 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLBlast: A Tuned OpenCL BLAS Library
Paper and Code


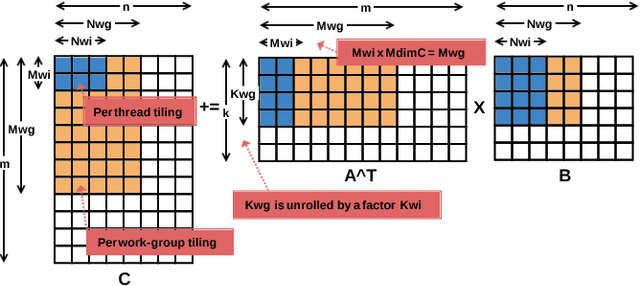

This work introduces CLBlast, an open-source BLAS library providing optimized OpenCL routines to accelerate dense linear algebra for a wide variety of devices. It is targeted at machine learning and HPC applications and thus provides a fast matrix-multiplication routine (GEMM) to accelerate the core of many applications (e.g. deep learning, iterative solvers, astrophysics, computational fluid dynamics, quantum chemistry). CLBlast has five main advantages over other OpenCL BLAS libraries: 1) it is optimized for and tested on a large variety of OpenCL devices including less commonly used devices such as embedded and low-power GPUs, 2) it can be explicitly tuned for specific problem-sizes on specific hardware platforms, 3) it can perform operations in half-precision floating-point FP16 saving bandwidth, time and energy, 4) it has an optional CUDA back-end, 5) and it can combine multiple operations in a single batched routine, accelerating smaller problems significantly. This paper describes the library and demonstrates the advantages of CLBlast experimentally for different use-cases on a wide variety of OpenCL hardware.