 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultichannel Speech Enhancement without Beamforming
Paper and Code
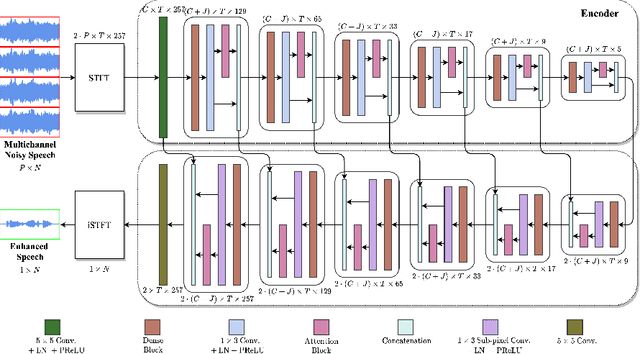

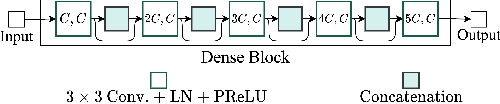
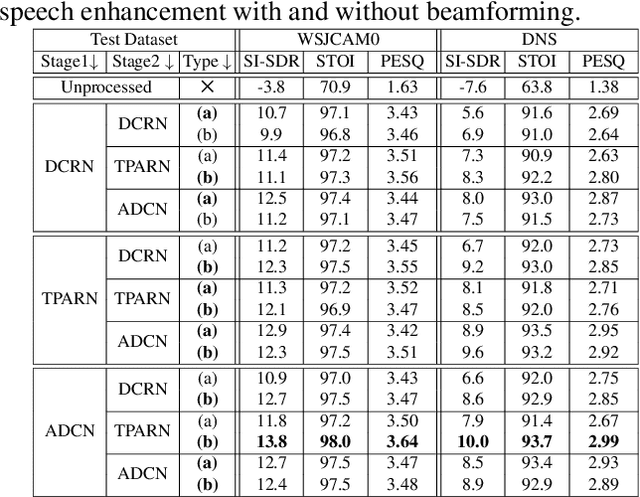
Deep neural networks are often coupled with traditional spatial filters, such as MVDR beamformers for effectively exploiting spatial information. Even though single-stage end-to-end supervised models can obtain impressive enhancement, combining them with a beamformer and a DNN-based post-filter in a multistage processing provides additional improvements. In this work, we propose a two-stage strategy for multi-channel speech enhancement that does not need a beamformer for additional performance. First, we propose a novel attentive dense convolutional network (ADCN) for predicting real and imaginary parts of complex spectrogram. ADCN obtains state-of-the-art results among single-stage models. Next, we use ADCN in the proposed strategy with a recently proposed triple-path attentive recurrent network (TPARN) for predicting waveform samples. The proposed strategy uses two insights; first, using different approaches in two stages; and second, using a stronger model in the first stage. We illustrate the efficacy of our strategy by evaluating multiple models in a two-stage approach with and without beamformer.