 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Descriptors for Intrinsic Reflectance Optimization
Apr 08, 2022
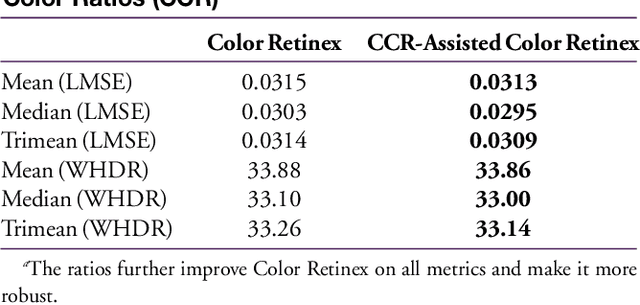

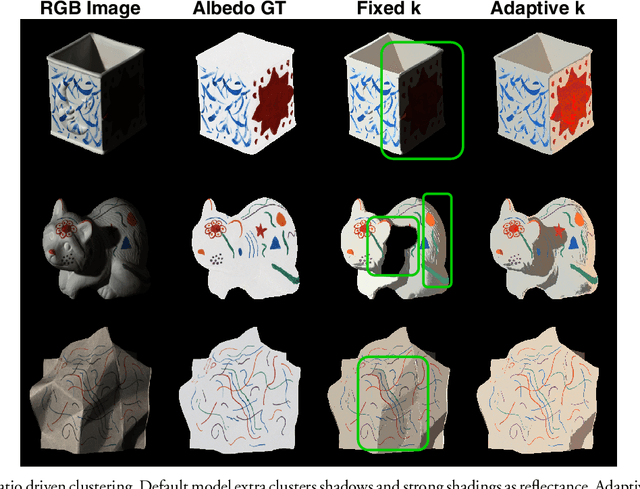
Intrinsic image decomposition aims to factorize an image into albedo (reflectance) and shading (illumination) sub-components. Being ill-posed and under-constrained, it is a very challenging computer vision problem. There are infinite pairs of reflectance and shading images that can reconstruct the same input. To address the problem, Intrinsic Images in the Wild provides an optimization framework based on a dense conditional random field (CRF) formulation that considers long-range material relations. We improve upon their model by introducing illumination invariant image descriptors: color ratios. The color ratios and the reflectance intrinsic are both invariant to illumination and thus are highly correlated. Through detailed experiments, we provide ways to inject the color ratios into the dense CRF optimization. Our approach is physics-based, learning-free and leads to more accurate and robust reflectance decompositions.
Prior to Segment: Foreground Cues for Novel Objects in Partially Supervised Instance Segmentation
Nov 23, 2020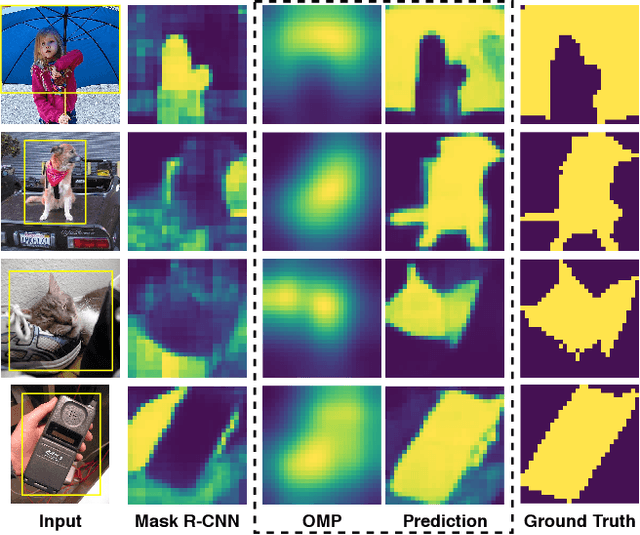

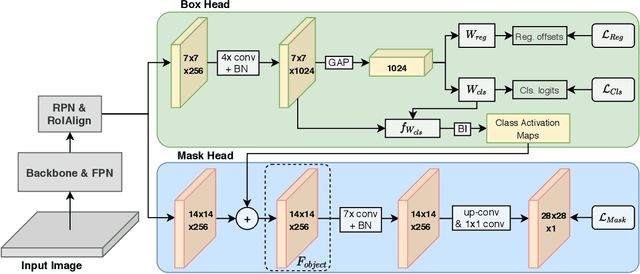

Instance segmentation methods require large datasets with expensive instance-level mask labels. This makes partially supervised learning appealing in settings where abundant box and limited mask labels are available. To improve mask predictions with limited labels, we modify a Mask R-CNN by introducing an object mask prior (OMP) for the mask head. We show that a conventional class-agnostic mask head has difficulties learning foreground for classes with box-supervision only. Our OMP resolves this by providing the mask head with the general concept of foreground implicitly learned by the box classification head under the supervision of all classes. This helps the class-agnostic mask head to focus on the primary object in a region of interest (RoI) and improves generalization to novel classes. We test our approach on the COCO dataset using different splits of strongly and weakly supervised classes. Our approach significantly improves over the Mask R-CNN baseline and obtains competitive performance with the state-of-the-art, while offering a much simpler architecture.
Physics-based Shading Reconstruction for Intrinsic Image Decomposition
Sep 03, 2020



We investigate the use of photometric invariance and deep learning to compute intrinsic images (albedo and shading). We propose albedo and shading gradient descriptors which are derived from physics-based models. Using the descriptors, albedo transitions are masked out and an initial sparse shading map is calculated directly from the corresponding RGB image gradients in a learning-free unsupervised manner. Then, an optimization method is proposed to reconstruct the full dense shading map. Finally, we integrate the generated shading map into a novel deep learning framework to refine it and also to predict corresponding albedo image to achieve intrinsic image decomposition. By doing so, we are the first to directly address the texture and intensity ambiguity problems of the shading estimations. Large scale experiments show that our approach steered by physics-based invariant descriptors achieve superior results on MIT Intrinsics, NIR-RGB Intrinsics, Multi-Illuminant Intrinsic Images, Spectral Intrinsic Images, As Realistic As Possible, and competitive results on Intrinsic Images in the Wild datasets while achieving state-of-the-art shading estimations.
ShadingNet: Image Intrinsics by Fine-Grained Shading Decomposition
Dec 09, 2019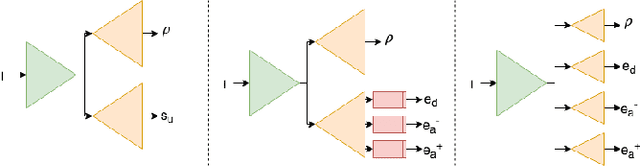



In general, intrinsic image decomposition algorithms interpret shading as one unified component including all photometric effects. As shading transitions are generally smoother than albedo changes, these methods may fail in distinguishing strong (cast) shadows from albedo variations. That in return may leak into albedo map predictions. Therefore, in this paper, we propose to decompose the shading component into direct (illumination) and indirect shading (ambient light and shadows). The aim is to distinguish strong cast shadows from reflectance variations. Two end-to-end supervised CNN models (ShadingNets) are proposed exploiting the fine-grained shading model. Furthermore, surface normal features are jointly learned by the proposed CNN networks. Surface normals are expected to assist the decomposition task. A large-scale dataset of scene-level synthetic images of outdoor natural environments is provided with intrinsic image ground-truths. Large scale experiments show that our CNN approach using fine-grained shading decomposition outperforms state-of-the-art methods using unified shading.
Unsupervised Generation of Optical Flow Datasets from Videos in the Wild
Dec 10, 2018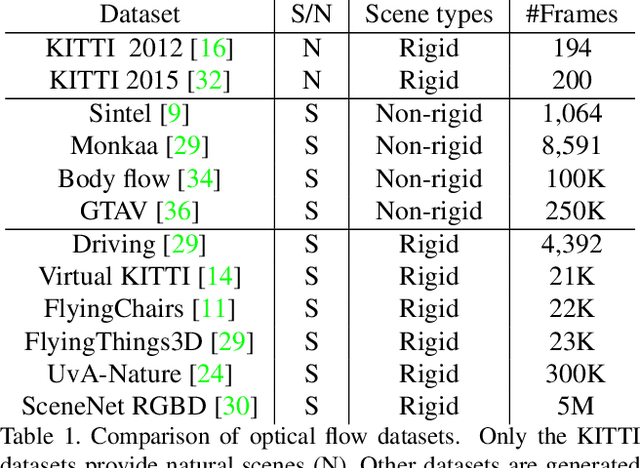


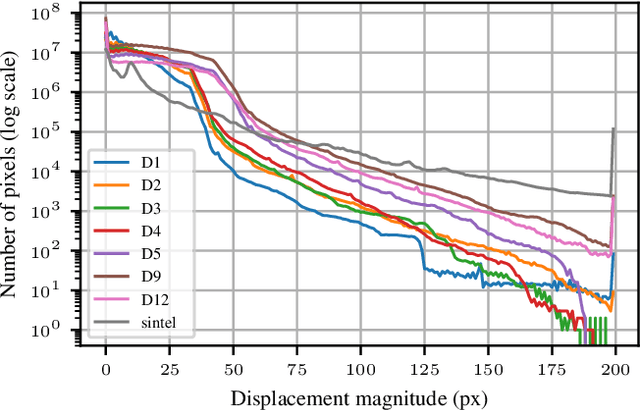
Dense optical flow ground truths of non-rigid motion for real-world images are not available due to the non-intuitive annotation. Aiming at training optical flow deep networks, we present an unsupervised algorithm to generate optical flow ground truth from real-world videos. The algorithm extracts and matches objects of interest from pairs of images in videos to find initial constraints, and applies as-rigid-as-possible deformation over the objects of interest to obtain dense flow fields. The ground truth correctness is enforced by warping the objects in the first frames using the flow fields. We apply the algorithm on the DAVIS dataset to obtain optical flow ground truths for non-rigid movement of real-world objects, using either ground truth or predicted segmentation. We discuss several methods to increase the optical flow variations in the dataset. Extensive experimental results show that training on non-rigid real motion is beneficial compared to training on rigid synthetic data. Moreover, we show that our pipeline generates training data suitable to train successfully FlowNet-S, PWC-Net, and LiteFlowNet deep networks.
Color Constancy by GANs: An Experimental Survey
Dec 07, 2018
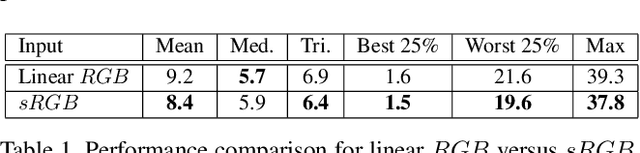
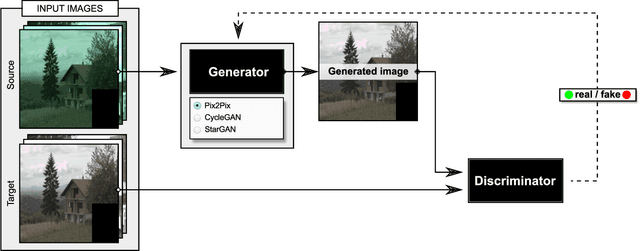
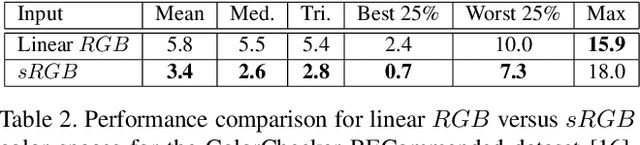
In this paper, we formulate the color constancy task as an image-to-image translation problem using GANs. By conducting a large set of experiments on different datasets, an experimental survey is provided on the use of different types of GANs to solve for color constancy i.e. CC-GANs (Color Constancy GANs). Based on the experimental review, recommendations are given for the design of CC-GAN architectures based on different criteria, circumstances and datasets.
Joint Learning of Intrinsic Images and Semantic Segmentation
Jul 31, 2018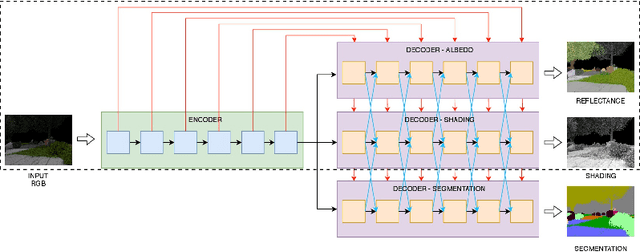
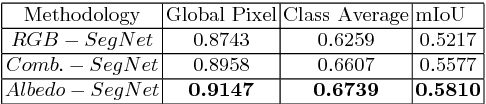

Semantic segmentation of outdoor scenes is problematic when there are variations in imaging conditions. It is known that albedo (reflectance) is invariant to all kinds of illumination effects. Thus, using reflectance images for semantic segmentation task can be favorable. Additionally, not only segmentation may benefit from reflectance, but also segmentation may be useful for reflectance computation. Therefore, in this paper, the tasks of semantic segmentation and intrinsic image decomposition are considered as a combined process by exploring their mutual relationship in a joint fashion. To that end, we propose a supervised end-to-end CNN architecture to jointly learn intrinsic image decomposition and semantic segmentation. We analyze the gains of addressing those two problems jointly. Moreover, new cascade CNN architectures for intrinsic-for-segmentation and segmentation-for-intrinsic are proposed as single tasks. Furthermore, a dataset of 35K synthetic images of natural environments is created with corresponding albedo and shading (intrinsics), as well as semantic labels (segmentation) assigned to each object/scene. The experiments show that joint learning of intrinsic image decomposition and semantic segmentation is beneficial for both tasks for natural scenes. Dataset and models are available at: https://ivi.fnwi.uva.nl/cv/intrinseg
Three for one and one for three: Flow, Segmentation, and Surface Normals
Jul 19, 2018Optical flow, semantic segmentation, and surface normals represent different information modalities, yet together they bring better cues for scene understanding problems. In this paper, we study the influence between the three modalities: how one impacts on the others and their efficiency in combination. We employ a modular approach using a convolutional refinement network which is trained supervised but isolated from RGB images to enforce joint modality features. To assist the training process, we create a large-scale synthetic outdoor dataset that supports dense annotation of semantic segmentation, optical flow, and surface normals. The experimental results show positive influence among the three modalities, especially for objects' boundaries, region consistency, and scene structures.
CNN based Learning using Reflection and Retinex Models for Intrinsic Image Decomposition
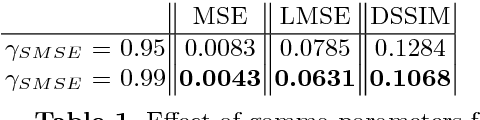
Apr 03, 2018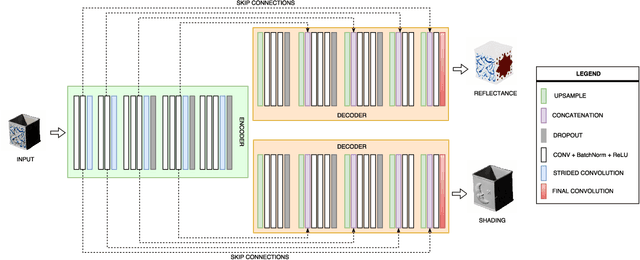
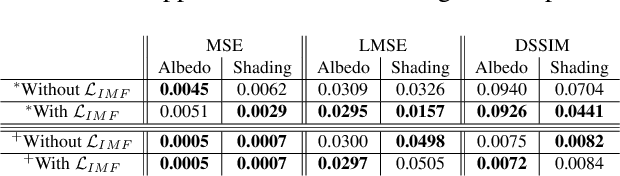
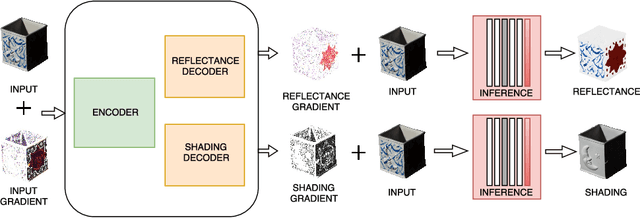
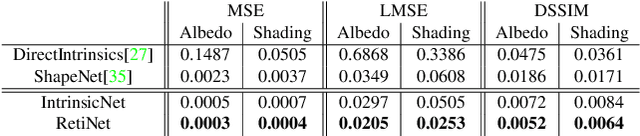
Most of the traditional work on intrinsic image decomposition rely on deriving priors about scene characteristics. On the other hand, recent research use deep learning models as in-and-out black box and do not consider the well-established, traditional image formation process as the basis of their intrinsic learning process. As a consequence, although current deep learning approaches show superior performance when considering quantitative benchmark results, traditional approaches are still dominant in achieving high qualitative results. In this paper, the aim is to exploit the best of the two worlds. A method is proposed that (1) is empowered by deep learning capabilities, (2) considers a physics-based reflection model to steer the learning process, and (3) exploits the traditional approach to obtain intrinsic images by exploiting reflectance and shading gradient information. The proposed model is fast to compute and allows for the integration of all intrinsic components. To train the new model, an object centered large-scale datasets with intrinsic ground-truth images are created. The evaluation results demonstrate that the new model outperforms existing methods. Visual inspection shows that the image formation loss function augments color reproduction and the use of gradient information produces sharper edges. Datasets, models and higher resolution images are available at https://ivi.fnwi.uva.nl/cv/retinet.