 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Adversarial Refinement for Multimodal Semantic Segmentation
Jun 23, 2020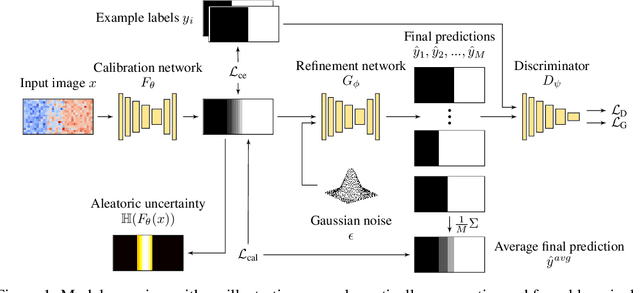
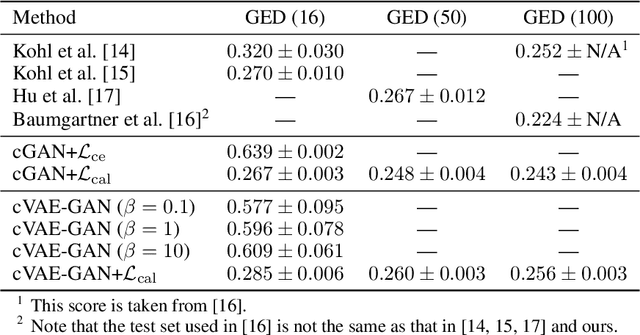
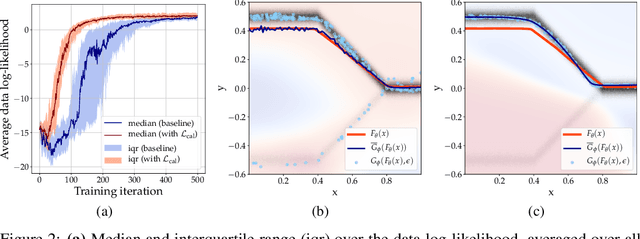
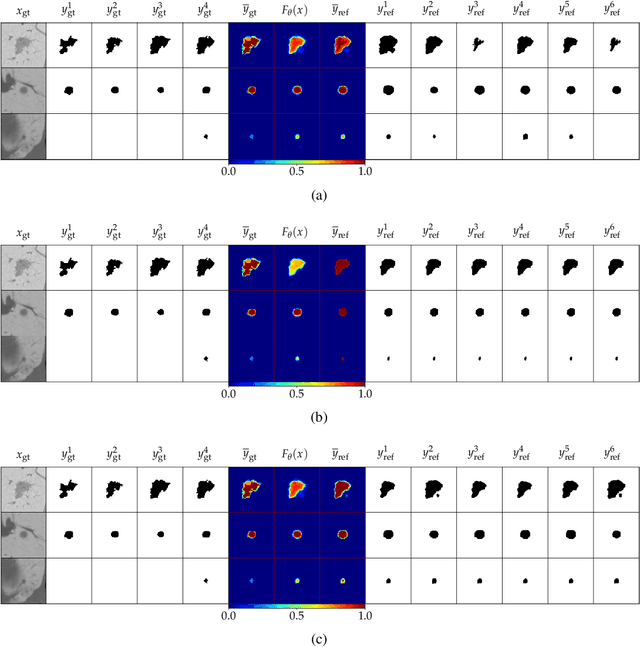
Ambiguities in images or unsystematic annotation can lead to multiple valid solutions in semantic segmentation. To learn a distribution over predictions, recent work has explored the use of probabilistic networks. However, these do not necessarily capture the empirical distribution accurately. In this work, we aim to learn a calibrated multimodal predictive distribution, where the empirical frequency of the sampled predictions closely reflects that of the corresponding labels in the training set. To this end, we propose a novel two-stage, cascaded strategy for calibrated adversarial refinement. In the first stage, we explicitly model the data with a categorical likelihood. In the second, we train an adversarial network to sample from it an arbitrary number of coherent predictions. The model can be used independently or integrated into any black-box segmentation framework to enable the synthesis of diverse predictions. We demonstrate the utility and versatility of the approach by achieving competitive results on the multigrader LIDC dataset and a modified Cityscapes dataset. In addition, we use a toy regression dataset to show that our framework is not confined to semantic segmentation, and the core design can be adapted to other tasks requiring learning a calibrated predictive distribution.
EL-GAN: Embedding Loss Driven Generative Adversarial Networks for Lane Detection
Jul 05, 2018
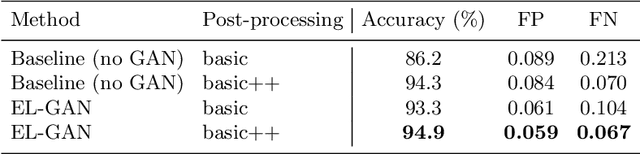
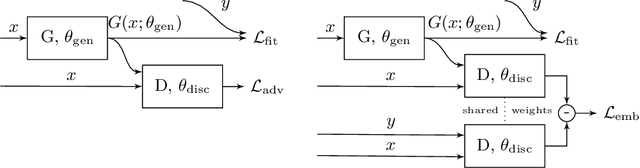
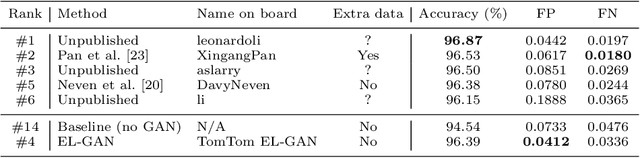
Convolutional neural networks have been successfully applied to semantic segmentation problems. However, there are many problems that are inherently not pixel-wise classification problems but are nevertheless frequently formulated as semantic segmentation. This ill-posed formulation consequently necessitates hand-crafted scenario-specific and computationally expensive post-processing methods to convert the per pixel probability maps to final desired outputs. Generative adversarial networks (GANs) can be used to make the semantic segmentation network output to be more realistic or better structure-preserving, decreasing the dependency on potentially complex post-processing. In this work, we propose EL-GAN: a GAN framework to mitigate the discussed problem using an embedding loss. With EL-GAN, we discriminate based on learned embeddings of both the labels and the prediction at the same time. This results in more stable training due to having better discriminative information, benefiting from seeing both `fake' and `real' predictions at the same time. This substantially stabilizes the adversarial training process. We use the TuSimple lane marking challenge to demonstrate that with our proposed framework it is viable to overcome the inherent anomalies of posing it as a semantic segmentation problem. Not only is the output considerably more similar to the labels when compared to conventional methods, the subsequent post-processing is also simpler and crosses the competitive 96% accuracy threshold.
CLBlast: A Tuned OpenCL BLAS Library
Apr 27, 2018

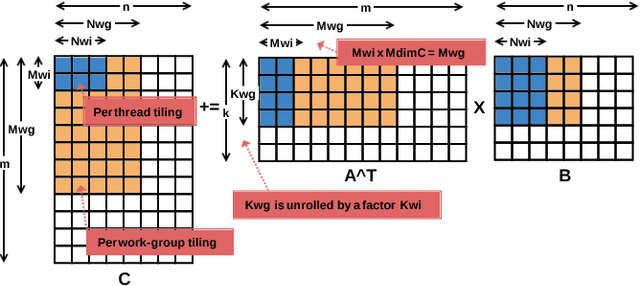

This work introduces CLBlast, an open-source BLAS library providing optimized OpenCL routines to accelerate dense linear algebra for a wide variety of devices. It is targeted at machine learning and HPC applications and thus provides a fast matrix-multiplication routine (GEMM) to accelerate the core of many applications (e.g. deep learning, iterative solvers, astrophysics, computational fluid dynamics, quantum chemistry). CLBlast has five main advantages over other OpenCL BLAS libraries: 1) it is optimized for and tested on a large variety of OpenCL devices including less commonly used devices such as embedded and low-power GPUs, 2) it can be explicitly tuned for specific problem-sizes on specific hardware platforms, 3) it can perform operations in half-precision floating-point FP16 saving bandwidth, time and energy, 4) it has an optional CUDA back-end, 5) and it can combine multiple operations in a single batched routine, accelerating smaller problems significantly. This paper describes the library and demonstrates the advantages of CLBlast experimentally for different use-cases on a wide variety of OpenCL hardware.
CLTune: A Generic Auto-Tuner for OpenCL Kernels
Mar 19, 2017
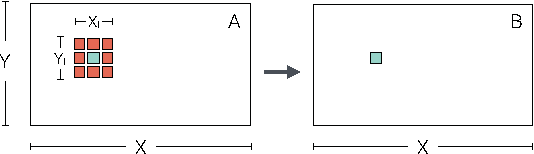
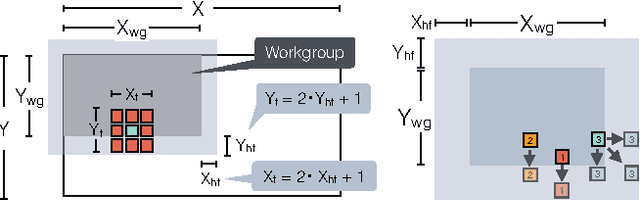

This work presents CLTune, an auto-tuner for OpenCL kernels. It evaluates and tunes kernel performance of a generic, user-defined search space of possible parameter-value combinations. Example parameters include the OpenCL workgroup size, vector data-types, tile sizes, and loop unrolling factors. CLTune can be used in the following scenarios: 1) when there are too many tunable parameters to explore manually, 2) when performance portability across OpenCL devices is desired, or 3) when the optimal parameters change based on input argument values (e.g. matrix dimensions). The auto-tuner is generic, easy to use, open-source, and supports multiple search strategies including simulated annealing and particle swarm optimisation. CLTune is evaluated on two GPU case-studies inspired by the recent successes in deep learning: 2D convolution and matrix-multiplication (GEMM). For 2D convolution, we demonstrate the need for auto-tuning by optimizing for different filter sizes, achieving performance on-par or better than the state-of-the-art. For matrix-multiplication, we use CLTune to explore a parameter space of more than two-hundred thousand configurations, we show the need for device-specific tuning, and outperform the clBLAS library on NVIDIA, AMD and Intel GPUs.