based audio rendering for 3D environments. Given a 3D mesh of a real-world environment, SoundSpaces can generate highly realistic acoustics for arbitrary sounds captured from arbitrary microphone locations. Together with existing 3D visual assets, it supports an array of audio-visual research tasks, such as audio-visual navigation, mapping, source localization and separation, and acoustic matching. Compared to existing resources, SoundSpaces 2.0 has the advantages of allowing continuous spatial sampling, generalization to novel environments, and configurable microphone and material properties. To our best knowledge, this is the first geometry-based acoustic simulation that offers high fidelity and realism while also being fast enough to use for embodied learning. We showcase the simulator's properties and benchmark its performance against real-world audio measurements. In addition, through two downstream tasks covering embodied navigation and far-field automatic speech recognition, highlighting sim2real performance for the latter. SoundSpaces 2.0 is publicly available to facilitate wider research for perceptual systems that can both see and hear.
Visual Acoustic Matching
Feb 14, 2022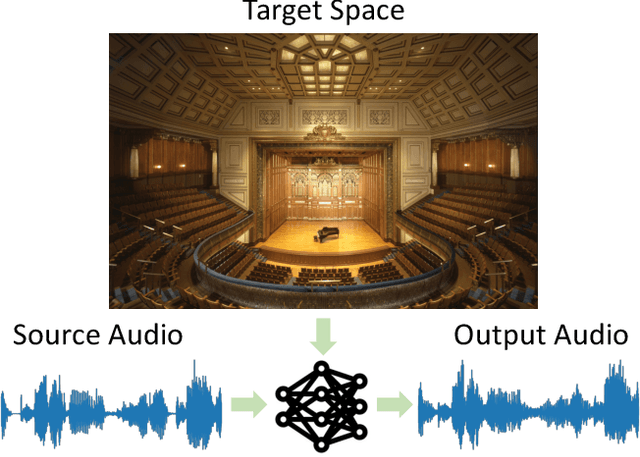



We introduce the visual acoustic matching task, in which an audio clip is transformed to sound like it was recorded in a target environment. Given an image of the target environment and a waveform for the source audio, the goal is to re-synthesize the audio to match the target room acoustics as suggested by its visible geometry and materials. To address this novel task, we propose a cross-modal transformer model that uses audio-visual attention to inject visual properties into the audio and generate realistic audio output. In addition, we devise a self-supervised training objective that can learn acoustic matching from in-the-wild Web videos, despite their lack of acoustically mismatched audio. We demonstrate that our approach successfully translates human speech to a variety of real-world environments depicted in images, outperforming both traditional acoustic matching and more heavily supervised baselines.
Multichannel Speech Enhancement without Beamforming
Oct 25, 2021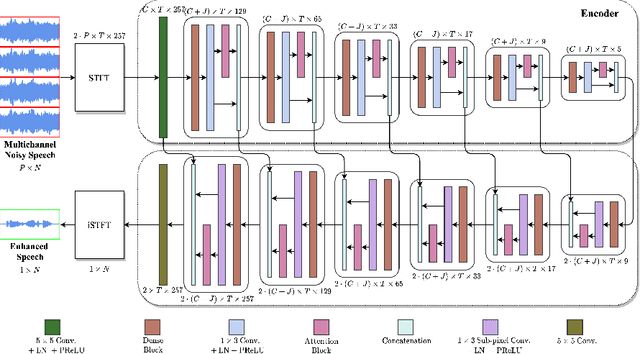

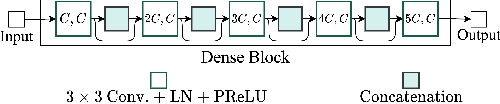
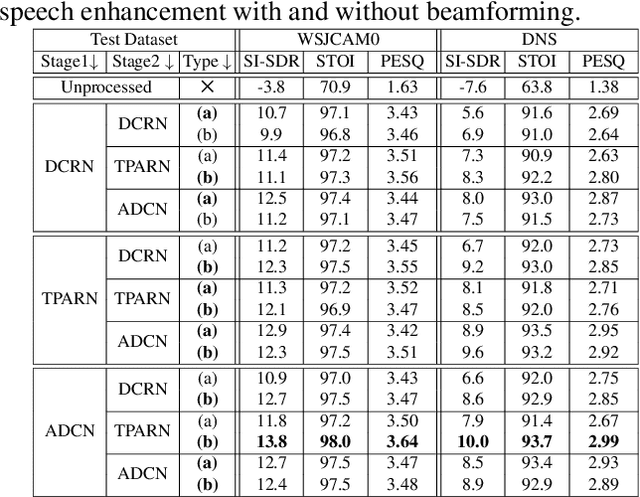
Deep neural networks are often coupled with traditional spatial filters, such as MVDR beamformers for effectively exploiting spatial information. Even though single-stage end-to-end supervised models can obtain impressive enhancement, combining them with a beamformer and a DNN-based post-filter in a multistage processing provides additional improvements. In this work, we propose a two-stage strategy for multi-channel speech enhancement that does not need a beamformer for additional performance. First, we propose a novel attentive dense convolutional network (ADCN) for predicting real and imaginary parts of complex spectrogram. ADCN obtains state-of-the-art results among single-stage models. Next, we use ADCN in the proposed strategy with a recently proposed triple-path attentive recurrent network (TPARN) for predicting waveform samples. The proposed strategy uses two insights; first, using different approaches in two stages; and second, using a stronger model in the first stage. We illustrate the efficacy of our strategy by evaluating multiple models in a two-stage approach with and without beamformer.