 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior to Segment: Foreground Cues for Novel Objects in Partially Supervised Instance Segmentation
Nov 23, 2020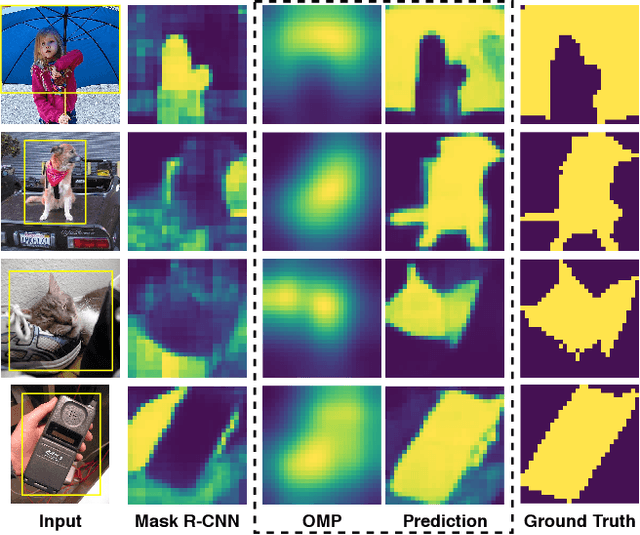

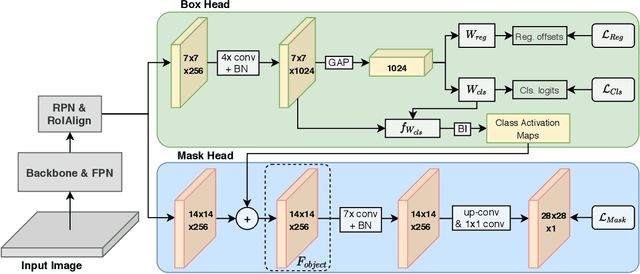

Instance segmentation methods require large datasets with expensive instance-level mask labels. This makes partially supervised learning appealing in settings where abundant box and limited mask labels are available. To improve mask predictions with limited labels, we modify a Mask R-CNN by introducing an object mask prior (OMP) for the mask head. We show that a conventional class-agnostic mask head has difficulties learning foreground for classes with box-supervision only. Our OMP resolves this by providing the mask head with the general concept of foreground implicitly learned by the box classification head under the supervision of all classes. This helps the class-agnostic mask head to focus on the primary object in a region of interest (RoI) and improves generalization to novel classes. We test our approach on the COCO dataset using different splits of strongly and weakly supervised classes. Our approach significantly improves over the Mask R-CNN baseline and obtains competitive performance with the state-of-the-art, while offering a much simpler architecture.
Solving Visual Object Ambiguities when Pointing: An Unsupervised Learning Approach
Dec 13, 2019
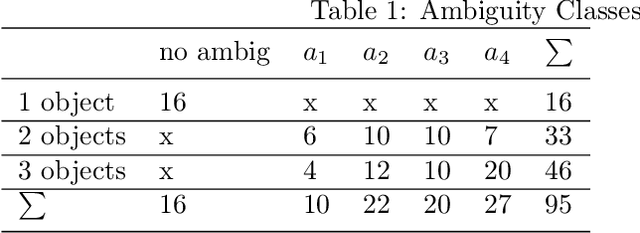
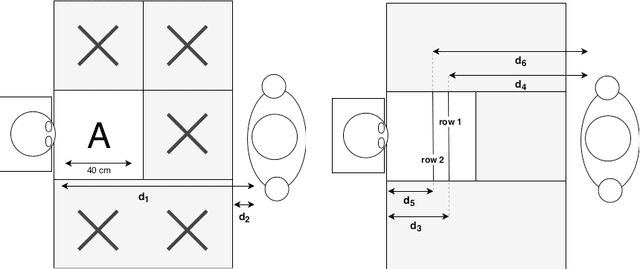
Whenever we are addressing a specific object or refer to a certain spatial location, we are using referential or deictic gestures usually accompanied by some verbal description. Especially pointing gestures are necessary to dissolve ambiguities in a scene and they are of crucial importance when verbal communication may fail due to environmental conditions or when two persons simply do not speak the same language. With the currently increasing advances of humanoid robots and their future integration in domestic domains, the development of gesture interfaces complementing human-robot interaction scenarios is of substantial interest. The implementation of an intuitive gesture scenario is still challenging because both the pointing intention and the corresponding object have to be correctly recognized in real-time. The demand increases when considering pointing gestures in a cluttered environment, as is the case in households. Also, humans perform pointing in many different ways and those variations have to be captured. Research in this field often proposes a set of geometrical computations which do not scale well with the number of gestures and objects, use specific markers or a predefined set of pointing directions. In this paper, we propose an unsupervised learning approach to model the distribution of pointing gestures using a growing-when-required (GWR) network. We introduce an interaction scenario with a humanoid robot and define so-called ambiguity classes. Our implementation for the hand and object detection is independent of any markers or skeleton models, thus it can be easily reproduced. Our evaluation comparing a baseline computer vision approach with our GWR model shows that the pointing-object association is well learned even in cases of ambiguities resulting from close object proximity.