 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of projected stochastic natural gradient variational inference for various step size and sample or batch size schedules
Apr 01, 2026Stochastic natural gradient variational inference (NGVI) is a popular and efficient algorithm for Bayesian inference. Despite empirical success, the convergence of this method is still not fully understood. In this work, we define and study a projected stochastic NGVI when variational distributions form an exponential family. Stochasticity arises when either gradients are intractable expectations or large sums. We prove new non-asymptotic convergence results for combinations of constant or decreasing step sizes and constant or increasing sample/batch sizes. When all hyperparameters are fixed, NGVI is shown to converge geometrically to a neighborhood of the optimum, while we establish convergence to the optimum with rates of the form $\mathcal{O}\left(\frac{1}{T^ρ} \right)$, possibly with $ρ\geq 1$, for all other combinations of step size and sample/batch size schedules. These rates apply when the target posterior distribution is close in some sense to the considered exponential family. Our theoretical results extend existing NGVI and stochastic optimization results and provide more flexibility to adjust, in a principled way, step sizes and sample/batch sizes in order to meet speed, resources, or accuracy constraints.
Revisiting Incremental Stochastic Majorization-Minimization Algorithms with Applications to Mixture of Experts
Jan 27, 2026Processing high-volume, streaming data is increasingly common in modern statistics and machine learning, where batch-mode algorithms are often impractical because they require repeated passes over the full dataset. This has motivated incremental stochastic estimation methods, including the incremental stochastic Expectation-Maximization (EM) algorithm formulated via stochastic approximation. In this work, we revisit and analyze an incremental stochastic variant of the Majorization-Minimization (MM) algorithm, which generalizes incremental stochastic EM as a special case. Our approach relaxes key EM requirements, such as explicit latent-variable representations, enabling broader applicability and greater algorithmic flexibility. We establish theoretical guarantees for the incremental stochastic MM algorithm, proving consistency in the sense that the iterates converge to a stationary point characterized by a vanishing gradient of the objective. We demonstrate these advantages on a softmax-gated mixture of experts (MoE) regression problem, for which no stochastic EM algorithm is available. Empirically, our method consistently outperforms widely used stochastic optimizers, including stochastic gradient descent, root mean square propagation, adaptive moment estimation, and second-order clipped stochastic optimization. These results support the development of new incremental stochastic algorithms, given the central role of softmax-gated MoE architectures in contemporary deep neural networks for heterogeneous data modeling. Beyond synthetic experiments, we also validate practical effectiveness on two real-world datasets, including a bioinformatics study of dent maize genotypes under drought stress that integrates high-dimensional proteomics with ecophysiological traits, where incremental stochastic MM yields stable gains in predictive performance.
Natural Variational Annealing for Multimodal Optimization
Jan 08, 2025We introduce a new multimodal optimization approach called Natural Variational Annealing (NVA) that combines the strengths of three foundational concepts to simultaneously search for multiple global and local modes of black-box nonconvex objectives. First, it implements a simultaneous search by using variational posteriors, such as, mixtures of Gaussians. Second, it applies annealing to gradually trade off exploration for exploitation. Finally, it learns the variational search distribution using natural-gradient learning where updates resemble well-known and easy-to-implement algorithms. The three concepts come together in NVA giving rise to new algorithms and also allowing us to incorporate "fitness shaping", a core concept from evolutionary algorithms. We assess the quality of search on simulations and compare them to methods using gradient descent and evolution strategies. We also provide an application to a real-world inverse problem in planetary science.
Dynamic Learning Rate for Deep Reinforcement Learning: A Bandit Approach
Oct 16, 2024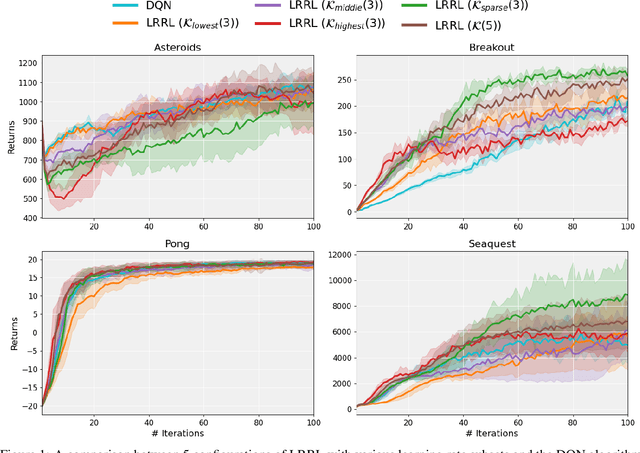

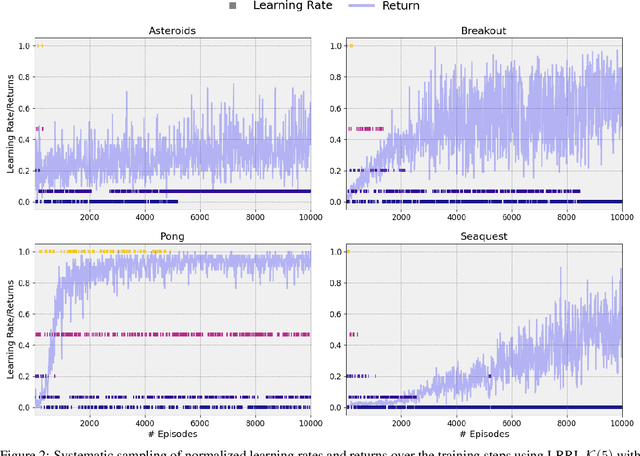

In Deep Reinforcement Learning models trained using gradient-based techniques, the choice of optimizer and its learning rate are crucial to achieving good performance: higher learning rates can prevent the model from learning effectively, while lower ones might slow convergence. Additionally, due to the non-stationarity of the objective function, the best-performing learning rate can change over the training steps. To adapt the learning rate, a standard technique consists of using decay schedulers. However, these schedulers assume that the model is progressively approaching convergence, which may not always be true, leading to delayed or premature adjustments. In this work, we propose dynamic Learning Rate for deep Reinforcement Learning (LRRL), a meta-learning approach that selects the learning rate based on the agent's performance during training. LRRL is based on a multi-armed bandit algorithm, where each arm represents a different learning rate, and the bandit feedback is provided by the cumulative returns of the RL policy to update the arms' probability distribution. Our empirical results demonstrate that LRRL can substantially improve the performance of deep RL algorithms.
Bayesian Experimental Design via Contrastive Diffusions
Oct 15, 2024Bayesian Optimal Experimental Design (BOED) is a powerful tool to reduce the cost of running a sequence of experiments. When based on the Expected Information Gain (EIG), design optimization corresponds to the maximization of some intractable expected {\it contrast} between prior and posterior distributions. Scaling this maximization to high dimensional and complex settings has been an issue due to BOED inherent computational complexity. In this work, we introduce an {\it expected posterior} distribution with cost-effective sampling properties and provide a tractable access to the EIG contrast maximization via a new EIG gradient expression. Diffusion-based samplers are used to compute the dynamics of the expected posterior and ideas from bi-level optimization are leveraged to derive an efficient joint sampling-optimization loop, without resorting to lower bound approximations of the EIG. The resulting efficiency gain allows to extend BOED to the well-tested generative capabilities of diffusion models. By incorporating generative models into the BOED framework, we expand its scope and its use in scenarios that were previously impractical. Numerical experiments and comparison with state-of-the-art methods show the potential of the approach.
Robust Conformal Volume Estimation in 3D Medical Images
Jul 29, 2024



Volumetry is one of the principal downstream applications of 3D medical image segmentation, for example, to detect abnormal tissue growth or for surgery planning. Conformal Prediction is a promising framework for uncertainty quantification, providing calibrated predictive intervals associated with automatic volume measurements. However, this methodology is based on the hypothesis that calibration and test samples are exchangeable, an assumption that is in practice often violated in medical image applications. A weighted formulation of Conformal Prediction can be framed to mitigate this issue, but its empirical investigation in the medical domain is still lacking. A potential reason is that it relies on the estimation of the density ratio between the calibration and test distributions, which is likely to be intractable in scenarios involving high-dimensional data. To circumvent this, we propose an efficient approach for density ratio estimation relying on the compressed latent representations generated by the segmentation model. Our experiments demonstrate the efficiency of our approach to reduce the coverage error in the presence of covariate shifts, in both synthetic and real-world settings. Our implementation is available at https://github.com/benolmbrt/wcp_miccai
Fast, accurate and lightweight sequential simulation-based inference using Gaussian locally linear mappings
Mar 16, 2024



Bayesian inference for complex models with an intractable likelihood can be tackled using algorithms performing many calls to computer simulators. These approaches are collectively known as "simulation-based inference" (SBI). Recent SBI methods have made use of neural networks (NN) to provide approximate, yet expressive constructs for the unavailable likelihood function and the posterior distribution. However, they do not generally achieve an optimal trade-off between accuracy and computational demand. In this work, we propose an alternative that provides both approximations to the likelihood and the posterior distribution, using structured mixtures of probability distributions. Our approach produces accurate posterior inference when compared to state-of-the-art NN-based SBI methods, while exhibiting a much smaller computational footprint. We illustrate our results on several benchmark models from the SBI literature.
PASOA- PArticle baSed Bayesian Optimal Adaptive design
Feb 11, 2024We propose a new procedure named PASOA, for Bayesian experimental design, that performs sequential design optimization by simultaneously providing accurate estimates of successive posterior distributions for parameter inference. The sequential design process is carried out via a contrastive estimation principle, using stochastic optimization and Sequential Monte Carlo (SMC) samplers to maximise the Expected Information Gain (EIG). As larger information gains are obtained for larger distances between successive posterior distributions, this EIG objective may worsen classical SMC performance. To handle this issue, tempering is proposed to have both a large information gain and an accurate SMC sampling, that we show is crucial for performance. This novel combination of stochastic optimization and tempered SMC allows to jointly handle design optimization and parameter inference. We provide a proof that the obtained optimal design estimators benefit from some consistency property. Numerical experiments confirm the potential of the approach, which outperforms other recent existing procedures.
Towards frugal unsupervised detection of subtle abnormalities in medical imaging
Sep 04, 2023Anomaly detection in medical imaging is a challenging task in contexts where abnormalities are not annotated. This problem can be addressed through unsupervised anomaly detection (UAD) methods, which identify features that do not match with a reference model of normal profiles. Artificial neural networks have been extensively used for UAD but they do not generally achieve an optimal trade-o$\hookleftarrow$ between accuracy and computational demand. As an alternative, we investigate mixtures of probability distributions whose versatility has been widely recognized for a variety of data and tasks, while not requiring excessive design e$\hookleftarrow$ort or tuning. Their expressivity makes them good candidates to account for complex multivariate reference models. Their much smaller number of parameters makes them more amenable to interpretation and e cient learning. However, standard estimation procedures, such as the Expectation-Maximization algorithm, do not scale well to large data volumes as they require high memory usage. To address this issue, we propose to incrementally compute inferential quantities. This online approach is illustrated on the challenging detection of subtle abnormalities in MR brain scans for the follow-up of newly diagnosed Parkinsonian patients. The identified structural abnormalities are consistent with the disease progression, as accounted by the Hoehn and Yahr scale.
Anisotropic Hybrid Networks for liver tumor segmentation with uncertainty quantification
Aug 23, 2023



The burden of liver tumors is important, ranking as the fourth leading cause of cancer mortality. In case of hepatocellular carcinoma (HCC), the delineation of liver and tumor on contrast-enhanced magnetic resonance imaging (CE-MRI) is performed to guide the treatment strategy. As this task is time-consuming, needs high expertise and could be subject to inter-observer variability there is a strong need for automatic tools. However, challenges arise from the lack of available training data, as well as the high variability in terms of image resolution and MRI sequence. In this work we propose to compare two different pipelines based on anisotropic models to obtain the segmentation of the liver and tumors. The first pipeline corresponds to a baseline multi-class model that performs the simultaneous segmentation of the liver and tumor classes. In the second approach, we train two distinct binary models, one segmenting the liver only and the other the tumors. Our results show that both pipelines exhibit different strengths and weaknesses. Moreover we propose an uncertainty quantification strategy allowing the identification of potential false positive tumor lesions. Both solutions were submitted to the MICCAI 2023 Atlas challenge regarding liver and tumor segmentation.