 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Learning for Neural Ambisonics Encoders
Jan 26, 2026Emerging wearable devices such as smartglasses and extended reality headsets demand high-quality spatial audio capture from compact, head-worn microphone arrays. Ambisonics provides a device-agnostic spatial audio representation by mapping array signals to spherical harmonic (SH) coefficients. In practice, however, accurate encoding remains challenging. While traditional linear encoders are signal-independent and robust, they amplify low-frequency noise and suffer from high-frequency spatial aliasing. On the other hand, neural network approaches can outperform linear encoders but they often assume idealized microphones and may perform inconsistently in real-world scenarios. To leverage their complementary strengths, we introduce a residual-learning framework that refines a linear encoder with corrections from a neural network. Using measured array transfer functions from smartglasses, we compare a UNet-based encoder from the literature with a new recurrent attention model. Our analysis reveals that both neural encoders only consistently outperform the linear baseline when integrated within the residual learning framework. In the residual configuration, both neural models achieve consistent and significant improvements across all tested metrics for in-domain data and moderate gains for out-of-domain data. Yet, coherence analysis indicates that all neural encoder configurations continue to struggle with directionally accurate high-frequency encoding.
BSM-iMagLS: ILD Informed Binaural Signal Matching for Reproduction with Head-Mounted Microphone Arrays
Jan 30, 2025

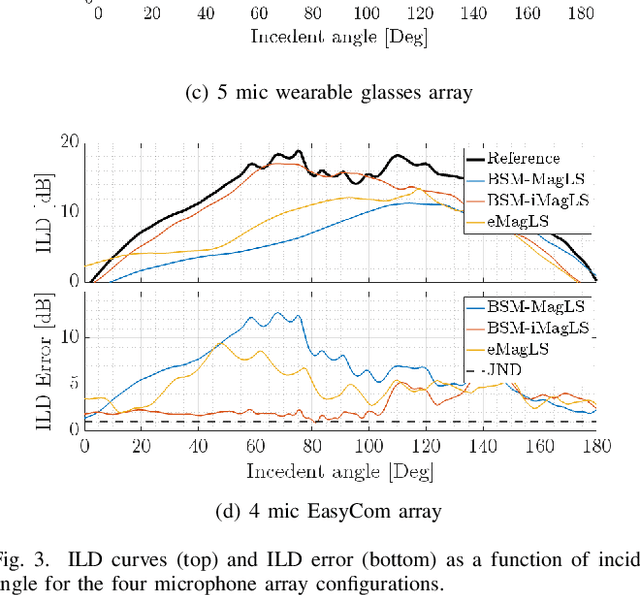

Headphone listening in applications such as augmented and virtual reality (AR and VR) relies on high-quality spatial audio to ensure immersion, making accurate binaural reproduction a critical component. As capture devices, wearable arrays with only a few microphones with irregular arrangement face challenges in achieving a reproduction quality comparable to that of arrays with a large number of microphones. Binaural signal matching (BSM) has recently been presented as a signal-independent approach for generating high-quality binaural signal using only a few microphones, which is further improved using magnitude-least squares (MagLS) optimization at high frequencies. This paper extends BSM with MagLS by introducing interaural level difference (ILD) into the MagLS, integrated into BSM (BSM-iMagLS). Using a deep neural network (DNN)-based solver, BSM-iMagLS achieves joint optimization of magnitude, ILD, and magnitude derivatives, improving spatial fidelity. Performance is validated through theoretical analysis, numerical simulations with diverse HRTFs and head-mounted array geometries, and listening experiments, demonstrating a substantial reduction in ILD errors while maintaining comparable magnitude accuracy to state-of-the-art solutions. The results highlight the potential of BSM-iMagLS to enhance binaural reproduction for wearable and portable devices.
Insights into the Incorporation of Signal Information in Binaural Signal Matching with Wearable Microphone Arrays
Sep 18, 2024The increasing popularity of spatial audio in applications such as teleconferencing, entertainment, and virtual reality has led to the recent developments of binaural reproduction methods. However, only a few of these methods are well-suited for wearable and mobile arrays, which typically consist of a small number of microphones. One such method is binaural signal matching (BSM), which has been shown to produce high-quality binaural signals for wearable arrays. However, BSM may be suboptimal in cases of high direct-to-reverberant ratio (DRR) as it is based on the diffuse sound field assumption. To overcome this limitation, previous studies incorporated sound-field models other than diffuse. However, this approach was not studied comprehensively. This paper extensively investigates two BSM-based methods designed for high DRR scenarios. The methods incorporate a sound field model composed of direct and reverberant components.The methods are investigated both mathematically and using simulations, finally validated by a listening test. The results show that the proposed methods can significantly improve the performance of BSM , in particular in the direction of the source, while presenting only a negligible degradation in other directions. Furthermore, when source direction estimation is inaccurate, performance of these methods degrade to equal that of the BSM, presenting a desired robustness quality.
Design and Analysis of Binaural Signal Matching with Arbitrary Microphone Arrays
Aug 07, 2024Binaural reproduction is rapidly becoming a topic of great interest in the research community, especially with the surge of new and popular devices, such as virtual reality headsets, smart glasses, and head-tracked headphones. In order to immerse the listener in a virtual or remote environment with such devices, it is essential to generate realistic and accurate binaural signals. This is challenging, especially since the microphone arrays mounted on these devices are typically composed of an arbitrarily-arranged small number of microphones, which impedes the use of standard audio formats like Ambisonics, and provides limited spatial resolution. The binaural signal matching (BSM) method was developed recently to overcome these challenges. While it produced binaural signals with low error using relatively simple arrays, its performance degraded significantly when head rotation was introduced. This paper aims to develop the BSM method further and overcome its limitations. For this purpose, the method is first analyzed in detail, and a design framework that guarantees accurate binaural reproduction for relatively complex acoustic environments is presented. Next, it is shown that the BSM accuracy may significantly degrade at high frequencies, and thus, a perceptually motivated extension to the method is proposed, based on a magnitude least-squares (MagLS) formulation. These insights and developments are then analyzed with the help of an extensive simulation study of a simple six-microphone semi-circular array. It is further shown that the BSM-MagLS method can be very useful in compensating for head rotations with this array. Finally, a listening experiment is conducted with a four-microphone array on a pair of glasses in a reverberant speech environment and including head rotations, where it is shown that BSM-MagLS can indeed produce binaural signals with a high perceived quality.
Feasibility of iMagLS-BSM -- ILD Informed Binaural Signal Matching with Arbitrary Microphone Arrays
Aug 07, 2024

Binaural reproduction for headphone-centric listening has become a focal point in ongoing research, particularly within the realm of advancing technologies such as augmented and virtual reality (AR and VR). The demand for high-quality spatial audio in these applications is essential to uphold a seamless sense of immersion. However, challenges arise from wearable recording devices equipped with only a limited number of microphones and irregular microphone placements due to design constraints. These factors contribute to limited reproduction quality compared to reference signals captured by high-order microphone arrays. This paper introduces a novel optimization loss tailored for a beamforming-based, signal-independent binaural reproduction scheme. This method, named iMagLS-BSM incorporates an interaural level difference (ILD) error term into the previously proposed binaural signal matching (BSM) magnitude least squares (MagLS) rendering loss for lateral plane angles. The method leverages nonlinear programming to minimize the introduced loss. Preliminary results show a substantial reduction in ILD error, while maintaining a binaural magnitude error comparable to that achieved with a MagLS BSM solution. These findings hold promise for enhancing the overall spatial quality of resultant binaural signals.
On HRTF Notch Frequency Prediction Using Anthropometric Features and Neural Networks
Mar 12, 2024
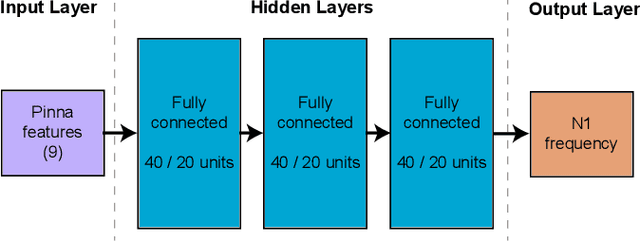

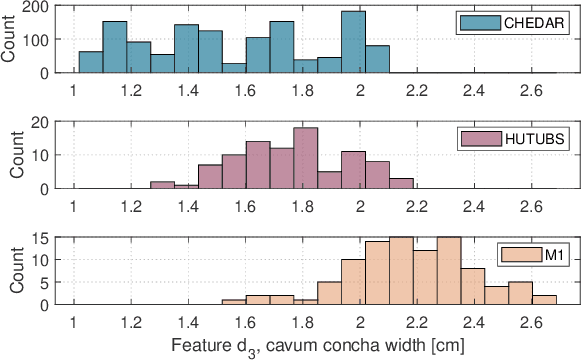
High fidelity spatial audio often performs better when produced using a personalized head-related transfer function (HRTF). However, the direct acquisition of HRTFs is cumbersome and requires specialized equipment. Thus, many personalization methods estimate HRTF features from easily obtained anthropometric features of the pinna, head, and torso. The first HRTF notch frequency (N1) is known to be a dominant feature in elevation localization, and thus a useful feature for HRTF personalization. This paper describes the prediction of N1 frequency from pinna anthropometry using a neural model. Prediction is performed separately on three databases, both simulated and measured, and then by domain mixing in-between the databases. The model successfully predicts N1 frequency for individual databases and by domain mixing between some databases. Prediction errors are better or comparable to those previously reported, showing significant improvement when acquired over a large database and with a larger output range.
Ambisonics Encoding For Arbitrary Microphone Arrays Incorporating Residual Channels For Binaural Reproduction
Feb 27, 2024


In the rapidly evolving fields of virtual and augmented reality, accurate spatial audio capture and reproduction are essential. For these applications, Ambisonics has emerged as a standard format. However, existing methods for encoding Ambisonics signals from arbitrary microphone arrays face challenges, such as errors due to the irregular array configurations and limited spatial resolution resulting from a typically small number of microphones. To address these limitations and challenges, a mathematical framework for studying Ambisonics encoding is presented, highlighting the importance of incorporating the full steering function, and providing a novel measure for predicting the accuracy of encoding each Ambisonics channel from the steering functions alone. Furthermore, novel residual channels are formulated supplementing the Ambisonics channels. A simulation study for several array configurations demonstrates a reduction in binaural error for this approach.
iMagLS: Interaural Level Difference with Magnitude Least-Squares Loss for Optimized First-Order Head-Related Transfer Function
Nov 28, 2023Binaural reproduction for headphone-based listening is an active research area due to its widespread use in evolving technologies such as augmented and virtual reality (AR and VR). On the one hand, these applications demand high quality spatial audio perception to preserve the sense of immersion. On the other hand, recording devices may only have a few microphones, leading to low-order representations such as first-order Ambisonics (FOA). However, first-order Ambisonics leads to limited externalization and spatial resolution. In this paper, a novel head-related transfer function (HRTF) preprocessing optimization loss is proposed, and is minimized using nonlinear programming. The new method, denoted iMagLS, involves the introduction of an interaural level difference (ILD) error term to the now widely used MagLS optimization loss for the lateral plane angles. Results indicate that the ILD error could be substantially reduced, while the HRTF magnitude error remains similar to that obtained with MagLS. These results could prove beneficial to the overall spatial quality of first-order Ambisonics, while other reproduction methods could also benefit from considering this modified loss.
Performance Analysis Of Binaural Signal Matching (BSM) in the Time-Frequency Domain
Nov 23, 2023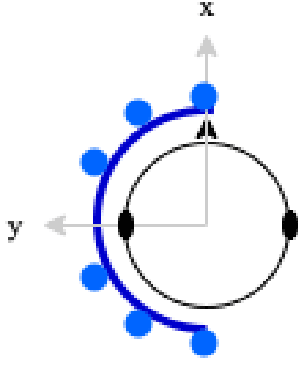
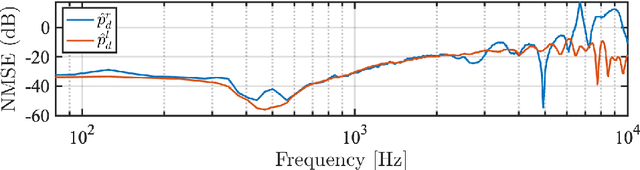
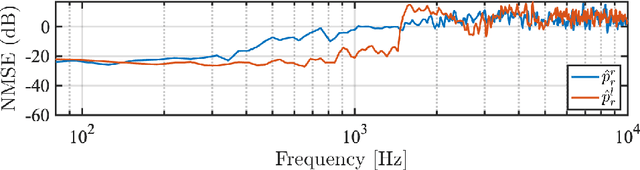
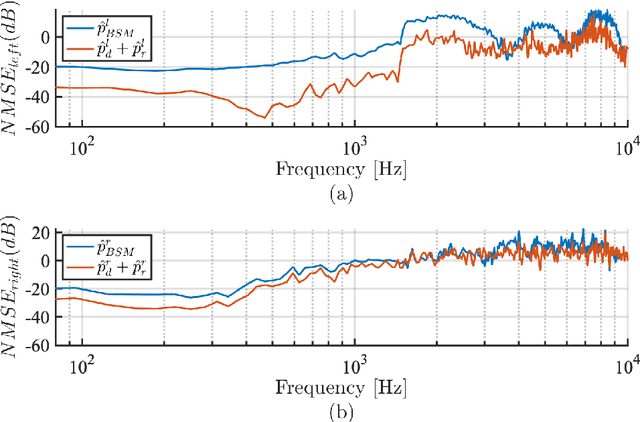
The capture and reproduction of spatial audio is becoming increasingly popular, with the mushrooming of applications in teleconferencing, entertainment and virtual reality. Many binaural reproduction methods have been developed and studied extensively for spherical and other specially designed arrays. However, the recent increased popularity of wearable and mobile arrays requires the development of binaural reproduction methods for these arrays. One such method is binaural signal matching (BSM). However, to date this method has only been investigated with fixed matched filters designed for long audio recordings. With the aim of making the BSM method more adaptive to dynamic environments, this paper analyzes BSM with a parameterized sound-field in the time-frequency domain. The paper presents results of implementing the BSM method on a sound-field that was decomposed into its direct and reverberant components, and compares this implementation with the BSM computed for the entire sound-field, to compare performance for binaural reproduction of reverberant speech in a simulated environment.