 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Speaker Diarization Based on Spatiotemporal Bayesian Fusion
Paper and Code
Nov 03, 2016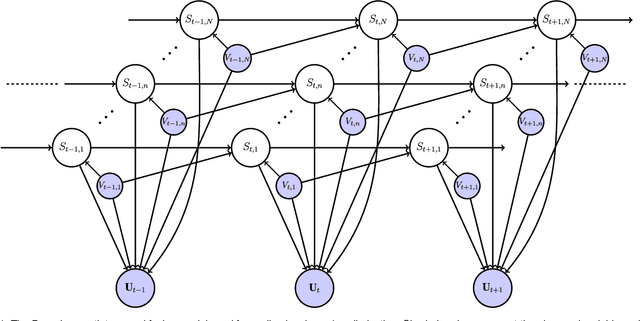
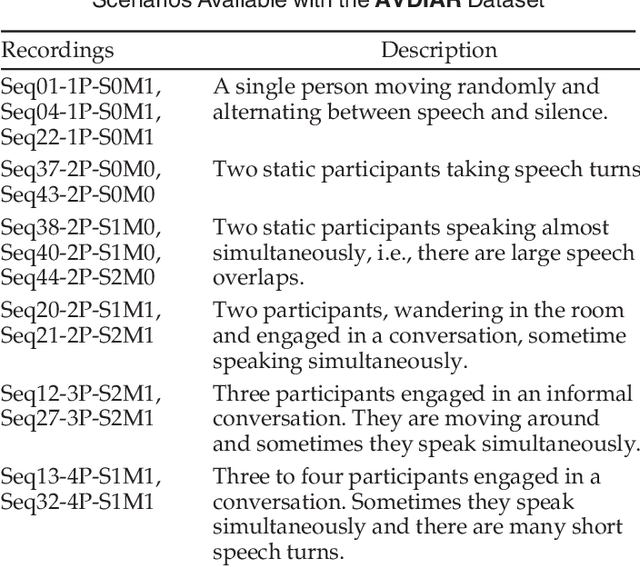
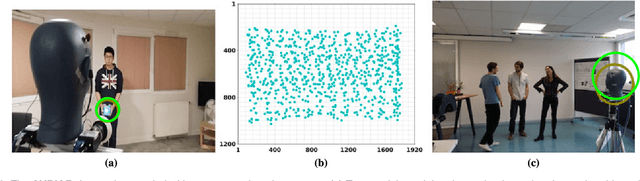
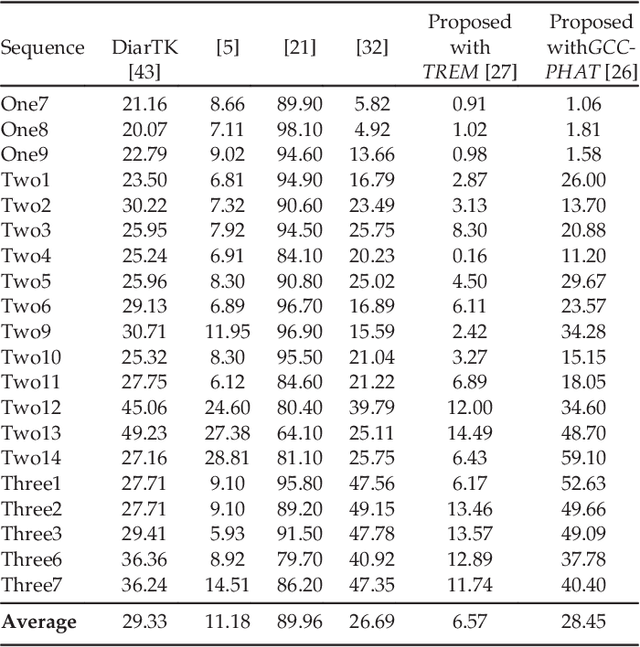
Speaker diarization consists of assigning speech signals to people engaged in a dialogue. An audio-visual spatiotemporal diarization model is proposed. The model is well suited for challenging scenarios that consist of several participants engaged in multi-party interaction while they move around and turn their heads towards the other participants rather than facing the cameras and the microphones. Multiple-person visual tracking is combined with multiple speech-source localization in order to tackle the speech-to-person association problem. The latter is solved within a novel audio-visual fusion method on the following grounds: binaural spectral features are first extracted from a microphone pair, then a supervised audio-visual alignment technique maps these features onto an image, and finally a semi-supervised clustering method assigns binaural spectral features to visible persons. The main advantage of this method over previous work is that it processes in a principled way speech signals uttered simultaneously by multiple persons. The diarization itself is cast into a latent-variable temporal graphical model that infers speaker identities and speech turns, based on the output of an audio-visual association process, executed at each time slice, and on the dynamics of the diarization variable itself. The proposed formulation yields an efficient exact inference procedure. A novel dataset, that contains audio-visual training data as well as a number of scenarios involving several participants engaged in formal and informal dialogue, is introduced. The proposed method is thoroughly tested and benchmarked with respect to several state-of-the art diarization algorithms.