 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyBeam: Hybrid Microphone-Beamforming Array-Agnostic Speech Enhancement for Wearables
Oct 26, 2025Speech enhancement is a fundamental challenge in signal processing, particularly when robustness is required across diverse acoustic conditions and microphone setups. Deep learning methods have been successful for speech enhancement, but often assume fixed array geometries, limiting their use in mobile, embedded, and wearable devices. Existing array-agnostic approaches typically rely on either raw microphone signals or beamformer outputs, but both have drawbacks under changing geometries. We introduce HyBeam, a hybrid framework that uses raw microphone signals at low frequencies and beamformer signals at higher frequencies, exploiting their complementary strengths while remaining highly array-agnostic. Simulations across diverse rooms and wearable array configurations demonstrate that HyBeam consistently surpasses microphone-only and beamformer-only baselines in PESQ, STOI, and SI-SDR. A bandwise analysis shows that the hybrid approach leverages beamformer directivity at high frequencies and microphone cues at low frequencies, outperforming either method alone across all bands.
SRP-PHAT-NET: A Reliability-Driven DNN for Reverberant Speaker Localization
Oct 26, 2025

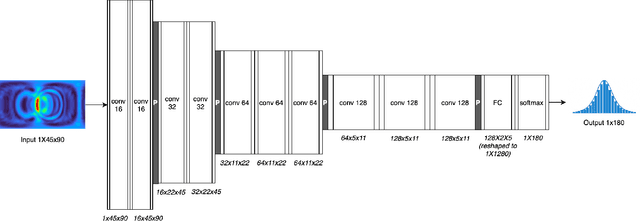

Accurate Direction-of-Arrival (DOA) estimation in reverberant environments remains a fundamental challenge for spatial audio applications. While deep learning methods have shown strong performance in such conditions, they typically lack a mechanism to assess the reliability of their predictions - an essential feature for real-world deployment. In this work, we present the SRP-PHAT-NET, a deep neural network framework that leverages SRP-PHAT directional maps as spatial features and introduces a built-in reliability estimation. To enable meaningful reliability scoring, the model is trained using Gaussian-weighted labels centered around the true direction. We systematically analyze the influence of label smoothing on accuracy and reliability, demonstrating that the choice of Gaussian kernel width can be tuned to application-specific requirements. Experimental results show that selectively using high-confidence predictions yields significantly improved localization accuracy, highlighting the practical benefits of integrating reliability into deep learning-based DOA estimation.
The importance of spatial and spectral information in multiple speaker tracking
Oct 15, 2024Multi-speaker localization and tracking using microphone array recording is of importance in a wide range of applications. One of the challenges with multi-speaker tracking is to associate direction estimates with the correct speaker. Most existing association approaches rely on spatial or spectral information alone, leading to performance degradation when one of these information channels is partially known or missing. This paper studies a joint probability data association (JPDA)-based method that facilitates association based on joint spatial-spectral information. This is achieved by integrating speaker time-frequency (TF) masks, estimated based on spectral information, in the association probabilities calculation. An experimental study that tested the proposed method on recordings from the LOCATA challenge demonstrates the enhanced performance obtained by using joint spatial-spectral information in the association.
Improved direction of arrival estimations with a wearable microphone array for dynamic environments by reliability weighting
Sep 22, 2024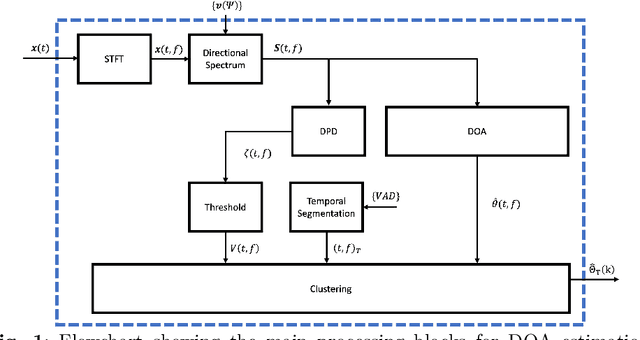
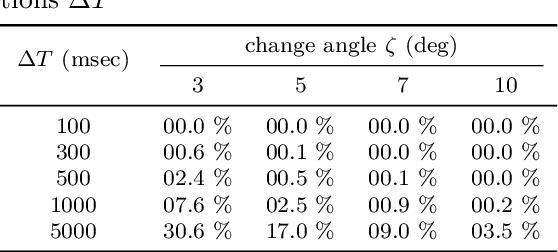
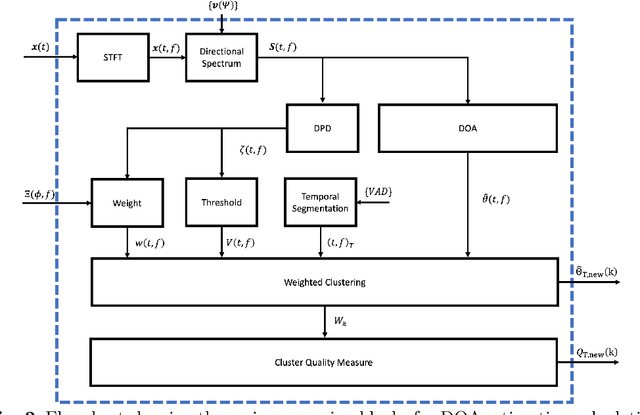

Direction-of-arrival estimation of multiple speakers in a room is an important task for a wide range of applications. In particular, challenging environments with moving speakers, reverberation and noise, lead to significant performance degradation for current methods. With the aim of better understanding factors affecting performance and improving current methods, in this paper multi-speaker direction-of-arrival (DOA) estimation is investigated using a modified version of the local space domain distance (LSDD) algorithm in a noisy, dynamic and reverberant environment employing a wearable microphone array. This study utilizes the recently published EasyCom speech dataset, recorded using a wearable microphone array mounted on eyeglasses. While the original LSDD algorithm demonstrates strong performance in static environments, its efficacy significantly diminishes in the dynamic settings of the EasyCom dataset. Several enhancements to the LSDD algorithm are developed following a comprehensive performance and system analysis, which enable improved DOA estimation under these challenging conditions. These improvements include incorporating a weighted reliability approach and introducing a new quality measure that reliably identifies the more accurate DOA estimates, thereby enhancing both the robustness and accuracy of the algorithm in challenging environments.
Insights into the Incorporation of Signal Information in Binaural Signal Matching with Wearable Microphone Arrays
Sep 18, 2024The increasing popularity of spatial audio in applications such as teleconferencing, entertainment, and virtual reality has led to the recent developments of binaural reproduction methods. However, only a few of these methods are well-suited for wearable and mobile arrays, which typically consist of a small number of microphones. One such method is binaural signal matching (BSM), which has been shown to produce high-quality binaural signals for wearable arrays. However, BSM may be suboptimal in cases of high direct-to-reverberant ratio (DRR) as it is based on the diffuse sound field assumption. To overcome this limitation, previous studies incorporated sound-field models other than diffuse. However, this approach was not studied comprehensively. This paper extensively investigates two BSM-based methods designed for high DRR scenarios. The methods incorporate a sound field model composed of direct and reverberant components.The methods are investigated both mathematically and using simulations, finally validated by a listening test. The results show that the proposed methods can significantly improve the performance of BSM , in particular in the direction of the source, while presenting only a negligible degradation in other directions. Furthermore, when source direction estimation is inaccurate, performance of these methods degrade to equal that of the BSM, presenting a desired robustness quality.
Design and Analysis of Binaural Signal Matching with Arbitrary Microphone Arrays
Aug 07, 2024Binaural reproduction is rapidly becoming a topic of great interest in the research community, especially with the surge of new and popular devices, such as virtual reality headsets, smart glasses, and head-tracked headphones. In order to immerse the listener in a virtual or remote environment with such devices, it is essential to generate realistic and accurate binaural signals. This is challenging, especially since the microphone arrays mounted on these devices are typically composed of an arbitrarily-arranged small number of microphones, which impedes the use of standard audio formats like Ambisonics, and provides limited spatial resolution. The binaural signal matching (BSM) method was developed recently to overcome these challenges. While it produced binaural signals with low error using relatively simple arrays, its performance degraded significantly when head rotation was introduced. This paper aims to develop the BSM method further and overcome its limitations. For this purpose, the method is first analyzed in detail, and a design framework that guarantees accurate binaural reproduction for relatively complex acoustic environments is presented. Next, it is shown that the BSM accuracy may significantly degrade at high frequencies, and thus, a perceptually motivated extension to the method is proposed, based on a magnitude least-squares (MagLS) formulation. These insights and developments are then analyzed with the help of an extensive simulation study of a simple six-microphone semi-circular array. It is further shown that the BSM-MagLS method can be very useful in compensating for head rotations with this array. Finally, a listening experiment is conducted with a four-microphone array on a pair of glasses in a reverberant speech environment and including head rotations, where it is shown that BSM-MagLS can indeed produce binaural signals with a high perceived quality.
Ambisonics Networks -- The Effect Of Radial Functions Regularization
Feb 29, 2024Ambisonics, a popular format of spatial audio, is the spherical harmonic (SH) representation of the plane wave density function of a sound field. Many algorithms operate in the SH domain and utilize the Ambisonics as their input signal. The process of encoding Ambisonics from a spherical microphone array involves dividing by the radial functions, which may amplify noise at low frequencies. This can be overcome by regularization, with the downside of introducing errors to the Ambisonics encoding. This paper aims to investigate the impact of different ways of regularization on Deep Neural Network (DNN) training and performance. Ideally, these networks should be robust to the way of regularization. Simulated data of a single speaker in a room and experimental data from the LOCATA challenge were used to evaluate this robustness on an example algorithm of speaker localization based on the direct-path dominance (DPD) test. Results show that performance may be sensitive to the way of regularization, and an informed approach is proposed and investigated, highlighting the importance of regularization information.
Ambisonics Encoding For Arbitrary Microphone Arrays Incorporating Residual Channels For Binaural Reproduction
Feb 27, 2024


In the rapidly evolving fields of virtual and augmented reality, accurate spatial audio capture and reproduction are essential. For these applications, Ambisonics has emerged as a standard format. However, existing methods for encoding Ambisonics signals from arbitrary microphone arrays face challenges, such as errors due to the irregular array configurations and limited spatial resolution resulting from a typically small number of microphones. To address these limitations and challenges, a mathematical framework for studying Ambisonics encoding is presented, highlighting the importance of incorporating the full steering function, and providing a novel measure for predicting the accuracy of encoding each Ambisonics channel from the steering functions alone. Furthermore, novel residual channels are formulated supplementing the Ambisonics channels. A simulation study for several array configurations demonstrates a reduction in binaural error for this approach.
Theoretical Framework for the Optimization of Microphone Array Configuration for Humanoid Robot Audition
Jan 06, 2024



An important aspect of a humanoid robot is audition. Previous work has presented robot systems capable of sound localization and source segregation based on microphone arrays with various configurations. However, no theoretical framework for the design of these arrays has been presented. In the current paper, a design framework is proposed based on a novel array quality measure. The measure is based on the effective rank of a matrix composed of the generalized head related transfer functions (GHRTFs) that account for microphone positions other than the ears. The measure is shown to be theoretically related to standard array performance measures such as beamforming robustness and DOA estimation accuracy. Then, the measure is applied to produce sample designs of microphone arrays. Their performance is investigated numerically, verifying the advantages of array design based on the proposed theoretical framework.
Direction of Arrival Estimation Using Microphone Array Processing for Moving Humanoid Robots
Jan 04, 2024The auditory system of humanoid robots has gained increased attention in recent years. This system typically acquires the surrounding sound field by means of a microphone array. Signals acquired by the array are then processed using various methods. One of the widely applied methods is direction of arrival estimation. The conventional direction of arrival estimation methods assume that the array is fixed at a given position during the estimation. However, this is not necessarily true for an array installed on a moving humanoid robot. The array motion, if not accounted for appropriately, can introduce a significant error in the estimated direction of arrival. The current paper presents a signal model that takes the motion into account. Based on this model, two processing methods are proposed. The first one compensates for the motion of the robot. The second method is applicable to periodic signals and utilizes the motion in order to enhance the performance to a level beyond that of a stationary array. Numerical simulations and an experimental study are provided, demonstrating that the motion compensation method almost eliminates the motion-related error. It is also demonstrated that by using the motion-based enhancement method it is possible to improve the direction of arrival estimation performance, as compared to that obtained when using a stationary array.