 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS-SEP: Joint Diarization and Separation Conditioned on Estimated Speaker Embeddings
Paper and Code
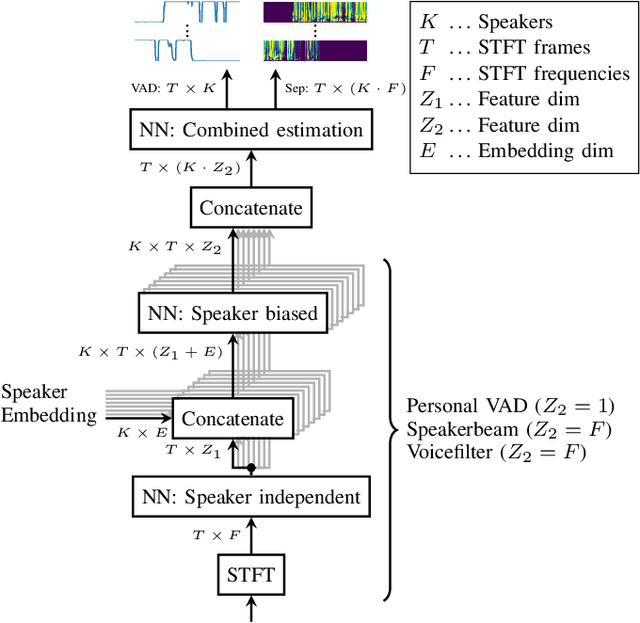
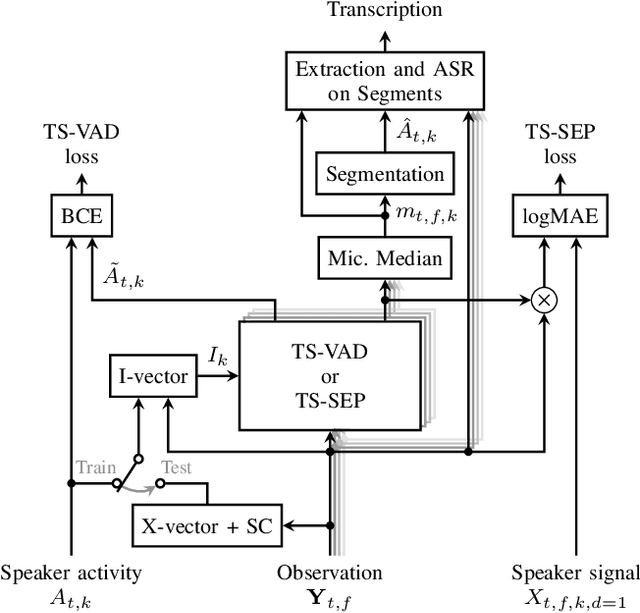
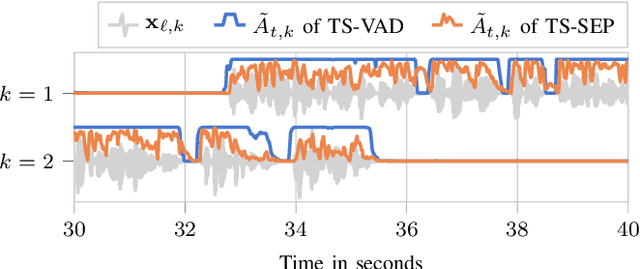
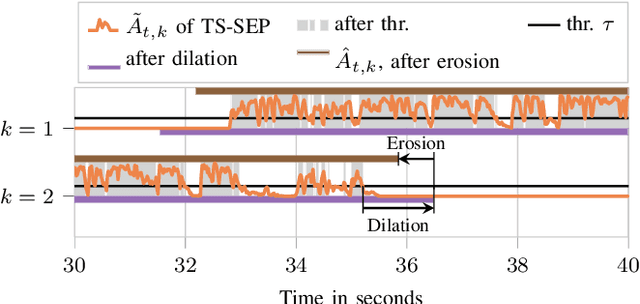
Since diarization and source separation of meeting data are closely related tasks, we here propose an approach to perform the two objectives jointly. It builds upon the target-speaker voice activity detection (TS-VAD) diarization approach, which assumes that initial speaker embeddings are available. We replace the final combined speaker activity estimation network of TS-VAD with a network that produces speaker activity estimates at a time-frequency resolution. Those act as masks for source extraction, either via masking or via beamforming. The technique can be applied both for single-channel and multi-channel input and, in both cases, achieves a new state-of-the-art word error rate (WER) on the LibriCSS meeting data recognition task. We further compute speaker-aware and speaker-agnostic WERs to isolate the contribution of diarization errors to the overall WER performance.