 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthio-ASR: Joint Multilingual Speech Recognition and Language Identification for Ethiopian Languages
Mar 24, 2026We present Ethio-ASR, a suite of multilingual CTC-based automatic speech recognition (ASR) models jointly trained on five Ethiopian languages: Amharic, Tigrinya, Oromo, Sidaama, and Wolaytta. These languages belong to the Semitic, Cushitic, and Omotic branches of the Afroasiatic family, and remain severely underrepresented in speech technology despite being spoken by the vast majority of Ethiopia's population. We train our models on the recently released WAXAL corpus using several pre-trained speech encoders and evaluate against strong multilingual baselines, including OmniASR. Our best model achieves an average WER of 30.48% on the WAXAL test set, outperforming the best OmniASR model with substantially fewer parameters. We further provide a comprehensive analysis of gender bias, the contribution of vowel length and consonant gemination to ASR errors, and the training dynamics of multilingual CTC models. Our models and codebase are publicly available to the research community.
BinauralFlow: A Causal and Streamable Approach for High-Quality Binaural Speech Synthesis with Flow Matching Models
May 28, 2025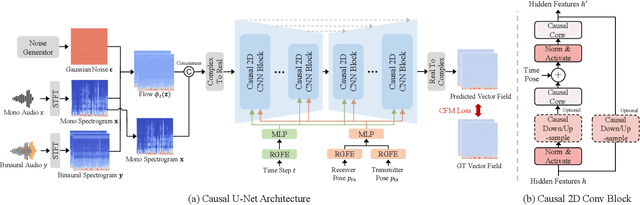
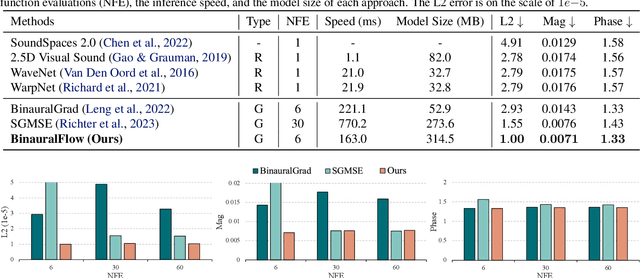
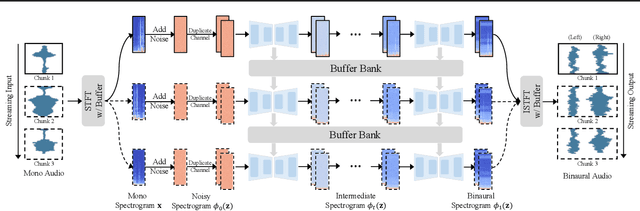
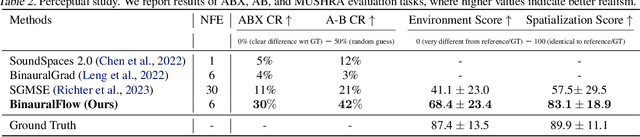
Binaural rendering aims to synthesize binaural audio that mimics natural hearing based on a mono audio and the locations of the speaker and listener. Although many methods have been proposed to solve this problem, they struggle with rendering quality and streamable inference. Synthesizing high-quality binaural audio that is indistinguishable from real-world recordings requires precise modeling of binaural cues, room reverb, and ambient sounds. Additionally, real-world applications demand streaming inference. To address these challenges, we propose a flow matching based streaming binaural speech synthesis framework called BinauralFlow. We consider binaural rendering to be a generation problem rather than a regression problem and design a conditional flow matching model to render high-quality audio. Moreover, we design a causal U-Net architecture that estimates the current audio frame solely based on past information to tailor generative models for streaming inference. Finally, we introduce a continuous inference pipeline incorporating streaming STFT/ISTFT operations, a buffer bank, a midpoint solver, and an early skip schedule to improve rendering continuity and speed. Quantitative and qualitative evaluations demonstrate the superiority of our method over SOTA approaches. A perceptual study further reveals that our model is nearly indistinguishable from real-world recordings, with a $42\%$ confusion rate.
SoundVista: Novel-View Ambient Sound Synthesis via Visual-Acoustic Binding
Apr 08, 2025



We introduce SoundVista, a method to generate the ambient sound of an arbitrary scene at novel viewpoints. Given a pre-acquired recording of the scene from sparsely distributed microphones, SoundVista can synthesize the sound of that scene from an unseen target viewpoint. The method learns the underlying acoustic transfer function that relates the signals acquired at the distributed microphones to the signal at the target viewpoint, using a limited number of known recordings. Unlike existing works, our method does not require constraints or prior knowledge of sound source details. Moreover, our method efficiently adapts to diverse room layouts, reference microphone configurations and unseen environments. To enable this, we introduce a visual-acoustic binding module that learns visual embeddings linked with local acoustic properties from panoramic RGB and depth data. We first leverage these embeddings to optimize the placement of reference microphones in any given scene. During synthesis, we leverage multiple embeddings extracted from reference locations to get adaptive weights for their contribution, conditioned on target viewpoint. We benchmark the task on both publicly available data and real-world settings. We demonstrate significant improvements over existing methods.
ComplexDec: A Domain-robust High-fidelity Neural Audio Codec with Complex Spectrum Modeling
Feb 04, 2025



Neural audio codecs have been widely adopted in audio-generative tasks because their compact and discrete representations are suitable for both large-language-model-style and regression-based generative models. However, most neural codecs struggle to model out-of-domain audio, resulting in error propagations to downstream generative tasks. In this paper, we first argue that information loss from codec compression degrades out-of-domain robustness. Then, we propose full-band 48~kHz ComplexDec with complex spectral input and output to ease the information loss while adopting the same 24~kbps bitrate as the baseline AuidoDec and ScoreDec. Objective and subjective evaluations demonstrate the out-of-domain robustness of ComplexDec trained using only the 30-hour VCTK corpus.
Real Acoustic Fields: An Audio-Visual Room Acoustics Dataset and Benchmark
Mar 27, 2024We present a new dataset called Real Acoustic Fields (RAF) that captures real acoustic room data from multiple modalities. The dataset includes high-quality and densely captured room impulse response data paired with multi-view images, and precise 6DoF pose tracking data for sound emitters and listeners in the rooms. We used this dataset to evaluate existing methods for novel-view acoustic synthesis and impulse response generation which previously relied on synthetic data. In our evaluation, we thoroughly assessed existing audio and audio-visual models against multiple criteria and proposed settings to enhance their performance on real-world data. We also conducted experiments to investigate the impact of incorporating visual data (i.e., images and depth) into neural acoustic field models. Additionally, we demonstrated the effectiveness of a simple sim2real approach, where a model is pre-trained with simulated data and fine-tuned with sparse real-world data, resulting in significant improvements in the few-shot learning approach. RAF is the first dataset to provide densely captured room acoustic data, making it an ideal resource for researchers working on audio and audio-visual neural acoustic field modeling techniques. Demos and datasets are available on our project page: https://facebookresearch.github.io/real-acoustic-fields/
ScoreDec: A Phase-preserving High-Fidelity Audio Codec with A Generalized Score-based Diffusion Post-filter
Jan 22, 2024Although recent mainstream waveform-domain end-to-end (E2E) neural audio codecs achieve impressive coded audio quality with a very low bitrate, the quality gap between the coded and natural audio is still significant. A generative adversarial network (GAN) training is usually required for these E2E neural codecs because of the difficulty of direct phase modeling. However, such adversarial learning hinders these codecs from preserving the original phase information. To achieve human-level naturalness with a reasonable bitrate, preserve the original phase, and get rid of the tricky and opaque GAN training, we develop a score-based diffusion post-filter (SPF) in the complex spectral domain and combine our previous AudioDec with the SPF to propose ScoreDec, which can be trained using only spectral and score-matching losses. Both the objective and subjective experimental results show that ScoreDec with a 24~kbps bitrate encodes and decodes full-band 48~kHz speech with human-level naturalness and well-preserved phase information.
AudioDec: An Open-source Streaming High-fidelity Neural Audio Codec
May 26, 2023



A good audio codec for live applications such as telecommunication is characterized by three key properties: (1) compression, i.e.\ the bitrate that is required to transmit the signal should be as low as possible; (2) latency, i.e.\ encoding and decoding the signal needs to be fast enough to enable communication without or with only minimal noticeable delay; and (3) reconstruction quality of the signal. In this work, we propose an open-source, streamable, and real-time neural audio codec that achieves strong performance along all three axes: it can reconstruct highly natural sounding 48~kHz speech signals while operating at only 12~kbps and running with less than 6~ms (GPU)/10~ms (CPU) latency. An efficient training paradigm is also demonstrated for developing such neural audio codecs for real-world scenarios. Both objective and subjective evaluations using the VCTK corpus are provided. To sum up, AudioDec is a well-developed plug-and-play benchmark for audio codec applications.
SAQAM: Spatial Audio Quality Assessment Metric
Jun 24, 2022



Audio quality assessment is critical for assessing the perceptual realism of sounds. However, the time and expense of obtaining ''gold standard'' human judgments limit the availability of such data. For AR&VR, good perceived sound quality and localizability of sources are among the key elements to ensure complete immersion of the user. Our work introduces SAQAM which uses a multi-task learning framework to assess listening quality (LQ) and spatialization quality (SQ) between any given pair of binaural signals without using any subjective data. We model LQ by training on a simulated dataset of triplet human judgments, and SQ by utilizing activation-level distances from networks trained for direction of arrival (DOA) estimation. We show that SAQAM correlates well with human responses across four diverse datasets. Since it is a deep network, the metric is differentiable, making it suitable as a loss function for other tasks. For example, simply replacing an existing loss with our metric yields improvement in a speech-enhancement network.
DPLM: A Deep Perceptual Spatial-Audio Localization Metric
May 29, 2021



Subjective evaluations are critical for assessing the perceptual realism of sounds in audio-synthesis driven technologies like augmented and virtual reality. However, they are challenging to set up, fatiguing for users, and expensive. In this work, we tackle the problem of capturing the perceptual characteristics of localizing sounds. Specifically, we propose a framework for building a general purpose quality metric to assess spatial localization differences between two binaural recordings. We model localization similarity by utilizing activation-level distances from deep networks trained for direction of arrival (DOA) estimation. Our proposed metric (DPLM) outperforms baseline metrics on correlation with subjective ratings on a diverse set of datasets, even without the benefit of any human-labeled training data.
Audio-Visual Speaker Diarization Based on Spatiotemporal Bayesian Fusion
Nov 03, 2016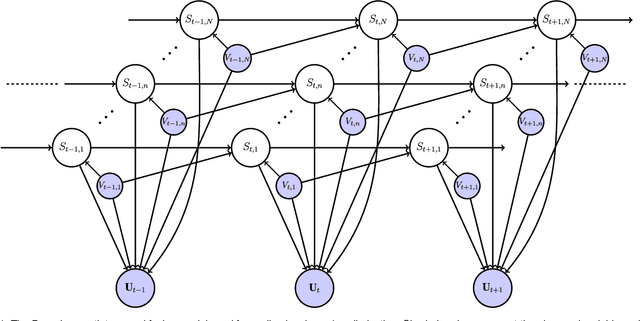
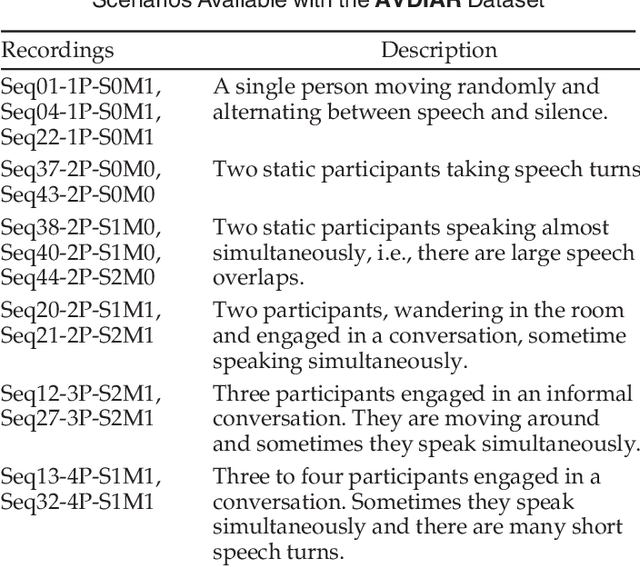
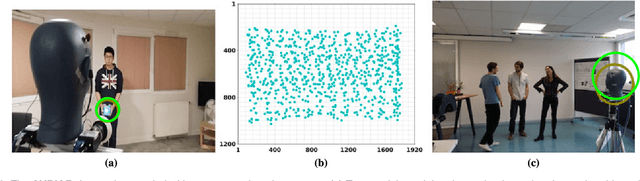
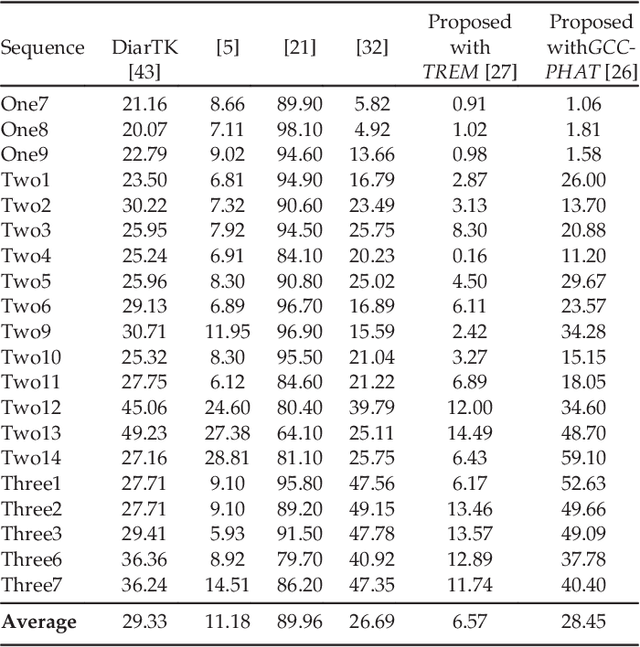
Speaker diarization consists of assigning speech signals to people engaged in a dialogue. An audio-visual spatiotemporal diarization model is proposed. The model is well suited for challenging scenarios that consist of several participants engaged in multi-party interaction while they move around and turn their heads towards the other participants rather than facing the cameras and the microphones. Multiple-person visual tracking is combined with multiple speech-source localization in order to tackle the speech-to-person association problem. The latter is solved within a novel audio-visual fusion method on the following grounds: binaural spectral features are first extracted from a microphone pair, then a supervised audio-visual alignment technique maps these features onto an image, and finally a semi-supervised clustering method assigns binaural spectral features to visible persons. The main advantage of this method over previous work is that it processes in a principled way speech signals uttered simultaneously by multiple persons. The diarization itself is cast into a latent-variable temporal graphical model that infers speaker identities and speech turns, based on the output of an audio-visual association process, executed at each time slice, and on the dynamics of the diarization variable itself. The proposed formulation yields an efficient exact inference procedure. A novel dataset, that contains audio-visual training data as well as a number of scenarios involving several participants engaged in formal and informal dialogue, is introduced. The proposed method is thoroughly tested and benchmarked with respect to several state-of-the art diarization algorithms.
* 14 pages, 6 figures, 5 tables