 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights into the Incorporation of Signal Information in Binaural Signal Matching with Wearable Microphone Arrays
Sep 18, 2024The increasing popularity of spatial audio in applications such as teleconferencing, entertainment, and virtual reality has led to the recent developments of binaural reproduction methods. However, only a few of these methods are well-suited for wearable and mobile arrays, which typically consist of a small number of microphones. One such method is binaural signal matching (BSM), which has been shown to produce high-quality binaural signals for wearable arrays. However, BSM may be suboptimal in cases of high direct-to-reverberant ratio (DRR) as it is based on the diffuse sound field assumption. To overcome this limitation, previous studies incorporated sound-field models other than diffuse. However, this approach was not studied comprehensively. This paper extensively investigates two BSM-based methods designed for high DRR scenarios. The methods incorporate a sound field model composed of direct and reverberant components.The methods are investigated both mathematically and using simulations, finally validated by a listening test. The results show that the proposed methods can significantly improve the performance of BSM , in particular in the direction of the source, while presenting only a negligible degradation in other directions. Furthermore, when source direction estimation is inaccurate, performance of these methods degrade to equal that of the BSM, presenting a desired robustness quality.
Performance Analysis Of Binaural Signal Matching (BSM) in the Time-Frequency Domain
Nov 23, 2023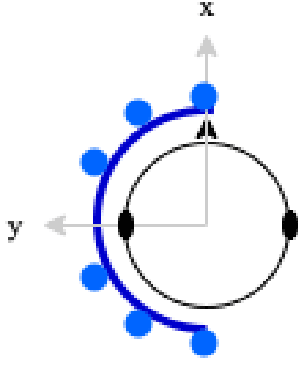
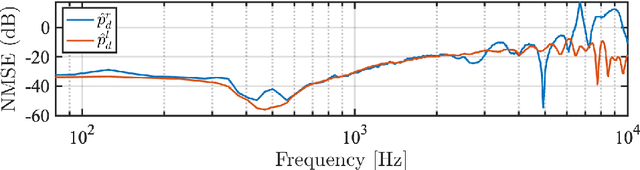
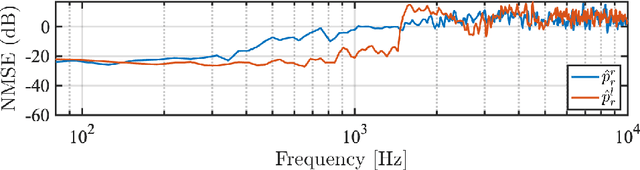
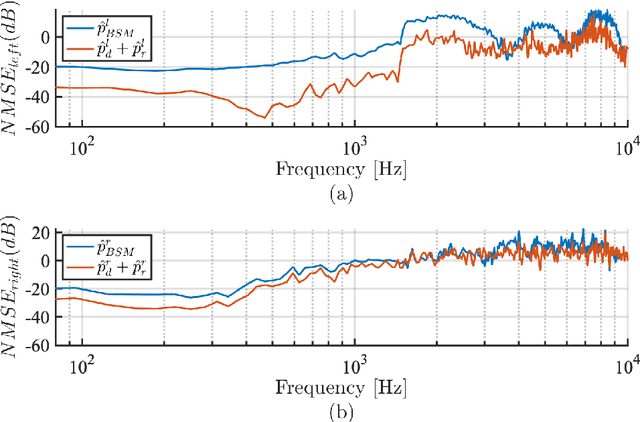
The capture and reproduction of spatial audio is becoming increasingly popular, with the mushrooming of applications in teleconferencing, entertainment and virtual reality. Many binaural reproduction methods have been developed and studied extensively for spherical and other specially designed arrays. However, the recent increased popularity of wearable and mobile arrays requires the development of binaural reproduction methods for these arrays. One such method is binaural signal matching (BSM). However, to date this method has only been investigated with fixed matched filters designed for long audio recordings. With the aim of making the BSM method more adaptive to dynamic environments, this paper analyzes BSM with a parameterized sound-field in the time-frequency domain. The paper presents results of implementing the BSM method on a sound-field that was decomposed into its direct and reverberant components, and compares this implementation with the BSM computed for the entire sound-field, to compare performance for binaural reproduction of reverberant speech in a simulated environment.