 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnited We Learn Better: Harvesting Learning Improvements From Class Hierarchies Across Tasks
Jul 28, 2021



Attempts of learning from hierarchical taxonomies in computer vision have been mostly focusing on image classification. Though ways of best harvesting learning improvements from hierarchies in classification are far from being solved, there is a need to target these problems in other vision tasks such as object detection. As progress on the classification side is often dependent on hierarchical cross-entropy losses, novel detection architectures using sigmoid as an output function instead of softmax cannot easily apply these advances, requiring novel methods in detection. In this work we establish a theoretical framework based on probability and set theory for extracting parent predictions and a hierarchical loss that can be used across tasks, showing results across classification and detection benchmarks and opening up the possibility of hierarchical learning for sigmoid-based detection architectures.
Prior to Segment: Foreground Cues for Novel Objects in Partially Supervised Instance Segmentation
Nov 23, 2020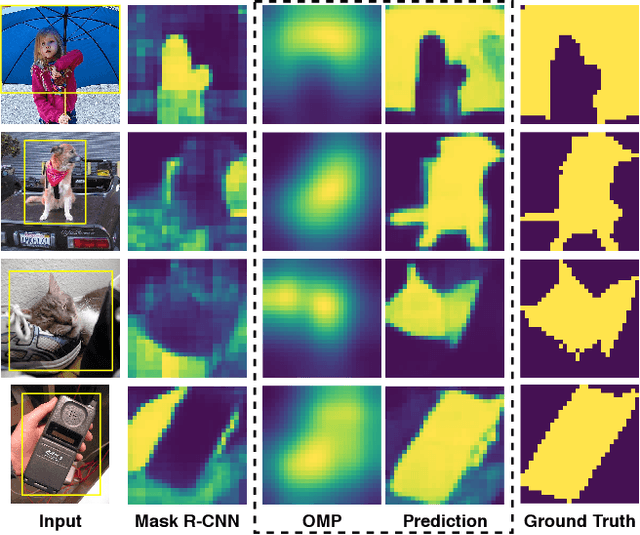

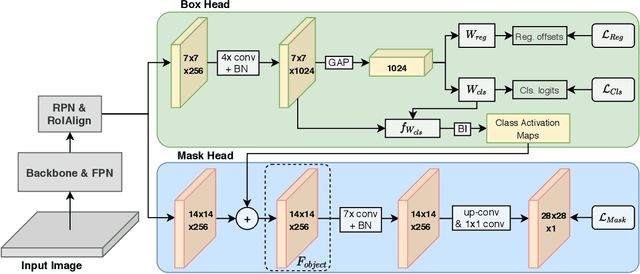

Instance segmentation methods require large datasets with expensive instance-level mask labels. This makes partially supervised learning appealing in settings where abundant box and limited mask labels are available. To improve mask predictions with limited labels, we modify a Mask R-CNN by introducing an object mask prior (OMP) for the mask head. We show that a conventional class-agnostic mask head has difficulties learning foreground for classes with box-supervision only. Our OMP resolves this by providing the mask head with the general concept of foreground implicitly learned by the box classification head under the supervision of all classes. This helps the class-agnostic mask head to focus on the primary object in a region of interest (RoI) and improves generalization to novel classes. We test our approach on the COCO dataset using different splits of strongly and weakly supervised classes. Our approach significantly improves over the Mask R-CNN baseline and obtains competitive performance with the state-of-the-art, while offering a much simpler architecture.
EL-GAN: Embedding Loss Driven Generative Adversarial Networks for Lane Detection
Jul 05, 2018
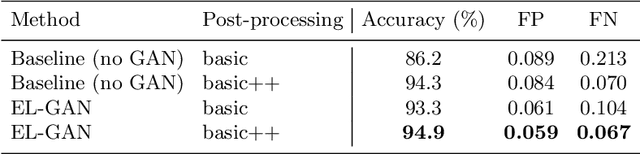
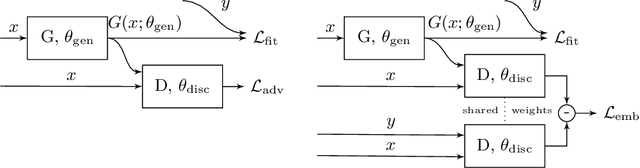
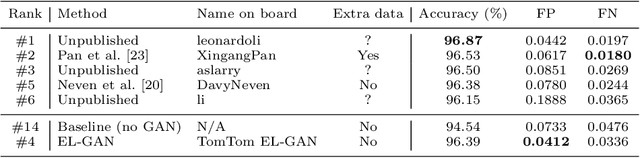
Convolutional neural networks have been successfully applied to semantic segmentation problems. However, there are many problems that are inherently not pixel-wise classification problems but are nevertheless frequently formulated as semantic segmentation. This ill-posed formulation consequently necessitates hand-crafted scenario-specific and computationally expensive post-processing methods to convert the per pixel probability maps to final desired outputs. Generative adversarial networks (GANs) can be used to make the semantic segmentation network output to be more realistic or better structure-preserving, decreasing the dependency on potentially complex post-processing. In this work, we propose EL-GAN: a GAN framework to mitigate the discussed problem using an embedding loss. With EL-GAN, we discriminate based on learned embeddings of both the labels and the prediction at the same time. This results in more stable training due to having better discriminative information, benefiting from seeing both `fake' and `real' predictions at the same time. This substantially stabilizes the adversarial training process. We use the TuSimple lane marking challenge to demonstrate that with our proposed framework it is viable to overcome the inherent anomalies of posing it as a semantic segmentation problem. Not only is the output considerably more similar to the labels when compared to conventional methods, the subsequent post-processing is also simpler and crosses the competitive 96% accuracy threshold.