 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Cross-View Metric Localization with Dense Uncertainty Estimates
Aug 17, 2022

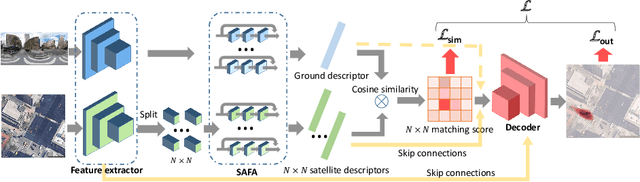
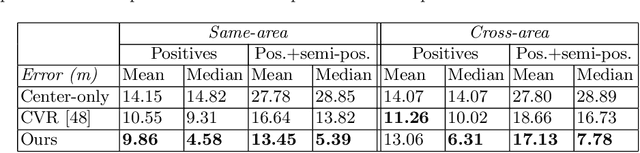
This work addresses visual cross-view metric localization for outdoor robotics. Given a ground-level color image and a satellite patch that contains the local surroundings, the task is to identify the location of the ground camera within the satellite patch. Related work addressed this task for range-sensors (LiDAR, Radar), but for vision, only as a secondary regression step after an initial cross-view image retrieval step. Since the local satellite patch could also be retrieved through any rough localization prior (e.g. from GPS/GNSS, temporal filtering), we drop the image retrieval objective and focus on the metric localization only. We devise a novel network architecture with denser satellite descriptors, similarity matching at the bottleneck (rather than at the output as in image retrieval), and a dense spatial distribution as output to capture multi-modal localization ambiguities. We compare against a state-of-the-art regression baseline that uses global image descriptors. Quantitative and qualitative experimental results on the recently proposed VIGOR and the Oxford RobotCar datasets validate our design. The produced probabilities are correlated with localization accuracy, and can even be used to roughly estimate the ground camera's heading when its orientation is unknown. Overall, our method reduces the median metric localization error by 51%, 37%, and 28% compared to the state-of-the-art when generalizing respectively in the same area, across areas, and across time.
United We Learn Better: Harvesting Learning Improvements From Class Hierarchies Across Tasks
Jul 28, 2021



Attempts of learning from hierarchical taxonomies in computer vision have been mostly focusing on image classification. Though ways of best harvesting learning improvements from hierarchies in classification are far from being solved, there is a need to target these problems in other vision tasks such as object detection. As progress on the classification side is often dependent on hierarchical cross-entropy losses, novel detection architectures using sigmoid as an output function instead of softmax cannot easily apply these advances, requiring novel methods in detection. In this work we establish a theoretical framework based on probability and set theory for extracting parent predictions and a hierarchical loss that can be used across tasks, showing results across classification and detection benchmarks and opening up the possibility of hierarchical learning for sigmoid-based detection architectures.
Shift Equivariance in Object Detection
Aug 13, 2020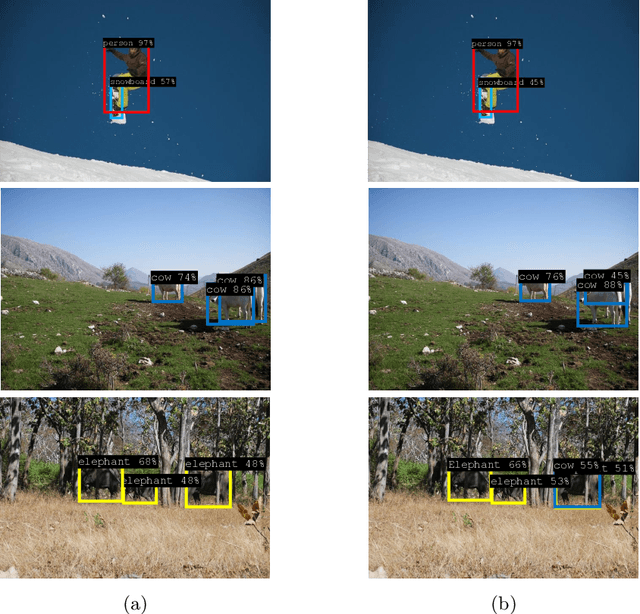


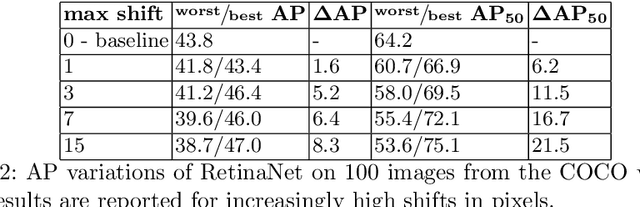
Robustness to small image translations is a highly desirable property for object detectors. However, recent works have shown that CNN-based classifiers are not shift invariant. It is unclear to what extent this could impact object detection, mainly because of the architectural differences between the two and the dimensionality of the prediction space of modern detectors. To assess shift equivariance of object detection models end-to-end, in this paper we propose an evaluation metric, built upon a greedy search of the lower and upper bounds of the mean average precision on a shifted image set. Our new metric shows that modern object detection architectures, no matter if one-stage or two-stage, anchor-based or anchor-free, are sensitive to even one pixel shift to the input images. Furthermore, we investigate several possible solutions to this problem, both taken from the literature and newly proposed, quantifying the effectiveness of each one with the suggested metric. Our results indicate that none of these methods can provide full shift equivariance. Measuring and analyzing the extent of shift variance of different models and the contributions of possible factors, is a first step towards being able to devise methods that mitigate or even leverage such variabilities.