 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGNet: Intrinsic Image Decomposition by a Semantic and Invariant Gradient Driven Network for Indoor Scenes
Aug 30, 2022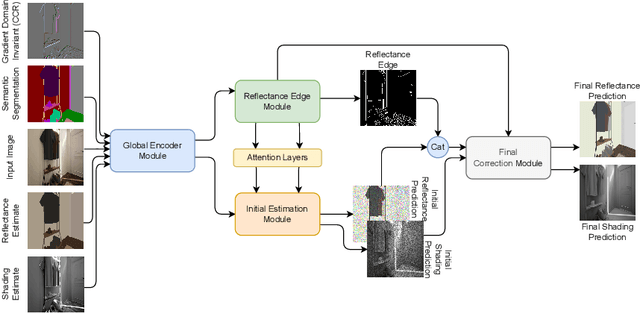
Intrinsic image decomposition (IID) is an under-constrained problem. Therefore, traditional approaches use hand crafted priors to constrain the problem. However, these constraints are limited when coping with complex scenes. Deep learning-based approaches learn these constraints implicitly through the data, but they often suffer from dataset biases (due to not being able to include all possible imaging conditions). In this paper, a combination of the two is proposed. Component specific priors like semantics and invariant features are exploited to obtain semantically and physically plausible reflectance transitions. These transitions are used to steer a progressive CNN with implicit homogeneity constraints to decompose reflectance and shading maps. An ablation study is conducted showing that the use of the proposed priors and progressive CNN increase the IID performance. State of the art performance on both our proposed dataset and the standard real-world IIW dataset shows the effectiveness of the proposed method. Code is made available at https://github.com/Morpheus3000/SIGNet
PIE-Net: Photometric Invariant Edge Guided Network for Intrinsic Image Decomposition
Mar 30, 2022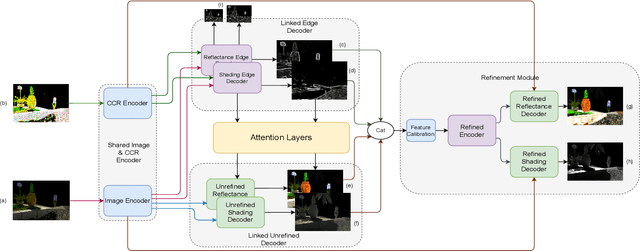
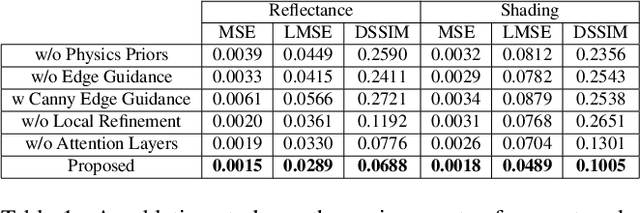

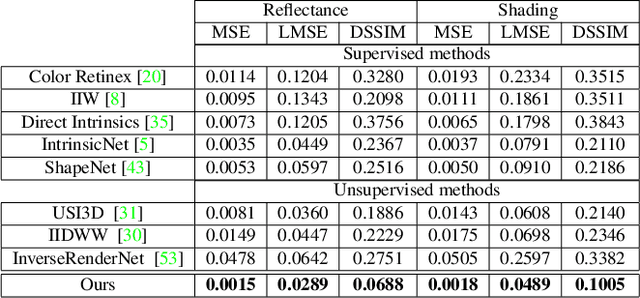
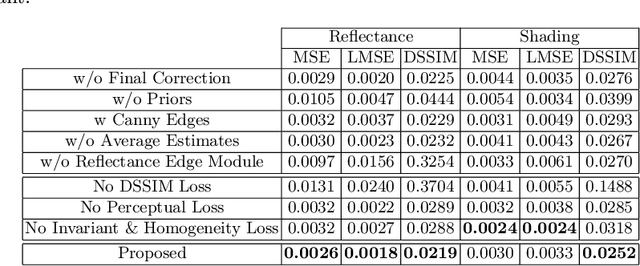
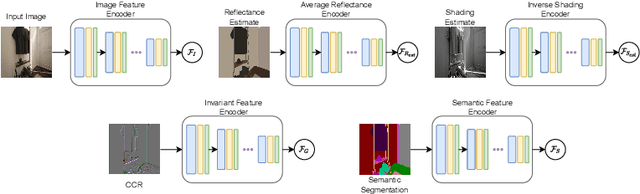
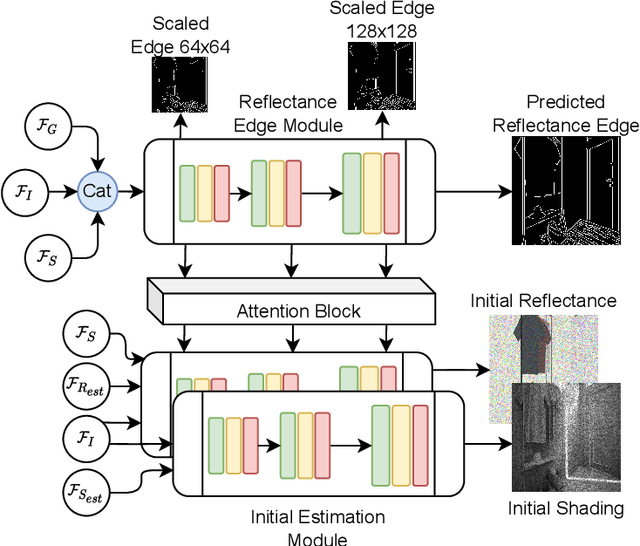
Intrinsic image decomposition is the process of recovering the image formation components (reflectance and shading) from an image. Previous methods employ either explicit priors to constrain the problem or implicit constraints as formulated by their losses (deep learning). These methods can be negatively influenced by strong illumination conditions causing shading-reflectance leakages. Therefore, in this paper, an end-to-end edge-driven hybrid CNN approach is proposed for intrinsic image decomposition. Edges correspond to illumination invariant gradients. To handle hard negative illumination transitions, a hierarchical approach is taken including global and local refinement layers. We make use of attention layers to further strengthen the learning process. An extensive ablation study and large scale experiments are conducted showing that it is beneficial for edge-driven hybrid IID networks to make use of illumination invariant descriptors and that separating global and local cues helps in improving the performance of the network. Finally, it is shown that the proposed method obtains state of the art performance and is able to generalise well to real world images. The project page with pretrained models, finetuned models and network code can be found at https://ivi.fnwi.uva.nl/cv/pienet/.
Generative Models for Multi-Illumination Color Constancy
Sep 02, 2021
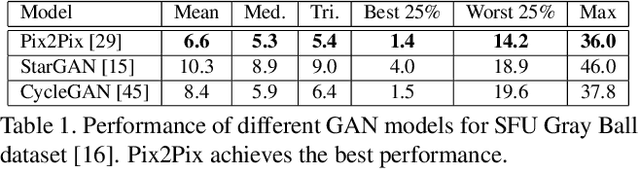
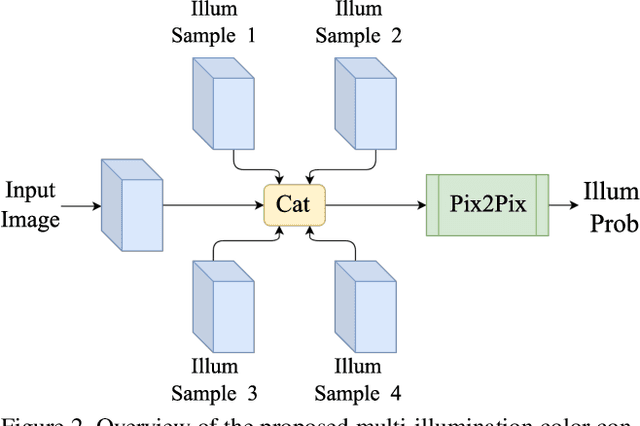
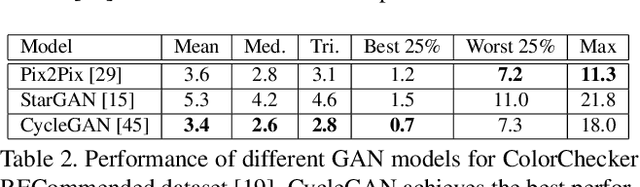
In this paper, the aim is multi-illumination color constancy. However, most of the existing color constancy methods are designed for single light sources. Furthermore, datasets for learning multiple illumination color constancy are largely missing. We propose a seed (physics driven) based multi-illumination color constancy method. GANs are exploited to model the illumination estimation problem as an image-to-image domain translation problem. Additionally, a novel multi-illumination data augmentation method is proposed. Experiments on single and multi-illumination datasets show that our methods outperform sota methods.
EDEN: Multimodal Synthetic Dataset of Enclosed GarDEN Scenes
Nov 10, 2020
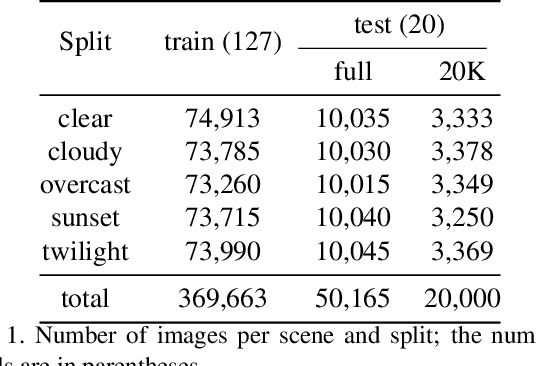

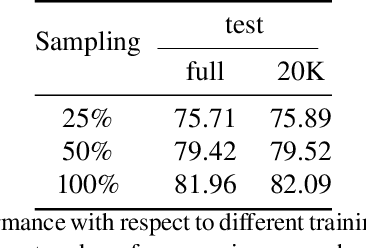
Multimodal large-scale datasets for outdoor scenes are mostly designed for urban driving problems. The scenes are highly structured and semantically different from scenarios seen in nature-centered scenes such as gardens or parks. To promote machine learning methods for nature-oriented applications, such as agriculture and gardening, we propose the multimodal synthetic dataset for Enclosed garDEN scenes (EDEN). The dataset features more than 300K images captured from more than 100 garden models. Each image is annotated with various low/high-level vision modalities, including semantic segmentation, depth, surface normals, intrinsic colors, and optical flow. Experimental results on the state-of-the-art methods for semantic segmentation and monocular depth prediction, two important tasks in computer vision, show positive impact of pre-training deep networks on our dataset for unstructured natural scenes. The dataset and related materials will be available at https://lhoangan.github.io/eden.
Novel View Synthesis from Single Images via Point Cloud Transformation
Sep 18, 2020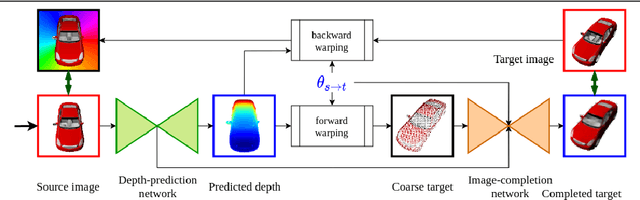

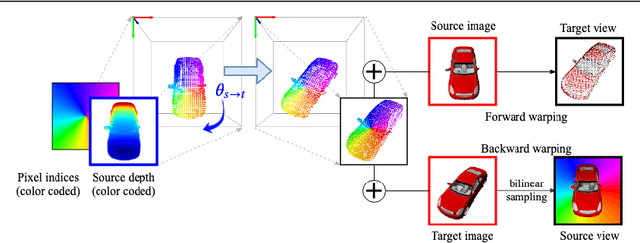
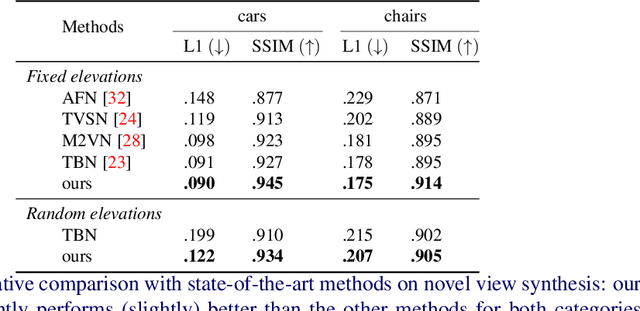
In this paper the argument is made that for true novel view synthesis of objects, where the object can be synthesized from any viewpoint, an explicit 3D shape representation isdesired. Our method estimates point clouds to capture the geometry of the object, which can be freely rotated into the desired view and then projected into a new image. This image, however, is sparse by nature and hence this coarse view is used as the input of an image completion network to obtain the dense target view. The point cloud is obtained using the predicted pixel-wise depth map, estimated from a single RGB input image,combined with the camera intrinsics. By using forward warping and backward warpingbetween the input view and the target view, the network can be trained end-to-end without supervision on depth. The benefit of using point clouds as an explicit 3D shape for novel view synthesis is experimentally validated on the 3D ShapeNet benchmark. Source code and data will be available at https://lhoangan.github.io/pc4novis/.
ShadingNet: Image Intrinsics by Fine-Grained Shading Decomposition
Dec 09, 2019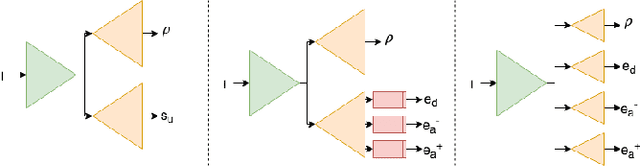



In general, intrinsic image decomposition algorithms interpret shading as one unified component including all photometric effects. As shading transitions are generally smoother than albedo changes, these methods may fail in distinguishing strong (cast) shadows from albedo variations. That in return may leak into albedo map predictions. Therefore, in this paper, we propose to decompose the shading component into direct (illumination) and indirect shading (ambient light and shadows). The aim is to distinguish strong cast shadows from reflectance variations. Two end-to-end supervised CNN models (ShadingNets) are proposed exploiting the fine-grained shading model. Furthermore, surface normal features are jointly learned by the proposed CNN networks. Surface normals are expected to assist the decomposition task. A large-scale dataset of scene-level synthetic images of outdoor natural environments is provided with intrinsic image ground-truths. Large scale experiments show that our CNN approach using fine-grained shading decomposition outperforms state-of-the-art methods using unified shading.
Color Constancy by GANs: An Experimental Survey
Dec 07, 2018
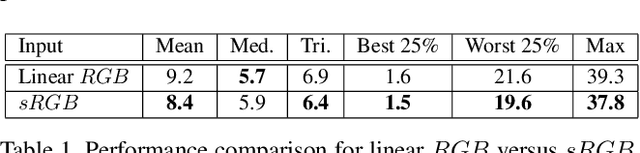
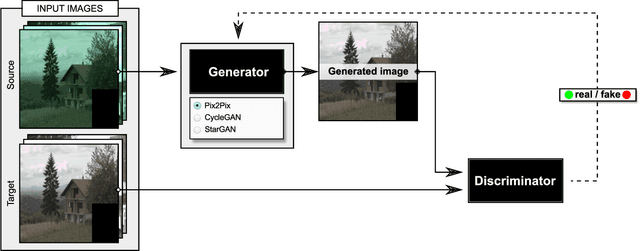
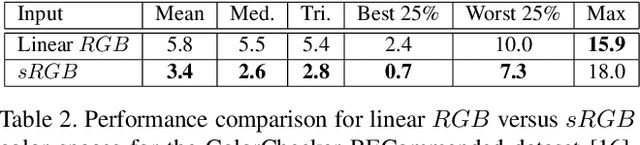
In this paper, we formulate the color constancy task as an image-to-image translation problem using GANs. By conducting a large set of experiments on different datasets, an experimental survey is provided on the use of different types of GANs to solve for color constancy i.e. CC-GANs (Color Constancy GANs). Based on the experimental review, recommendations are given for the design of CC-GAN architectures based on different criteria, circumstances and datasets.
Joint Learning of Intrinsic Images and Semantic Segmentation
Jul 31, 2018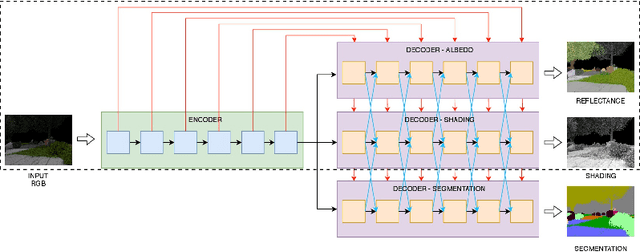
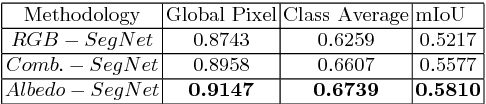
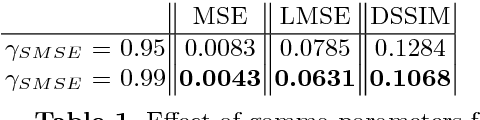

Semantic segmentation of outdoor scenes is problematic when there are variations in imaging conditions. It is known that albedo (reflectance) is invariant to all kinds of illumination effects. Thus, using reflectance images for semantic segmentation task can be favorable. Additionally, not only segmentation may benefit from reflectance, but also segmentation may be useful for reflectance computation. Therefore, in this paper, the tasks of semantic segmentation and intrinsic image decomposition are considered as a combined process by exploring their mutual relationship in a joint fashion. To that end, we propose a supervised end-to-end CNN architecture to jointly learn intrinsic image decomposition and semantic segmentation. We analyze the gains of addressing those two problems jointly. Moreover, new cascade CNN architectures for intrinsic-for-segmentation and segmentation-for-intrinsic are proposed as single tasks. Furthermore, a dataset of 35K synthetic images of natural environments is created with corresponding albedo and shading (intrinsics), as well as semantic labels (segmentation) assigned to each object/scene. The experiments show that joint learning of intrinsic image decomposition and semantic segmentation is beneficial for both tasks for natural scenes. Dataset and models are available at: https://ivi.fnwi.uva.nl/cv/intrinseg