 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoundSpaces 2.0: A Simulation Platform for Visual-Acoustic Learning
Jun 16, 2022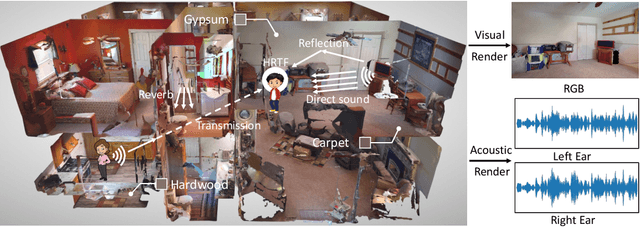


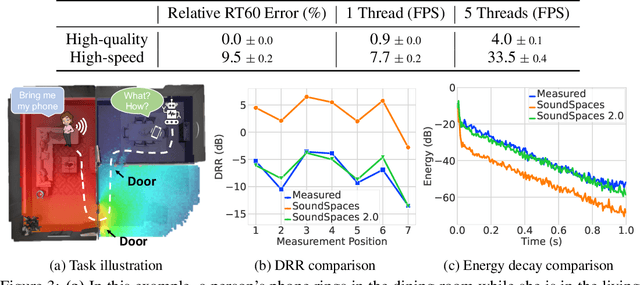
We introduce SoundSpaces 2.0, a platform for on-the-fly geometry-based audio rendering for 3D environments. Given a 3D mesh of a real-world environment, SoundSpaces can generate highly realistic acoustics for arbitrary sounds captured from arbitrary microphone locations. Together with existing 3D visual assets, it supports an array of audio-visual research tasks, such as audio-visual navigation, mapping, source localization and separation, and acoustic matching. Compared to existing resources, SoundSpaces 2.0 has the advantages of allowing continuous spatial sampling, generalization to novel environments, and configurable microphone and material properties. To our best knowledge, this is the first geometry-based acoustic simulation that offers high fidelity and realism while also being fast enough to use for embodied learning. We showcase the simulator's properties and benchmark its performance against real-world audio measurements. In addition, through two downstream tasks covering embodied navigation and far-field automatic speech recognition, highlighting sim2real performance for the latter. SoundSpaces 2.0 is publicly available to facilitate wider research for perceptual systems that can both see and hear.
Audio-Visual Floorplan Reconstruction
Dec 31, 2020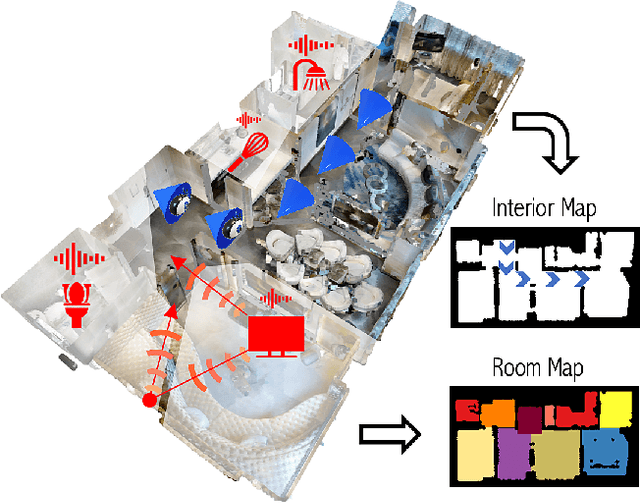
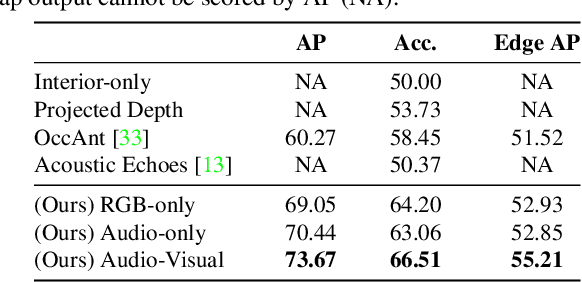
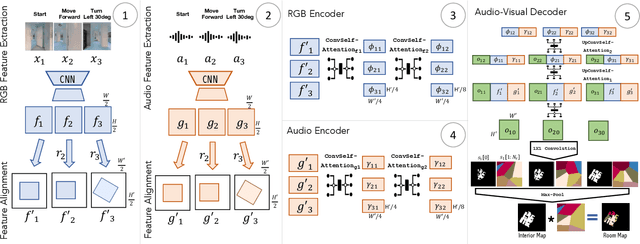
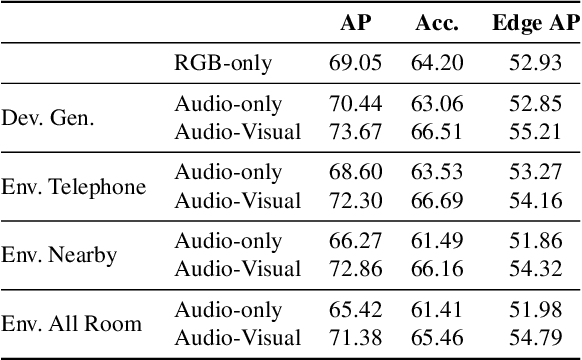
Given only a few glimpses of an environment, how much can we infer about its entire floorplan? Existing methods can map only what is visible or immediately apparent from context, and thus require substantial movements through a space to fully map it. We explore how both audio and visual sensing together can provide rapid floorplan reconstruction from limited viewpoints. Audio not only helps sense geometry outside the camera's field of view, but it also reveals the existence of distant freespace (e.g., a dog barking in another room) and suggests the presence of rooms not visible to the camera (e.g., a dishwasher humming in what must be the kitchen to the left). We introduce AV-Map, a novel multi-modal encoder-decoder framework that reasons jointly about audio and vision to reconstruct a floorplan from a short input video sequence. We train our model to predict both the interior structure of the environment and the associated rooms' semantic labels. Our results on 85 large real-world environments show the impact: with just a few glimpses spanning 26% of an area, we can estimate the whole area with 66% accuracy -- substantially better than the state of the art approach for extrapolating visual maps.
VisualEchoes: Spatial Image Representation Learning through Echolocation
May 04, 2020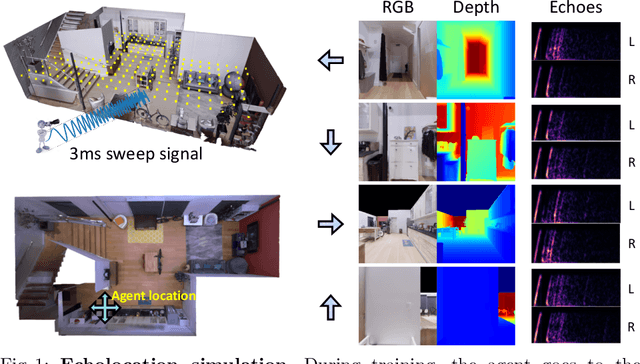



Several animal species (e.g., bats, dolphins, and whales) and even visually impaired humans have the remarkable ability to perform echolocation: a biological sonar used to perceive spatial layout and locate objects in the world. We explore the spatial cues contained in echoes and how they can benefit vision tasks that require spatial reasoning. First we capture echo responses in photo-realistic 3D indoor scene environments. Then we propose a novel interaction-based representation learning framework that learns useful visual features via echolocation. We show that the learned image features are useful for multiple downstream vision tasks requiring spatial reasoning---monocular depth estimation, surface normal estimation, and visual navigation. Our work opens a new path for representation learning for embodied agents, where supervision comes from interacting with the physical world. Our experiments demonstrate that our image features learned from echoes are comparable or even outperform heavily supervised pre-training methods for multiple fundamental spatial tasks.
Audio-Visual Embodied Navigation
Dec 24, 2019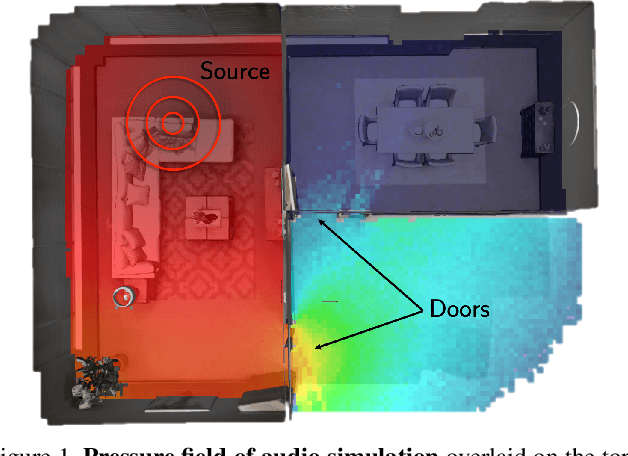


Moving around in the world is naturally a multisensory experience, but today's embodied agents are deaf - restricted to solely their visual perception of the environment. We introduce audio-visual navigation for complex, acoustically and visually realistic 3D environments. By both seeing and hearing, the agent must learn to navigate to an audio-based target. We develop a multi-modal deep reinforcement learning pipeline to train navigation policies end-to-end from a stream of egocentric audio-visual observations, allowing the agent to (1) discover elements of the geometry of the physical space indicated by the reverberating audio and (2) detect and follow sound-emitting targets. We further introduce audio renderings based on geometrical acoustic simulations for a set of publicly available 3D assets and instrument AI-Habitat to support the new sensor, making it possible to insert arbitrary sound sources in an array of apartment, office, and hotel environments. Our results show that audio greatly benefits embodied visual navigation in 3D spaces.