 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoTrack: Generic 6DoF Object Pose Refinement and Tracking
Jun 08, 2025We introduce GoTrack, an efficient and accurate CAD-based method for 6DoF object pose refinement and tracking, which can handle diverse objects without any object-specific training. Unlike existing tracking methods that rely solely on an analysis-by-synthesis approach for model-to-frame registration, GoTrack additionally integrates frame-to-frame registration, which saves compute and stabilizes tracking. Both types of registration are realized by optical flow estimation. The model-to-frame registration is noticeably simpler than in existing methods, relying only on standard neural network blocks (a transformer is trained on top of DINOv2) and producing reliable pose confidence scores without a scoring network. For the frame-to-frame registration, which is an easier problem as consecutive video frames are typically nearly identical, we employ a light off-the-shelf optical flow model. We demonstrate that GoTrack can be seamlessly combined with existing coarse pose estimation methods to create a minimal pipeline that reaches state-of-the-art RGB-only results on standard benchmarks for 6DoF object pose estimation and tracking. Our source code and trained models are publicly available at https://github.com/facebookresearch/gotrack
HOT3D: Hand and Object Tracking in 3D from Egocentric Multi-View Videos
Nov 28, 2024We introduce HOT3D, a publicly available dataset for egocentric hand and object tracking in 3D. The dataset offers over 833 minutes (more than 3.7M images) of multi-view RGB/monochrome image streams showing 19 subjects interacting with 33 diverse rigid objects, multi-modal signals such as eye gaze or scene point clouds, as well as comprehensive ground-truth annotations including 3D poses of objects, hands, and cameras, and 3D models of hands and objects. In addition to simple pick-up/observe/put-down actions, HOT3D contains scenarios resembling typical actions in a kitchen, office, and living room environment. The dataset is recorded by two head-mounted devices from Meta: Project Aria, a research prototype of light-weight AR/AI glasses, and Quest 3, a production VR headset sold in millions of units. Ground-truth poses were obtained by a professional motion-capture system using small optical markers attached to hands and objects. Hand annotations are provided in the UmeTrack and MANO formats and objects are represented by 3D meshes with PBR materials obtained by an in-house scanner. In our experiments, we demonstrate the effectiveness of multi-view egocentric data for three popular tasks: 3D hand tracking, 6DoF object pose estimation, and 3D lifting of unknown in-hand objects. The evaluated multi-view methods, whose benchmarking is uniquely enabled by HOT3D, significantly outperform their single-view counterparts.
Introducing HOT3D: An Egocentric Dataset for 3D Hand and Object Tracking
Jun 13, 2024We introduce HOT3D, a publicly available dataset for egocentric hand and object tracking in 3D. The dataset offers over 833 minutes (more than 3.7M images) of multi-view RGB/monochrome image streams showing 19 subjects interacting with 33 diverse rigid objects, multi-modal signals such as eye gaze or scene point clouds, as well as comprehensive ground truth annotations including 3D poses of objects, hands, and cameras, and 3D models of hands and objects. In addition to simple pick-up/observe/put-down actions, HOT3D contains scenarios resembling typical actions in a kitchen, office, and living room environment. The dataset is recorded by two head-mounted devices from Meta: Project Aria, a research prototype of light-weight AR/AI glasses, and Quest 3, a production VR headset sold in millions of units. Ground-truth poses were obtained by a professional motion-capture system using small optical markers attached to hands and objects. Hand annotations are provided in the UmeTrack and MANO formats and objects are represented by 3D meshes with PBR materials obtained by an in-house scanner. We aim to accelerate research on egocentric hand-object interaction by making the HOT3D dataset publicly available and by co-organizing public challenges on the dataset at ECCV 2024. The dataset can be downloaded from the project website: https://facebookresearch.github.io/hot3d/.
United We Learn Better: Harvesting Learning Improvements From Class Hierarchies Across Tasks
Jul 28, 2021



Attempts of learning from hierarchical taxonomies in computer vision have been mostly focusing on image classification. Though ways of best harvesting learning improvements from hierarchies in classification are far from being solved, there is a need to target these problems in other vision tasks such as object detection. As progress on the classification side is often dependent on hierarchical cross-entropy losses, novel detection architectures using sigmoid as an output function instead of softmax cannot easily apply these advances, requiring novel methods in detection. In this work we establish a theoretical framework based on probability and set theory for extracting parent predictions and a hierarchical loss that can be used across tasks, showing results across classification and detection benchmarks and opening up the possibility of hierarchical learning for sigmoid-based detection architectures.
Prior to Segment: Foreground Cues for Novel Objects in Partially Supervised Instance Segmentation
Nov 23, 2020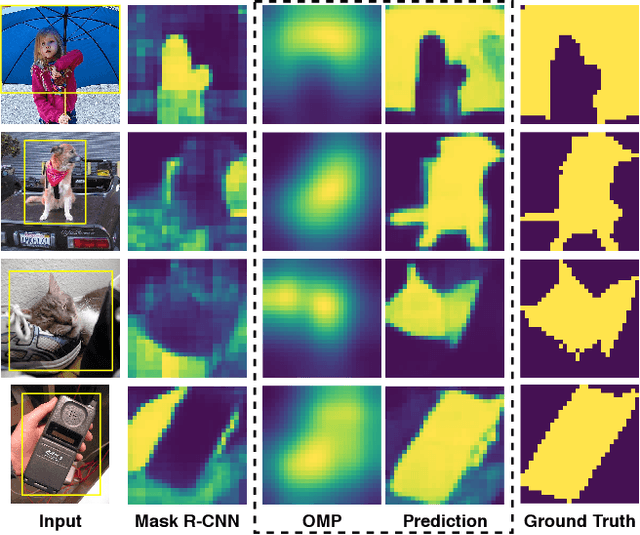

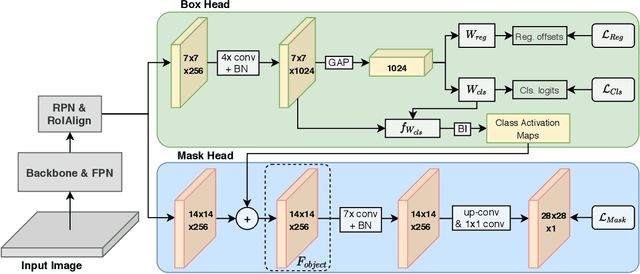

Instance segmentation methods require large datasets with expensive instance-level mask labels. This makes partially supervised learning appealing in settings where abundant box and limited mask labels are available. To improve mask predictions with limited labels, we modify a Mask R-CNN by introducing an object mask prior (OMP) for the mask head. We show that a conventional class-agnostic mask head has difficulties learning foreground for classes with box-supervision only. Our OMP resolves this by providing the mask head with the general concept of foreground implicitly learned by the box classification head under the supervision of all classes. This helps the class-agnostic mask head to focus on the primary object in a region of interest (RoI) and improves generalization to novel classes. We test our approach on the COCO dataset using different splits of strongly and weakly supervised classes. Our approach significantly improves over the Mask R-CNN baseline and obtains competitive performance with the state-of-the-art, while offering a much simpler architecture.
Dynamic Adaptation on Non-Stationary Visual Domains
Aug 02, 2018
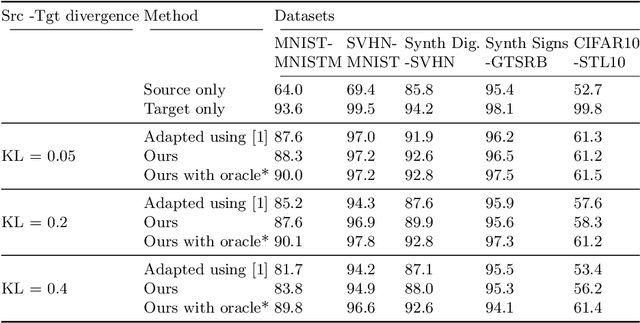

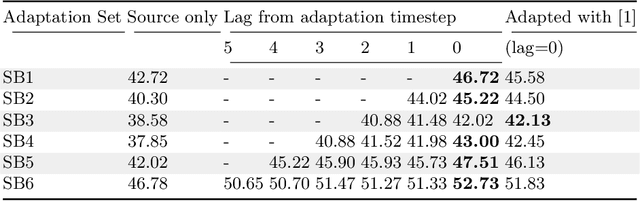
Domain adaptation aims to learn models on a supervised source domain that perform well on an unsupervised target. Prior work has examined domain adaptation in the context of stationary domain shifts, i.e. static data sets. However, with large-scale or dynamic data sources, data from a defined domain is not usually available all at once. For instance, in a streaming data scenario, dataset statistics effectively become a function of time. We introduce a framework for adaptation over non-stationary distribution shifts applicable to large-scale and streaming data scenarios. The model is adapted sequentially over incoming unsupervised streaming data batches. This enables improvements over several batches without the need for any additionally annotated data. To demonstrate the effectiveness of our proposed framework, we modify associative domain adaptation to work well on source and target data batches with unequal class distributions. We apply our method to several adaptation benchmark datasets for classification and show improved classifier accuracy not only for the currently adapted batch, but also when applied on future stream batches. Furthermore, we show the applicability of our associative learning modifications to semantic segmentation, where we achieve competitive results.