 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeR: Robust Conditional 3D Shape Generation from Casual Captures
Jan 16, 2026Recent advances in 3D shape generation have achieved impressive results, but most existing methods rely on clean, unoccluded, and well-segmented inputs. Such conditions are rarely met in real-world scenarios. We present ShapeR, a novel approach for conditional 3D object shape generation from casually captured sequences. Given an image sequence, we leverage off-the-shelf visual-inertial SLAM, 3D detection algorithms, and vision-language models to extract, for each object, a set of sparse SLAM points, posed multi-view images, and machine-generated captions. A rectified flow transformer trained to effectively condition on these modalities then generates high-fidelity metric 3D shapes. To ensure robustness to the challenges of casually captured data, we employ a range of techniques including on-the-fly compositional augmentations, a curriculum training scheme spanning object- and scene-level datasets, and strategies to handle background clutter. Additionally, we introduce a new evaluation benchmark comprising 178 in-the-wild objects across 7 real-world scenes with geometry annotations. Experiments show that ShapeR significantly outperforms existing approaches in this challenging setting, achieving an improvement of 2.7x in Chamfer distance compared to state of the art.
HOT3D: Hand and Object Tracking in 3D from Egocentric Multi-View Videos
Nov 28, 2024We introduce HOT3D, a publicly available dataset for egocentric hand and object tracking in 3D. The dataset offers over 833 minutes (more than 3.7M images) of multi-view RGB/monochrome image streams showing 19 subjects interacting with 33 diverse rigid objects, multi-modal signals such as eye gaze or scene point clouds, as well as comprehensive ground-truth annotations including 3D poses of objects, hands, and cameras, and 3D models of hands and objects. In addition to simple pick-up/observe/put-down actions, HOT3D contains scenarios resembling typical actions in a kitchen, office, and living room environment. The dataset is recorded by two head-mounted devices from Meta: Project Aria, a research prototype of light-weight AR/AI glasses, and Quest 3, a production VR headset sold in millions of units. Ground-truth poses were obtained by a professional motion-capture system using small optical markers attached to hands and objects. Hand annotations are provided in the UmeTrack and MANO formats and objects are represented by 3D meshes with PBR materials obtained by an in-house scanner. In our experiments, we demonstrate the effectiveness of multi-view egocentric data for three popular tasks: 3D hand tracking, 6DoF object pose estimation, and 3D lifting of unknown in-hand objects. The evaluated multi-view methods, whose benchmarking is uniquely enabled by HOT3D, significantly outperform their single-view counterparts.
Introducing HOT3D: An Egocentric Dataset for 3D Hand and Object Tracking
Jun 13, 2024We introduce HOT3D, a publicly available dataset for egocentric hand and object tracking in 3D. The dataset offers over 833 minutes (more than 3.7M images) of multi-view RGB/monochrome image streams showing 19 subjects interacting with 33 diverse rigid objects, multi-modal signals such as eye gaze or scene point clouds, as well as comprehensive ground truth annotations including 3D poses of objects, hands, and cameras, and 3D models of hands and objects. In addition to simple pick-up/observe/put-down actions, HOT3D contains scenarios resembling typical actions in a kitchen, office, and living room environment. The dataset is recorded by two head-mounted devices from Meta: Project Aria, a research prototype of light-weight AR/AI glasses, and Quest 3, a production VR headset sold in millions of units. Ground-truth poses were obtained by a professional motion-capture system using small optical markers attached to hands and objects. Hand annotations are provided in the UmeTrack and MANO formats and objects are represented by 3D meshes with PBR materials obtained by an in-house scanner. We aim to accelerate research on egocentric hand-object interaction by making the HOT3D dataset publicly available and by co-organizing public challenges on the dataset at ECCV 2024. The dataset can be downloaded from the project website: https://facebookresearch.github.io/hot3d/.
Aria Everyday Activities Dataset
Feb 22, 2024



We present Aria Everyday Activities (AEA) Dataset, an egocentric multimodal open dataset recorded using Project Aria glasses. AEA contains 143 daily activity sequences recorded by multiple wearers in five geographically diverse indoor locations. Each of the recording contains multimodal sensor data recorded through the Project Aria glasses. In addition, AEA provides machine perception data including high frequency globally aligned 3D trajectories, scene point cloud, per-frame 3D eye gaze vector and time aligned speech transcription. In this paper, we demonstrate a few exemplar research applications enabled by this dataset, including neural scene reconstruction and prompted segmentation. AEA is an open source dataset that can be downloaded from https://www.projectaria.com/datasets/aea/. We are also providing open-source implementations and examples of how to use the dataset in Project Aria Tools https://github.com/facebookresearch/projectaria_tools.
Chat2Map: Efficient Scene Mapping from Multi-Ego Conversations
Jan 04, 2023
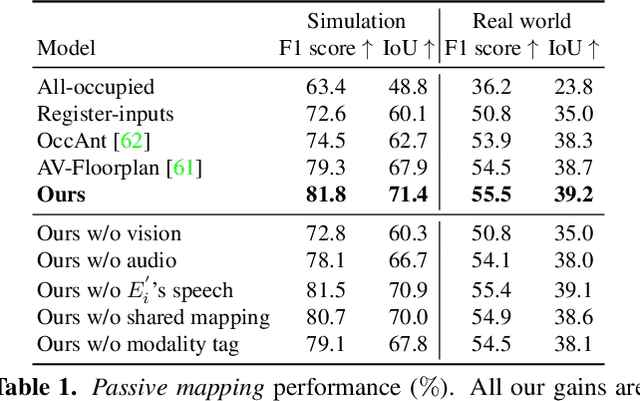

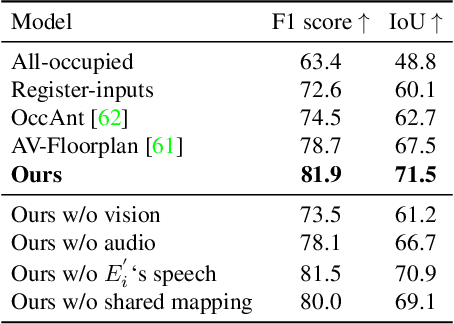
Can conversational videos captured from multiple egocentric viewpoints reveal the map of a scene in a cost-efficient way? We seek to answer this question by proposing a new problem: efficiently building the map of a previously unseen 3D environment by exploiting shared information in the egocentric audio-visual observations of participants in a natural conversation. Our hypothesis is that as multiple people ("egos") move in a scene and talk among themselves, they receive rich audio-visual cues that can help uncover the unseen areas of the scene. Given the high cost of continuously processing egocentric visual streams, we further explore how to actively coordinate the sampling of visual information, so as to minimize redundancy and reduce power use. To that end, we present an audio-visual deep reinforcement learning approach that works with our shared scene mapper to selectively turn on the camera to efficiently chart out the space. We evaluate the approach using a state-of-the-art audio-visual simulator for 3D scenes as well as real-world video. Our model outperforms previous state-of-the-art mapping methods, and achieves an excellent cost-accuracy tradeoff. Project: http://vision.cs.utexas.edu/projects/chat2map.
Pano Popups: Indoor 3D Reconstruction with a Plane-Aware Network
Jul 01, 2019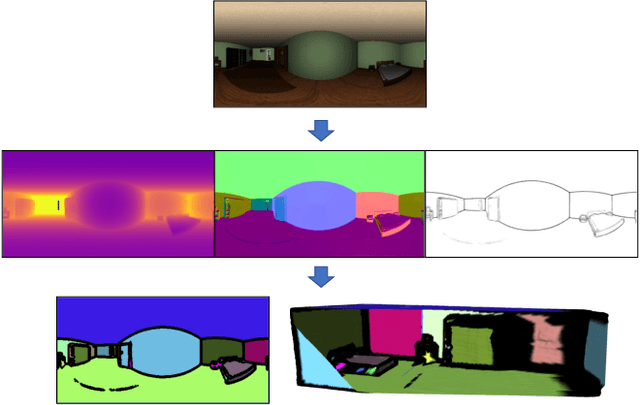
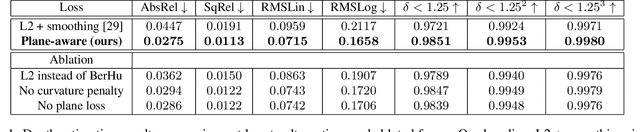
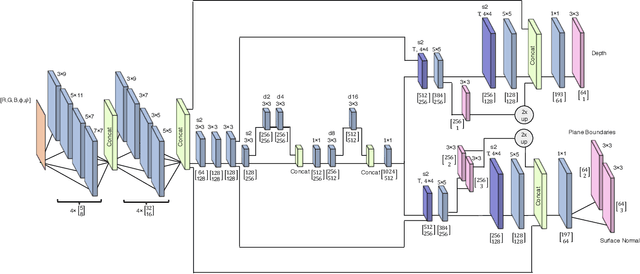
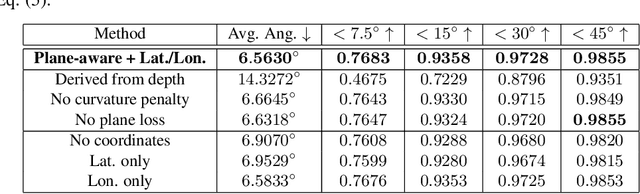
In this work we present a method to train a plane-aware convolutional neural network for dense depth and surface normal estimation as well as plane boundaries from a single indoor \threesixty image. Using our proposed loss function, our network outperforms existing methods for single-view, indoor, omnidirectional depth estimation and provides an initial benchmark for surface normal prediction from \threesixty images. Our improvements are due to the use of a novel plane-aware loss that leverages principal curvature as an indicator of planar boundaries. We also show that including geodesic coordinate maps as network priors provides a significant boost in surface normal prediction accuracy. Finally, we demonstrate how we can combine our network's outputs to generate high quality 3D ``pop-up" models of indoor scenes.